OneFlow | 新深度学习框架后浪(附源代码)
计算机视觉研究院专栏
作者:Edison_G
OneFlow 是什么?
OneFlow是开源的、采用全新架构设计,世界领先的工业级通用深度学习框架。
为什么是OneFlow?
分布式训练全新体验,多机多卡如单机单卡一样简单
完美契合一站式平台(k8s + docker)
原生支持超大模型
近零运行时开销、线性加速比
灵活支持多种深度学习编译器
自动混合精度
中立开放,合作面广
持续完善的算子集、模型库
1、背景

随着深度学习的发展,用户越来越依赖 GPU 或者其他加速器进行大规模运算。人工智能(Artificial Intelligence)需要更优秀的软件来释放硬件的能量已成业界共识。一方面,各种框架需要进一步降低编写深度学习分布式训练程序的门槛;另一方面,用户期待系统可以支持不同的深度学习网络模型,并实现线性加速。各知名深度学习框架正在朝这方面努力,但用户在使用这些框架时仍会遇到横向扩展性的难题,或者是投入很多计算资源但没有看到效率收益,或者是问题规模超过 GPU 显存限制而无法求解。
一流科技团队历时两年研发了一套全新的深度学习引擎 OneFlow,在大数据和大模型场景都展现了相对于已有引擎的显著优势。
(摘自“成诚”)时至今日,一个框架有没有机会成功,要看它有没有差异化的特点。OneFlow是有其独特的设计理念和技术路线的。目前市面上已有的众多开源框架,用户最多的是PyTorch和TensorFlow,除此之外还有各大公司的自研框架:PaddlePaddle、MXNet、MindSpore、MegEngine等等。其中TensorFlow的特点是最完备,推理、serving、XLA、tensorboard等一应俱全,工业部署的主流还是TensorFlow;PyTorch的特点是易用性最好,eager执行、动态图、跟python的交互方式等等,非常受科研人员喜欢。
可以说完备性和易用性这两极分别被TF和PyTorch占据,OneFlow作为一个小团队打造的框架,如果单纯的模仿别的框架,跟TF比完备性,跟PyTorch比易用性,那是绝对没戏的。但深度学习框架还有第三极:性能。OneFlow的特点就是追求极致的性能,而且是分布式多机多卡环境下的横向扩展性。OneFlow的核心设计理念就是从分布式的性能角度出发,打造一个使用多机多卡就像使用单机单卡一样容易,且速度最快的深度学习框架。
为什么OneFlow要聚焦于分布式场景的性能和易用性呢?因为深度学习是吞没算力的巨兽,单卡的算力和显存远远不能满足深度学习模型训练的需求。多机多卡的理想很丰满,现实很骨感,普通用户在使用其他框架时常常会发现多机多卡难以使用且效率低下、BERT/GPT-3等参数量巨大的模型无法实现等问题。别的框架一般都是先聚焦于单卡的视角和用户体验,对于多机多卡的处理就是把单卡的计算图镜像复制到多机多卡上,各个卡和机器之间辅助于模型同步的模块。业界不仅仅改进深度学习框架自身,还研发了多种第三方插件,譬如NCCL, Horovod, BytePS,HugeCTR,Mesh-tensorflow, Gpipe等等。但是,仍只满足一小部分需求。对于普通用户而言,使用其他框架做分布式训练常常需要更高的学习成本,还需要关心多机多卡之间模型是怎么同步的。但OneFlow不一样,OneFlow在框架最核心的设计上就在考虑分布式训练如何高效的协同运转,同时要让用户在多机多卡的训练体验上就像单卡一样简单容易。
2、性能
OneFlow历经两年的研发,2018年10月份才推出1.0版本。实事求是的讲,在模型的丰富程度,易用性,多语言支持等方面还有比较大的提升空间。OneFlow在企业级大规模应用上是称得上遥遥领先的:
(1)分布式最容易使用,用户在写程序的时候是感受不到多机和单机的区别的;
(2)OneFlow支持数据并行,模型并行和流水并行,而其它框架只支持最容易支持的数据并行;
(3)OneFlow在分布式训练时的扩展能力,加速比是最优秀的。
这些特点也正是OneFlow作为企业级深度学习框架,比已有开源深度学习框架优秀之处。

