memcache 的内存管理介绍和 php实现memcache一致性哈希分布式算法
1 网络IO模型
安装memcached需要先安装libevent
Memcached是多线程,非阻塞IO复用的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描述字 pipe 传递给worker线程,进行读写IO, 网络层使用libevent封装的事件库,多线程模型可以发挥多核作用,但是引入了cache coherency和锁的问题,比如,Memcached最常用的stats 命令,实际Memcached所有操作都要对这个全局变量加锁,进行计数等工作,带来了性能损耗。
2.内存管理方面
memcached 用 slab allocator 机制来管理内存.
slab allocator 原理: 预告把内存划分成数个 slab class 仓库
各仓库,切分成不同尺寸的小块(chunk).
需要存内容时,判断内容的大小,为其选取合理的仓库
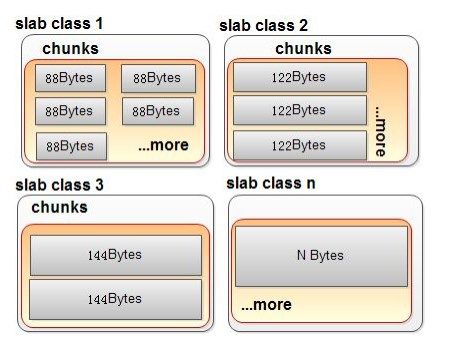
Memcached使用预分配的内存池的方式,使用slab和大小不同的chunk来管理内存,Item根据大小选择合适的chunk存储,内存池的 方式可以省去申请/释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被 剔除,原因可以参考Timyang的文章:http://timyang.net/data/Memcached-lru-evictions/
memcache可能会因为内存不够用而删除一些数据(lru算法)
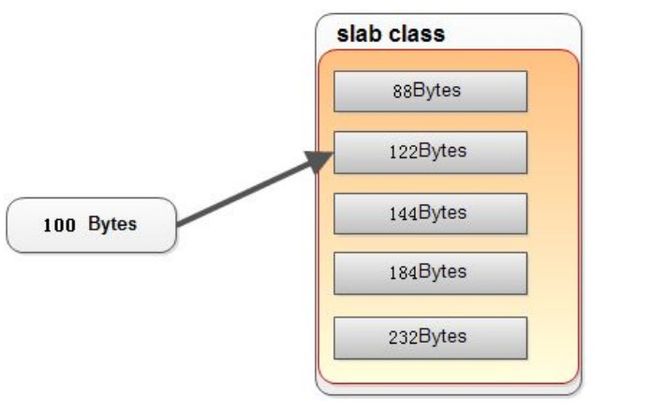
如果有 100byte 的内容要存,但 122 大小的仓库中的 chunk 满了
并不会寻找更大的,如 144 的仓库来存储,
而是把 122 仓库的旧数据踢掉! 详见过期与删除机制
惰性删除机制
memcached 的过期数据惰性删除
1: 当某个值过期后,并没有从内存删除, 因此,stats 统计时, curr_item 有其信息
2: 当某个新值去占用他的位置时,当成空 chunk 来占用.
3: 当 get 值时,判断是否过期,如果过期,返回空,并且清空, curr_item 就减少了.
即--这个过期,只是让用户看不到这个数据而已,并没有在过期的瞬间立即从内存删除.
这个称为 lazy expiration, 惰性失效.
好处--- 节省了 cpu 时间和检测的成本
memcached 的 此处用的 lru 删除机制.
如果以 122byte 大小的 chunk 举例, 122 的 chunk 都满了, 又有新的值(长度为 120)要加入, 要
挤掉谁?
memcached 此处用的 lru 删除机制.
(操作系统的内存管理,常用 fifo,lru 删除)
lru: least recently used 最近最少使用
fifo: first in ,first out
原理: 当某个单元被请求时,维护一个计数器,通过计数器来判断最近谁最少被使用.
即使某个 key 是设置的永久有效期,也一样会被踢出来! 即--永久数据被踢现象
Redis使用现场申请内存的方式来存储数据,并且很少使用free-list等方式来优化内存分配,会在一定程度上存在内存碎片,Redis跟据存 储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致swap也不会剔除任何 非临时数据(但会尝试剔除部分临时数据),这点上Redis更适合作为存储而不是cache。
3.数据一致性问题
Memcached提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 Redis没有提供cas 命令,并不能保证这点,不过Redis提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断。
cas命令说明:
CAS(check and save)模式
1.预先在memcached中设置一个key值,假设为check=1
2.每次创建活动时,在规则校验前先get出check=x;
3.进行规则校验
4.执行incr check操作,检验返回值是否为所期望的x+1,如果不是,则说明在此期间有另外的进程执行了incr操作,即存在并发,放弃更新。否则
5.执行创建活动
memcached保存的key value都有一个唯一标识casUnique,在进行incr decr操作时,首先获取casUnique,执行incr,检验返回值是否casUnique+1,如果是,则更新,否则,失败不更新!
