两种结构
历史学家本尼迪克特·安德森 ( Benedict Anderson)曾写道: “所有大于原始村庄的社区都可以想象得到……”。
从某种意义上说,类依赖关系和包依赖关系都可以想象得到。 他们不是真的在那里。 但是,我们在管理它们上花费了巨大的精力。 是什么促使我们努力应对幻觉怪物?
好吧,这个博客的主要假设是源代码结构是有钱的。 特别是,结构不良的软件会遭受连锁反应的严重影响,从而一处更改代码会触发许多其他地方的更改,所有这些都增加了可怕的更新成本。 此外,结构不良的软件非常复杂,以至于很难预测更新成本,因为这些涟漪效应到处都是。
例如,图1在左侧显示了一个良好的包装结构-明确的依赖关系使更新成本分析变得毫无问题-在右侧显示了一个包装结构的混乱。
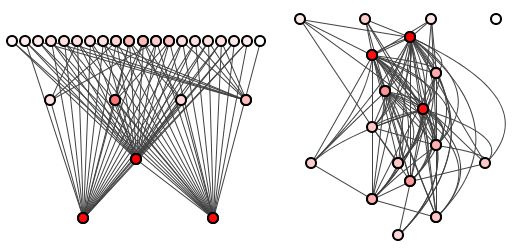
图1:两个系统,两个包装结构。
如果要检查这些样品的潜在波纹效应,则必须了解波纹效应如何从一个地方闪到另一个地方。 考虑如下的Java方法链,其中a()调用b() , b()调用c() ,等等:
private int a(int value) {
return b(value) * 2;
}
private int b(int value) {
return c(value) * 3;
}
private int c(int value) {
return d(value) * 5;
}
private int d(int value) {
int startValue = 7;
return value - startValue;
}当有人决定将startValue更改为double的 13.5时,就会发生连锁反应,并决定必须保留此精度,因此需要将a() , b()和c()从int s更新为double s。
private double d(double value) {
double startValue = 13.5;
return value - startValue;
}程序员避免使用长距离传递依赖项,因为他们有更多的方法可以将任何随机更改波动回去。
旧消息。 不重要的。 这没东西看。
但是,当我们检查类依赖时,这会改变吗? 让我们将a()和b()依附在一个类中,将c()和d()依附于另一个类中,同时仍然保留方法级的传递依赖项: a() -> b() -> c() -> d() 。
class Here {
There there = new There();
private int a(int value) {
return b(value) * 2;
}
private int b(int value) {
return there.c(value) * 3;
}
}
class There {
int c(int value) {
return d(value) * 5;
}
private int d(int value) {
int startValue = 7;
return value - startValue;
}
}再次考虑d()的变化,触发所有其他更新。 这个例子和前面的例子有区别吗?
我们知道传递依赖关系的长度是敌人,在第二个示例中,我们在类级别上只有两个类的传递依赖关系较短。 那么,与第一个示例的四种方法相比,这两种类型中的波纹效应发生的可能性较小吗?
不,他们不是。 因为这四种方法仍然存在。 沿这四种方法产生波纹效应的可能性保持不变。 ( McBain -voice)“课程什么都不做!”
什么是包依赖关系? 让我们将这些幼犬包装在单独的包装中:这会有助于减少纹波效应的潜在成本吗?
package x;
class Here {
There there = new There();
private int a(int value) {
return b(value) * 2;
}
private int b(int value) {
return there.c(value) * 3;
}
}
package y;
public class There {
public int c(int value) {
return d(value) * 5;
}
private int d(int value) {
int startValue = 7;
return value - startValue;
}
}您会看到前进的方向。 尽管将类封装在两个包中,但仍然有令人讨厌的四个方法依赖的传递依赖关系,涟漪效应从根本上遍历了方法依赖关系。
是的,课堂也会遭受连锁反应。 上面,类There在这里由于类There的变化而受到重创,但这是底层方法级依赖关系的结果。 没有底层方法级别的依赖关系(假设您不直接访问字段变量,而您不是直接访问字段变量,对吗?),就不能存在任何类级别的依赖关系(因此也就没有类级别的涟漪效应)。
从涟漪效应的角度来看,类和包级别的依赖关系仅仅是底层方法级别的依赖关系的指示性汇总。 从这个意义上说,它们不存在,至少作为独立的结构不存在。
因此,方法级别的源代码结构可以被视为基本结构 ,而类和包级别的结构可以被视为派生结构 ,因为它是从底层方法级别结构派生的。
那么我们可以不理会这种派生的结构而去喝啤酒吗?
不。它只是服务于与基本结构不同而同样重要的目的。
再次考虑图1的好坏结构,在图2中转载于此……因为滚动。
图2:再次是图1。
如果我们的理论是正确的,那么这两个派生包结构都不会告诉我们任何一个系统要花费多少更新,这些信息被冻结在方法级结构中。
但是,如果我们假设方法在包装上的典型分布(也就是说,没有一个包装包含所有方法的99%),那么图2告诉我们一些重要的事情:它告诉我们可以预测美容的相对更新成本左边的野兽比右边的野兽好。
我们可以预测,对左侧系统的最高级程序包进行更改的成本应比对底部系统的更改所需的成本低,因为对这些下部程序包的依赖性更大。 相对于蜡笔涂抹而言,这是一个巨大的好处,因为更改任何包装都可能影响几乎所有其他包装。
正是这种派生的结构(而不是基本结构)才能实现这种粗粒度的可预测性,这对于任何大型商业软件项目都是必不可少的。
您可能会怀疑这种可预测性还源于基本的方法结构,左侧的系统必须源自比右侧的系统更好的方法结构。 但不是。 实际上,图2的两个程序包结构都源自相同的方法结构:它们实际上是同一系统。
图3显示了邪恶的黑客如何通过182重构对左侧的系统造成了折磨(使用先前文章中的蛮力包耦合减少算法)。 细节并不重要,但是算法仅在包之间移动类,翻译对t a() -> b() -> c() -> d()毫无影响; 无论所有四个方法都挤在一个类中,还是嬉戏在两个,三个或四个类或包中,此传递依赖关系都保持不变。
图3:结构良好,被炸死。
两种类型的重构
给定这两种不同的结构,并且鉴于重构只是保留行为的重构,因此必须有两种类型的重构。
如果您更改程序的基本结构(例如,添加或合并方法,或者修剪长方法的可传递依赖项),那么您正在做第一种重构,那就叫它: 基本重构 。 基本重构的目的是使程序的更新便宜。
如果您更改程序的派生结构(例如,将一个类拆分为两个类,或将某些类移至新的包中),则您正在执行第二种类型的重构,我们称其为: 精细重构 。 精细重构的目的不是使程序的更新成本降低,而是使更新成本更可预测(通过“阐述”系统的粗粒度性质)。
碰巧的是,改进这两种结构的方法是相同的: 最小化可传递依赖项的长度 ,无论它们在方法级别,类级别还是程序包级别。
所以从某种意义上讲,这全是哲学上的。
所以……是的……对此感到抱歉。
摘要
博客一直在抱怨,良好的结构既可以帮助降低更新成本,又可以提高成本可预测性。
现在您知道了。
翻译自: https://www.javacodegeeks.com/2016/03/fundamental-refactoring-vs-elaborative-refactoring.html