深度学习框架OneFlow的并行特色(附框架源码和教程)
计算机视觉研究院专栏
作者:Edison_G
OneFlow 是什么?
OneFlow是开源的、采用全新架构设计,世界领先的工业级通用深度学习框架。
目录
1、背景
2、网络模型训练的逻辑图
3、Consistent 视角下的并行特色
4、选择最优的并行方式
5、混合并行实例
6、流水并行实例
1、背景
在之前,“计算机视觉研究院”已经详细分享了OneFlow深度学习框架基础结构以及分析了分布式子训练的特点,今天我们就简单说说OneFlow的并行特色。
链接:
OneFlow | 新深度学习框架后浪(附源代码)
OneFlow快速上手教程
最新深度学习框架——OneFlow:新分布式训练(附源代码)
在Consistent 与 Mirrored 视角中,我们已经知道 OneFlow 提供了 mirrored 与 consistent 两种看待分布式系统的视角,并且提前了解了 OneFlow 的 consistent 视角颇具特色。
因为在 consistent_view 下,OneFlow 提供了逻辑上统一的视角,分布式训练时,用户可以自由选择数据并行、模型并行还是是混合并行。
在本文中,继续深入介绍 OneFlow 独具特色的 consistent 视角,包括:
OneFlow在consistent_view下纯数据并行流程示意
OneFlow在consistent_view下混合并行流程示意
混合并行的优势及适用场景
OneFlow混合并行实例
2、网络模型训练的逻辑图
我们先设定一个简单的多层网络,作为我们我们讨论并行方式的载体,其结构如下图所示:

各层中,有 样本 (灰色矩形)、 模型 (蓝色矩形),以及作用在两者之上的 op (圆形),为了简化讨论,我们也可将样本与模型限定为 矩阵 ,作用在它们之上的op为 矩阵乘法 。
对照上图,我们很容易梳理出该网络模型的逻辑:
第0层的输入为 Data 0 矩阵与 Model 0 矩阵,它们进行 op (矩阵乘法)运算后,输出 Data 1
第1层的输入为 Data 1 矩阵与 Model 1 矩阵,它们进行 op 运算后,输出 output
第2层为 output 层,Data 2 作为整个网络的输出;当然,在更深的网络中,它也可以作为下一层的输入继续参与训练
consistent 视角下支持数据并行、模型并行与混合并行,我们将依次进行介绍,其中混合并行是重点。
3、Consistent 视角下的并行特色
纯数据并行
我们已经知道,consistent 视角下,默认的并行方式是数据并行;而如果选择 mirrored 视角,则只能采用数据并行;若在调用作业函数时直接传递 numpy 数据(而不是使用 OneFlow 的 flow.data.xxx_reader 接口进行数据加载),两者的区别在于:
mirrored 视角下,采用纯数据并行,需要自己根据参与训练的卡数对数据进行切分、重组,使用 list 传递和接收数据;
而 consistent 视角下提供了逻辑上的统一看待,数据的切分和重组交给了OneFlow 框架完成。
下图是 consistent 视角下,采用纯数据并行的方式,实现原逻辑网络模型的流程示意图:
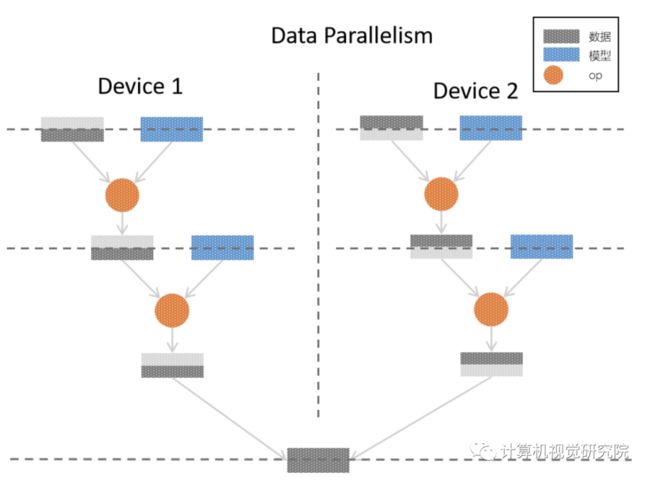
在纯数据并行中,采用了2张显卡进行并行训练,因为采用了 纯数据并行 ,可以看到,对于原逻辑模型中的每一层,样本数据都被平均分配到了各个卡上,每张卡上都拥有 完整的模型,与切分的数据进行 op 运算,最后组合各个卡上的样本,得到完整的输出。
纯模型并行
在 consistent 视角下,也可以通过选择纯模型并行(设置方式在下文实例中会介绍),其流程示意图为:

在纯模型并行中,同样是2张显卡进行并行训练,原逻辑模型中的每一层中,都是 部分模型 与 完整的数据 进行 op 运算,最后组合得到完整的输出。
值得一提的是,从上图可以看出,各个卡上第0层的输出,并 不能 直接作为第1层的输入:因为模型并行中,为完成 op 操作,需要部分的模型与 完整的 数据;为了解决这个问题,OneFlow 中使用了 boxing 机制。
boxing 机制会统筹分布式训练中各个节点的数据,并合理切分、合并到对应的卡上,除了模型并行过程中的数据重组问题外,数据并行中的反向梯度同步,也使用 boxing 机制解决。
boxing 的内部机制虽然复杂,但是对于用户而言是透明的,我们仅仅是防止读者产生迷惑才加入了 boxing 的图示,对于本文而言,我们只需要了解:OneFlow 会自动协调好分布式中数据的同步问题。
4、选择最优的并行方式
数据并行与模型并行的优劣并不是一成不变的,样本规模、模型规模及模型结构决定了分布式训练中的综合表现,需要具体情况具体分析。
概括而言:
数据并行情况下,需要同步的信息是反向传播过程的 梯度,因此应该确保各个训练节点之间的信息同步速度要比节点内部的计算速度快,比如说 卷积层 的参数较少,但是计算量大,就比较适合使用数据并行;
模型并行情况下,因为可以将逻辑上作为整体的模型 切分到各个物理卡 上,能够解决“模型太大,一张卡装不下”的问题,因此,对于参数量大的神经网络层(如最后的全连接层),可以考虑使用模型并行。
实际上,也可以使用 混合并行,在同一个分布式训练的不同部分,组合使用数据并行、模型并行。比如,对于神经网络中靠前的参数较少、计算量大的层,采用数据并行;在最终的参数众多的全连接层,则采用模型并行,以下是针对本文最开始的网络模型逻辑图的 混合并行 实现方案的示意图:

目前,其它的主流框架对于混合并行或者不支持,或者需要深度定制,而OneFlow 中可以通过简单的设置,配置混合并行的分布式训练,还可以用自由度超高的“网络接力”的并行模式,深度优化分布式系统。
5、混合并行实例
代码示例
以下,在 consistent 视角下,我们对 MLP 模型采用了混合并行方案:输入层与隐藏层采用(默认的)数据并行;输出层采用模型并行并进行列切分。
完整代码:mixed_parallel_mlp.py
# mixed_parallel_mlp.py
import oneflow as flow
import oneflow.typing as tp
BATCH_SIZE = 100
def mlp(data):