一机8卡加速比测试
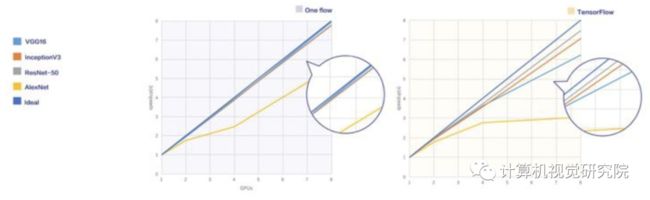
卷积神经网络(CNN)作为最容易解决的一个问题,是大家最喜欢拿来做基准测试的应用。如果发现TensorFlow的参数服务器不给力,上层使用Horovod,底层使用Nvidia NCCL已经可以做到很漂亮的结果。需要注意的是,以前社区有一个认识是TensorFlow并行做的不好,速度比其它框架慢,实际上今天已经不是这样了,TensorFlow团队的benchmark项目针对CNN做了很多优化,做数据并行已经是开源框架里最优秀之一了。
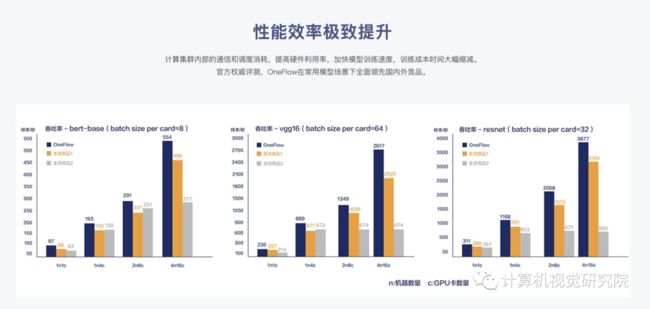
一流科技团队使用完全一样的算法和硬件(V100 GPU, 100Gbps RDMA网络),和TensorFlow benchmark对比会发现,无论是基于单机多卡,还是多机多卡都是比TensorFlow快。上图左边是OneFlow,右边是TensorFlow,除了AlexNet遇到硬件瓶颈,OneFlow都能做到线性加速,TensorFlow在单机多卡和多机多卡上与OneFlow还是有一定的差距。
3、亮点
今天我从他的亮点——分布式,详细说说!

Consistent 与 Mirrored 视角
在进行分布式训练时,OneFlow框架提供了两种角度看待数据与模型的关系,被称作consistent视角与mirrored视角。
本文将介绍:
数据并行与模型并行的区别及适用场景
在分布式任务中采用mirrored视角及其特点
在分布式任务中采用consistent视角及其特点

数据并行与模型并行
为了更好地理解OneFlow中的 consistent 和 mirrored 视角,我们需要了解分布式任务中的数据并行 、模型并行两种并行方式的区别。
为了更直观地展示两者的差别,我们先看一个简单的op(在OneFlow中,逻辑上的运算都被抽象为了operator ,称作op):矩阵乘法。
我们假定在模型训练中,存在一个输入矩阵I ,通过矩阵I与矩阵W做矩阵乘法,得到输出矩阵O。

如以上所示,I的大小为(N, C1),W的大小为(C1, C2),O的大小为(N, C2)。结合机器学习的业务逻辑,可以赋予以上几个矩阵直观意义:
I矩阵作为输入矩阵,每一行都是一个样本,一行中的各列代表了样本的特征;
W矩阵代表了模型参数;
O是预测结果或者label ,如果是预测作业,那么就是由I、W求解O,得到分类结果的过程;如果是训练作业,那么就是由I与O求解W的过程。
当以上I矩阵的行N很大,说明样本很多;如果W矩阵的列C2很大,说明模型复杂;当样本数目、模型复杂程度复杂到一定程度时,单机单卡的硬件条件已经无法承载训练作业,就需要考虑分布式的方式训练。而在分布式系统中,我们可以选择 数据并行 和 模型并行。
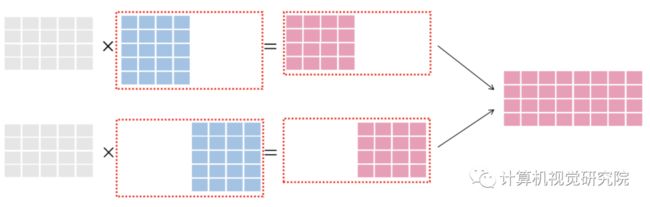
为了便于理解数据并行与模型并行,我们先用下图作为矩阵相乘op的示例:

等式左边第1个灰色的矩阵代表输入样本,每一行是一个样本;等式左边第2个蓝色的矩阵代表模型。在后文中,我们将看到以上的op,在数据并行与模型并行下,不同的“切分”方式。
1)数据并行图示
在数据并行中,将样本数据进行切分,切分后的数据 被送至各个训练节点,与完整的模型进行运算,最后将多个节点的信息进行合并,如下图所示:

2)模型并行图示
在模型并行中,将模型进行切分,完整的数据被送至各个训练节点,与切分后的模型 进行运算,最后将多个节点的运算结果合并,如下图所示:
总之:
数据并行下,各个训练节点的模型是完全一样的,数据被切分;
模型并行下,各个训练节点都接收一样的完整数据, 模型被切分。
接下来将介绍OneFlow看待分布式系统的两种视角(mirrored视角与consistent视角),学习在不同的视角下如何选择并行方式。
在具体说mirrored视角与consistent视角之前,说一下OneFlow的占位符。
数据占位符
注意,OneFlow的images、logits、labels、loss等对象,在定义作业函数时,并没有实际的数据。它们的作用只是描述数据的形状和属性 ,起到占位符的作用。
在作业函数的参数中的数据占位符,使用oneflow.typing下的Numpy.Placeholder、ListNumpy.Placeholder、ListListNumpy.Placeholder,注解作业函数参数的类型,对应作业函数调用时,传递 numpy 数据对象。
除了oneflow.typing下的几种类型外,不出现在参数中,而由 OneFlow 的算子或层产生的变量,如以上代码中的reshape、hidden、logits、loss等,也都起到了数据占位符的作用。
不管是以上提及的哪种变量,它们都直接或间接继承自OneFlow的BlobDef基类,OneFlow中把这种对象类型统称为Blob。
Blob 在作业函数定义时,均无真实数据,均只起到数据占位方便框架推理的作用。
两类占位符
实际上,针对并行,OneFlow的数据占位符还可以细分为两类:分别通过接口oneflow.typing.Numpy.Placeholder和oneflow.typing.ListNumpy.Placeholder构造的占位符,分别对应 Consistent 与 Mirrored情况。
我们将在下文中看到它们的具体应用。
在 OneFlow 中使用 mirrored 视角
其它的框架,如TensorFlow、Pytorch均支持mirroed strategy;OneFlow的mirrored视角与它们类似。在mirrored视角下,模型被镜像复制到每张卡上,每个节点的模型构图是完全相同的,只能采用 数据并行 。
在OneFlow中,默认不是mirrored策略,需要通过flow.function_config()的default_logical_view接口来显式指定:
func_config = flow.function_config()
func_config.default_logical_view(flow.scope.mirrored_view())
在mirrored_view下,只能采用数据并行的并行模式,在调用作业函数时,我们需要将数据按照训练节点的数目(显卡总数)进行平均切分,并将切分后的数据放入list中进行传递,list中的每个元素,就是后分配给 各个显卡 的实际数据。
训练函数的返回值类型,也变作了oneflow.typing.ListNumpy,是一个list,list中的每个元素,对应了每张卡上训练结果。
以上提及的list中的所有元素 拼接在一起 ,才是一个完整的 BATCH。
在 OneFlow 中使用 consistent 视角
我们已经了解了mirrored视角,知道在mirrored_view视角下,样本会被平均分配到多个完全一样的模型上进行分布式训练,各个训练节点上的结果,需要组装才能得到真正完整的BATCH,对应了逻辑上的op与Blob。
除了mirroed视角外,OneFlow还提供了consistent视角。consistent视角是OneFlow的一大特色,与mirrored视角相比有很大的优势。
默认情况下OneFlow采取的是consistent视角,如果想显式声明,也可以通过代码设置:
config = flow.function_config()
config.default_logical_view(flow.scope.consistent_view())
之所以说consistent视角是OneFlow的一大特色,是因为在OneFlow的设计中,若采用consistent_view,那么从用户的视角看,所使用的op、blob将获得 逻辑上的统一,同样以本文开头的矩阵乘法为例,我们只需要关注矩阵乘法本身数学计算上的意义;而在工程上到底如何配置、采用模型并行还是数据并行等细节问题,可以使用OneFlow的接口轻松完成。OneFlow内部会高效可靠地解决 数据并行中的数据切分 、模型并行中的模型切分 、串行逻辑 等问题。
在OneFlow的consistent视角下,可以自由选择模型并行、数据并行、流水并行或者混合并行。

小结
在OneFlow的设计中,所有的出发点都是希望可以尽可能并行,从而达到最优的分布式性能。
比如考虑到分布式训练模型梯度同步时,显存到内存的传输带宽高于机器之间的网络传输带宽,OneFlow会做两级的scatter和gather操作(本机的和各个机器之间的),用于增加locality,提高整体性能;
又比如在异步启动深度学习训练时,python端用户的控制逻辑跟OneFlow运行时的执行图是并行执行的,同时OneFlow有一套互斥临界区的设计保证执行的高效性和正确性;
数据加载部分无论是从磁盘读数据还是从python端喂数据,OneFlow都能保证尽可能并行,使得计算设备不会因为要等数据而导致性能下降。
已有框架如果想要尽可能重叠数据搬运和计算,一般借助多层回调(callback)函数,当嵌套层次过多时,会遇到所谓的callback hell麻烦,正确性和可读性都可能下降。但在OneFlow中,以上的这些并行并发特性,都是在这一套简洁的Actor机制下实现的,解决了令人头秃的callback hell问题。
此外,在多机的网络通信部分,OneFlow底层的网络通信库原生支持RDMA的高性能通信,也有一套基于epoll的高效通信设计。而目前最流行的Pytorch,多机还需要通过RPC来做数据同步。
OneFlow框架是由一流科技团队研发,主要创始人——袁进辉,我的师兄,也是北京一流科技有限公司 · 公司创始人,有兴趣的同学可以去他主页。

今天暂时和大家分享OneFlow深度学习框架的基础性能和优势,下一期我们给大家详细说说“OneFlow的并行特色”以及“Placement+SBP”,OneFlow是如何做到分布式最易用的。
✄----------------------------------------
如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注我们
公众号 : 计算机视觉战队
扫码回复“OneFlow”获取源代码