memcached 1.2.5以及更高版本,提供了gets和cas命令,如果您使用gets命令查询某个key的item,memcached会 给您返回该item当前值的唯一标识。如果您覆写了这个item并想把它写回到memcached中,您可以通过cas命令把那个唯一标识一起发送给 memcached。如果该item存放在memcached中的唯一标识与您提供的一致,您的写操作将会成功。如果另一个进程在这期间也修改了这个 item,那么该item存放在memcached中的唯一标识将会改变,写操作就会失败。
memcahe的原子性操作有 add incre decre cas 适合做一些并发锁
incr,decr 操作是把值理解为 32 位无符号来+-操作的. 值在[0-2^32-1]范围内
4.存储方式及其它方面
flag 的意义:
memcached 基本文本协议,传输的东西,理解成字符串来存储.
想:让你存一个 php 对象,和一个 php 数组
序列化成字符串,往出取的时候,自然还要反序列化成 对象/数组/json 格式等等.
这时候, flag 的意义就体现出来了.
flag 使用MEMCACHE_COMPRESSED标记对数据进行压缩(使用zlib)
比如, 1 就是字符串, 2 反转成数组 3,反序列化对象.....
key的限制 250个字符
https://github.com/memcached/memcached/blob/master/memcached.h
value的限制 1M
https://github.com/memcached/memcached/blob/master/memcached.c
memcache 命令
存
Set:添加一个新条目到memcached或是用新的数据替换替换掉已存在的条目
Add:当KEY不存在的情况下,它向memcached存数据,否则,返回NOT_STORED响应
Replace:当KEY存在的情况下,它才会向memcached存数据,否则返回NOT_STORED响应
Cas:改变一个存在的KEY值 ,但它还带了检查的功能
Append:在这个值后面插入新值
Prepend:在这个值前面插入新值
取
Get:取单个值 ,从缓存中返回数据时,将在第一行得到KEY的名字,flag的值和返回的value长度,真正的数据在第二行,最后返回END,如KEY不存在,第一行就直接返回END
Get_multi:一次性取多个值
分布式
各个memcached服务器之间互不通信,各自独立存取数据,不共享任何信息。服务器并不具有分布式功能,分布式部署取决于memcache客户端。
分布式算法(Consistent Hashing):
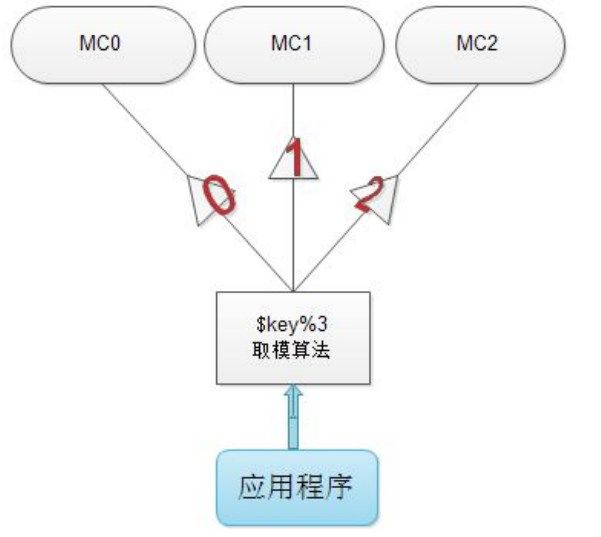
选择服务器算法有两种,一种是根据余数来计算分布,另一种是根据散列算法来计算分布。
余数算法:
先求得键的整数散列值,再除以服务器台数,根据余数确定存取服务器,这种方法计算简单,高效,但在memcached服务器增加或减少时,几乎所有的缓存都会失效。
散列算法:
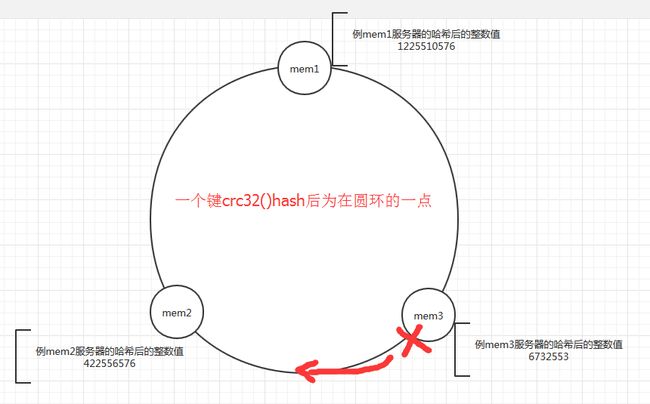
一致性哈希的算法把取余算法的等于号来选择mem服务器变成了大于号来选择mem服务器,这应该是才是关键,可以使一个键的mem服务器落点变成是动态选择(一个服务器down掉然后选择crc32()后大于这个服务器的落点....)