initializer = flow.truncated_normal(0.1)
reshape = flow.reshape(data, [data.shape[0], -1])
hidden = flow.layers.dense(
reshape,
512,
activation=flow.nn.relu,
kernel_initializer=initializer,
name="dense1",
)
return flow.layers.dense(
hidden,
10,
kernel_initializer=initializer,
# dense涓哄垪瀛樺偍锛岃繘琛宻plit(0)鍒囧垎
model_distribute=flow.distribute.split(axis=0),
name="dense2",
)
def get_train_config():
config = flow.function_config()
config.default_data_type(flow.float)
return config
@flow.global_function(type="train", function_config=get_train_config())
def train_job(
images: tp.Numpy.Placeholder((BATCH_SIZE, 1, 28, 28), dtype=flow.float),
labels: tp.Numpy.Placeholder((BATCH_SIZE,), dtype=flow.int32),
) -> tp.Numpy:
logits = mlp(images)
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(
labels, logits, name="softmax_loss"
)
lr_scheduler = flow.optimizer.PiecewiseConstantScheduler([], [0.1])
flow.optimizer.SGD(lr_scheduler, momentum=0).minimize(loss)
return loss
if __name__ == "__main__":
flow.config.gpu_device_num(2)
check_point = flow.train.CheckPoint()
check_point.init()
(train_images, train_labels), (test_images, test_labels) = flow.data.load_mnist(
BATCH_SIZE
)
for epoch in range(3):
for i, (images, labels) in enumerate(zip(train_images, train_labels)):
loss = train_job(images, labels)
if i % 20 == 0:
print(loss.mean())
代码解析
以上代码修改自3分钟快速上手中的示例代码,比较两份代码,也可以体会到在 OneFlow 的 consistent_view 下进行各种并行方案的配置是多么的简单,只需要在单机的程序上稍加修改即可。
以上程序的关键部分有:
通过 oneflow.config.gpu_device_num 接口设置参与训练的GPU数目:
flow.config.gpu_device_num(2)
reshape 及 hidden 采用默认的数据并行,不需要修改;输出层通过设置 model_distribute 为 flow.distribute.split(axis=0) 变为模型并行:
def mlp(data):
initializer = flow.truncated_normal(0.1)
reshape = flow.reshape(data, [data.shape[0], -1])
hidden = flow.layers.dense(
reshape,
512,
activation=flow.nn.relu,
kernel_initializer=initializer,
name="dense1",
)
return flow.layers.dense(
hidden,
10,
kernel_initializer=initializer,
# dense为列存储,进行split(0)切分
model_distribute=flow.distribute.split(axis=0),
name="dense2",
)
有读者可能好奇为什么split(axis=0)是列切分?需要说明的是,OneFlow 中的 dense 内部采用列存储,因此以上代码的flow.distribute.split(axis=0)确实是在做列切分。
此外,flow.layers.dense 使用 model_distribute 形参设置并行方式,其内部调用了底层更通用的 get_variable 接口创建 blob, get_variable 接口设置并行方式的形参名为 distribute。
可以看到,我们通过极少量的修改,就能将单机训练程序改为分布式、混合并行的程序,这是 OneFlow 区别于其它框架的一大特色。
6、流水并行实例
在模型并行之外,OneFlow 还提供了一种灵活度更高的“流水并行”的并行方式,可以让用户使用 scope.placement 接口显式指定用来运行逻辑 op的 物理硬件。
在流水并行中,整个神经网络有的层次在一组物理设备上,另外一些层次在另外一组物理设备上,它们以接力的方式协同工作,分多个阶段,在设备之间流水执行。
在以下示例中,我们对Consistent 与 Mirrored 视角中的"在 OneFlow 中使用 consistent 视角"代码进行简单修改,展示了流水并行模式。
代码示例
完整代码:mixed_parallel_lenet.py
# mixed_parallel_lenet.py
import oneflow as flow
import oneflow.typing as tp
BATCH_SIZE = 100
def lenet(data, train=False):