添加虚拟节点,虚拟节点其实还是原来那几台服务器,每个虚拟节点都对应一个真实的服务器,起到分散节点的作用
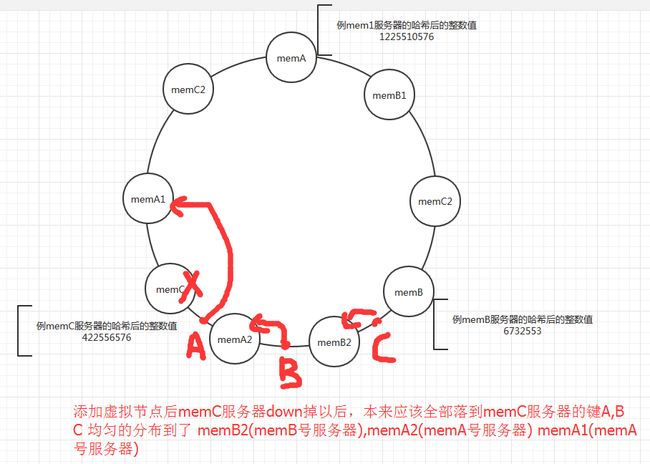
A1,A2的实际服务器就是A服务器.....
php
class ConsistentHash{
protected $nodes= array();
protected $postion= array();
protected $mul= 32; //每个节点对应 32 个虚节点
public function hash($str) {
return sprintf('%u',crc32($str)); // 把字符串转成 32 位符号整数
}
//查找key落到那个节点上
public function findNode($key) {
$point= $this->hash($key);
$node= current($this->postion); //先取圆环上最小的一个节点
foreach($this->postionas $k=>$v) {
if($point<= $k) {
$node= $v;
break;
}
}
reset($this->postion);//复位数组指针
return $node;//$key哈希后比最大的节点都大 就放到第一个节点
}
public function addNode($node) {
if(isset($this->nodes[$node])) {
return;
}
for($i=0; $i<$this->mul; $i++) {
$pos= $this->hash($node. '-' . $i);//$node = '168.10.1.72:8888'
$this->postion[$pos] = $node;
$this->nodes[$node][] = $pos;//方便删除对应的虚拟节点
}
$this->sortPos();
}
public function delNode($node) {
if(!isset($this->nodes[$node])) {
return;
}
foreach($this->nodes[$node] as $k) {
unset($this->postion[$k]);//删除对应的虚节点
}
unset($this->nodes[$node]);
}
protected function sortPos() {
ksort($this->postion,SORT_REGULAR);//SORT_REGULAR - 正常比较单元(不改变类型)
}
}
// 使用测试-----start
$con = new ConsistentHash();
//比如配置文件 $memServerConfArr = ['168.10.1.7:5566','168.10.1.2:7788','168.10.1.72:8899']
$memServerConfArr= array('168.10.1.7:5566','168.10.1.2:7788','168.10.1.72:8899');
foreach ($memServerConfArras $mem_config) {
$con->addNode($mem_config);//添加节点
}
$key = 'www.lashou.com';
$memNode= $con->findNode($key);
//echo($memNode);die(); 测试落到 168.10.1.7:5566这个节点上
$mem = explode(':', $memNode);
$host = $mem[0];
$port = $mem[1];
$memcache= new Memcache();
$memcache->connect($host, $port);
$memcache->set($key, 'test_string', MEMCACHE_COMPRESSED, 50);
//------------end
//取的时候是一样的start-------->>>end
先 算出memcached服务器的散列值,并将其分布到0到2的32次方的圆上,然后用同样的方法算出存储数据的键的散列值并映射至圆上,最后从数据映射到 的位置开始顺时针查找,将数据保存到查找到的第一个服务器上,如果超过2的32次方,依然找不到服务器,就将数据保存到第一台memcached服务器 上。如果添加了一台memcached服务器,只在圆上增加服务器的逆时针方向的第一台服务器上的键会受到影响。
把服务节点用crc32()函数转换成32位整数 ,sprintf('%u',crc32($str)) 无符号32位整数
cache的hash计算,一般的方法可以使用cache机器的IP地址或者机器名作为hash输入。
研发一部
郭飞