initializer = flow.truncated_normal(0.1)
conv1 = flow.layers.conv2d(
data,
32,
5,
padding="SAME",
activation=flow.nn.relu,
kernel_initializer=initializer,
name="conv1",
)
pool1 = flow.nn.max_pool2d(conv1, ksize=2, strides=2, padding="SAME", name="pool1")
conv2 = flow.layers.conv2d(
pool1,
64,
5,
padding="SAME",
activation=flow.nn.relu,
kernel_initializer=initializer,
name="conv2",
)
pool2 = flow.nn.max_pool2d(conv2, ksize=2, strides=2, padding="SAME", name="pool2")
reshape = flow.reshape(pool2, [pool2.shape[0], -1])
with flow.scope.placement("gpu", "0:0"):
hidden = flow.layers.dense(
reshape,
512,
activation=flow.nn.relu,
kernel_initializer=initializer,
name="hidden",
)
if train:
hidden = flow.nn.dropout(hidden, rate=0.5)
with flow.scope.placement("gpu", "0:1"):
output = flow.layers.dense(
hidden, 10, kernel_initializer=initializer, name="outlayer"
)
return output
def get_train_config():
config = flow.function_config()
config.default_data_type(flow.float)
return config
@flow.global_function(type="train", function_config=get_train_config())
def train_job(
images: tp.Numpy.Placeholder((BATCH_SIZE, 1, 28, 28), dtype=flow.float),
labels: tp.Numpy.Placeholder((BATCH_SIZE,), dtype=flow.int32),
) -> tp.Numpy:
logits = lenet(images, train=True)
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(
labels, logits, name="softmax_loss"
)
lr_scheduler = flow.optimizer.PiecewiseConstantScheduler([], [0.1])
flow.optimizer.SGD(lr_scheduler, momentum=0).minimize(loss)
return loss
if __name__ == "__main__":
flow.config.gpu_device_num(2)
check_point = flow.train.CheckPoint()
check_point.init()
(train_images, train_labels), (test_images, test_labels) = flow.data.load_mnist(
BATCH_SIZE
)
for epoch in range(50):
for i, (images, labels) in enumerate(zip(train_images, train_labels)):
loss = train_job(images, labels)
if i % 20 == 0:
print(loss.mean())
代码解析
以上关键的代码只有2行,且他们的本质作用是类似的:
通过 oneflow.scope.placement ,指定 hidden 层的 op 计算运行在0号 GPU 上:
with flow.scope.placement("gpu", "0:0"):
hidden = flow.layers.dense(
reshape,
512,
activation=flow.nn.relu,
kernel_initializer=initializer,
name="hidden",
)
通过 oneflow.scope.placement ,指定 output 层的op计算运行在1号GPU上:
with flow.scope.placement("gpu", "0:1"):
output = flow.layers.dense(
hidden, 10, kernel_initializer=initializer, name="outlayer"
)
其中 scope.placement 的第一个参数指定 cpu 还是 gpu,第二个参数指定机器及运算设备编号,如,“使用第1号机器的第2个 GPU”,则应该写:
with flow.scope.placement("gpu", "1:2"):
# ...
流水并行,使得用户可以为每个 op 指定物理设备,非常适合对网络模型及分布式情况都很熟悉的用户进行深度优化 。
此外,OneFlow 提供的 API oneflow.unpack、oneflow.pack 等,结合了 OneFlow 自身任务调度的特点,使得流水并行更易用、高效。
✄-------------------------------------
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注我们
公众号 : 计算机视觉研究院
扫码回复“OneFlow”获取源代码