Allocator:用于定义存储分配模型分配器对象的类型。默认情况下,分配器类模板,它定义了最简单的内存分配模式,是值独立的
<2>map模板参数
map
<3>map的详细用法可参考:http://blog.csdn.net/bat603/article/details/1456141
2.map的实现机制
C++ STL 之所以得到广泛的赞誉,也被很多人使用,不只是提供了像vector, string, list等方便的容器,更重要的是STL封装了许多复杂的数据结构算法和大量常用数据结构操作。vector封装数组,list封装了链表,map和 set封装了二叉树等,在封装这些数据结构的时候,STL按照程序员的使用习惯,以成员函数方式提供的常用操作,如:插入、排序、删除、查找等。让用户在 STL使用过程中,并不会感到陌生。
C++ STL中标准关联容器set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树,也成为RB树(Red-Black Tree)。RB树的统计性能要好于一般的平衡二叉树(有些书籍根据作者姓名,Adelson-Velskii和Landis,将其称为AVL-树),所以被STL选择作为了关联容器的内部结构。本文并不会介绍详细AVL树和RB树的实现以及他们的优劣,关于RB树的详细实现参看红黑树: 理论与实现(理论篇)。本文针对开始提出的几个问题的回答,来向大家简单介绍map和set的底层数据结构。
<1>为何map和set的插入删除效率比用其他序列容器高?
之所以效率高,是因为对于关联容器来说,不需要做内存拷贝和内存移动。map和set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。结构图可能如下:
A
/ \
B C
/ \ / \
D E F G
|
因此插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点就OK了。这里的一切操作就是指针换来换去,和内存移动没有关系。
<2>为何每次insert之后,以前保存的iterator不会失效?
看见了上面答案的解释,你应该已经可以很容易解释这个问题。iterator这里就相当于指向节点的指针,内存没有变,指向内存的指针怎么会失效呢(当然 被删除的那个元素本身已经失效了)。相对于vector来说,每一次删除和插入,指针都有可能失效,调用push_back在尾部插入也是如此。因为为了保证内部数据的连续存放,iterator指向的那块内存在删除和插入过程中可能已经被其他内存覆盖或者内存已经被释放了。即使时push_back的时 候,容器内部空间可能不够,需要一块新的更大的内存,只有把以前的内存释放,申请新的更大的内存,复制已有的数据元素到新的内存,最后把需要插入的元素放 到最后,那么以前的内存指针自然就不可用了。特别时在和find等算法在一起使用的时候,牢记这个原则:不要使用过期的iterator。
<3>为何map和set不能像vector一样有个reserve函数来预分配数据?
究其原理来说时,引起它的原因在于在map和set内部存储的已经不是元素本身了,而是包含元素的节点。也就是说map内部使用的Alloc并不是map声明的时候从参数中传入的Alloc。例如:
map, Alloc > intmap;
这时候在intmap中使用的allocator并不是Alloc, 而是通过了转换的Alloc,具体转换的方法时在内部通过Alloc::rebind重新定义了新的节点分配器,详细的实现参看彻底学习STL中的Allocator。其实你就记住一点,在map和set内面的分配器已经发生了变化,reserve方法你就不要奢望了。
<4>当数据元素增多时(10000和20000个比较),map和set的插入和搜索速度变化如何?
在map和set中查找是使用二分查找,也就是说,如果有16个元素,最多需要比较4次就能找到结 果,有32个元素,最多比较5次。那么有10000个呢?最多比较的次数为log10000,最多为14次,如果是20000个元素呢?最多不过15次。 看见了吧,当数据量增大一倍的时候,搜索次数只不过多了1次,多了1/14的搜索时间而已。你明白这个道理后,就可以安心往里面放入元素了。
最后,对于map和set Winter还要提的就是它们和一个c语言包装库的效率比较。在许多unix和linux平台下,都有一个库叫isc,里面就提供类似于以下声明的函数:
void
tree_init(
void
**tree);
void
*tree_srch(
void
**tree,
int
(*compare)(),
void
*data);
void
tree_add(
void
**tree,
int
(*compare)(),
void
*data,
void
(*del_uar)());
int
tree_delete(
void
**tree,
int
(*compare)(),
void
*data,
void
(*del_uar)());
int
tree_trav(
void
**tree,
int
(*trav_uar)());
void
tree_mung(
void
**tree,
void
(*del_uar)());
|
许多人认为直接使用这些函数会比STL map速度快,因为STL map中使用了许多模板什么的。其实不然,它们的区别并不在于算法,而在于内存碎片。如果直接使用这些函数,你需要自己去new一些节点,当节点特别多, 而且进行频繁的删除和插入的时候,内存碎片就会存在,而STL采用自己的Allocator分配内存,以内存池的方式来管理这些内存,会大大减少内存碎 片,从而会提升系统的整体性能。本文原作者在自己的系统中做过测试,把以前所有直接用isc函数的代码替换成map,程序速度基本一致。当时间运行很长时间后(例如后台服务程序),map的优势就会体现出来。从另外一个方面讲,使用map会大大降低你的编码难度,同时增加程序的可读性。何乐而不为?
DDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDD
设要存储对象的个数为num, 那么我们就用len个内存单元来存储它们(len>=num); 以每个对象ki的关键字为自变量,用一个函数h(ki)来映射出ki的内存地址,也就是ki的下标,将ki对象的元素内容全部存入这个地址中就行了。这个就是Hash的基本思路。
Hash为什么这么想呢?换言之,为什么要用一个函数来映射出它们的地址单元呢?
EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEE
#include
#include
typedef char datatype;
typedef struct node{
datatype data;
struct node *next;
} listnode;
typedef listnode *linklist;
listnode *p;
/* 创建链表,从表头插入新元素 */
linklist createlist(void)
{
char ch;
linklist head;
listnode *p;
head = NULL;/*初始化为空*/
printf("请输入字符序列: \n");
ch = getchar();
while (ch != '\n'){
p = (listnode*)malloc(sizeof(listnode));/*分配空间*/
p->data = ch;/*数据域赋值*/
p->next = head;/*指定后继指针*/
head = p;/*head指针指定到新插入的结点上*/
ch = getchar();
}
return head;
}
/* 删除第i个节点 */
int deletelist(linklist *head, int i)
{
int j = 1;
listnode * p, *r;
p = *head;
if (i == 1) //删除第1个结点
{
*head = p->next;
free(p);
return 1;
}
//删除第i个结点(i>1),寻找第i-1个结点
while (p && j<(i - 1))
{
p = p->next;
++j;
}
if (!p || j>(i - 1))
{
return -1;
}
r = p->next;
p->next = r->next;
free(r);
return 1;
}
int main()
{
linklist list, head;
int i;
/* 创建链表,从表头插入新元素 */
list = createlist();
head = list;
printf("在删除前,输出链表中的元素\n");
do
{
printf("%c", head->data);
head = head->next;
} while (head != NULL);
printf("\n请输入要删除的结点位置(n>=1):");
scanf("%d", &i);
/* 删除第i个节点后的节点 */
deletelist(&list, i);
printf("在删除后,输出链表中的元素\n");
do
{
printf("%c", list->data);
list = list->next;
} while (list != NULL);
printf("\n");
}
=============================》
链表元素的删除
EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEE
数据结构之------什么是哈希表?(哈希表是一个以空间换取时间的数据结构!!! 加快查找速度!!!)
结合http://www.cnblogs.com/feichengwulai/articles/3523905.html这篇文章一起记忆!!!
@哈希表的实际应用
1,Sql中的索引,就是通过哈希表实现的。加大了数据存储空间,但查询速度快了很多!!!
---具体可以查哈希表的应用!!!
@什么是哈希表?
1,google搜索到的头条:
散列表(也叫哈希表),是根据关键码值直接进行访问的数据结构,也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
我觉得这个解释太含糊,想要整明白哈希表,那就得明白哈希表到底有什么样的优势。
数据结构中,有个时间算法复杂度O(n)的概念来衡量某种算法在时间效率上的优劣。哈希表的理想算法复杂度为O(1),也就是说利用哈希表查找某个值,系统所使用的时间在理想情况下为定值,这就是它的优势。那么哈希表是如何做到这一点的呢?
我们定义一个很大的有序数组,想要得到位于该数组第n个位置的值,它的算法复杂度为O(1)。哈希表利用哈希函数将需要存储的内容的关键值转换为这个有序数组中的某个值,在被存储内容和有序数组之间建立了映射关系。这样,下次我们对这个值进行查找时只要使用同一个哈希函数对关键值进行转换,找到这个数组值就可以了。
如果还没有明白是怎么回事的话,那我们来举个例子。假设我们要做个存储结构,需要存储下来三国中的人物,以及他们的详细信息。我们用他们的名字来作为存储 的关键值,例如:刘备,曹操,孙权,关羽,张飞……等等。这个时候我们如果想用一般的方法来查找这些英雄豪杰,需要遍历整个存储空间,如果这些英雄豪杰一 共有n个,那么这时候的时间算法复杂度为O(n)。显然如果n值很大,每次想要找到某个英雄就需要比较长的时间。
此时我们先定义一个大的有序结构数组HashValue[m],用来存放各位英雄豪杰的信息(value值,刘备,曹操...等信息)。然后编写一个哈希函数ChangeToHashValue (name),函数的具体内容就不细说了,反正这个函数会将这些做为关键值的名字转换为HashValue[m]中的某个下标值x。然后可以将英雄的信息放进HashValue[x]中去。这样,可以将所有英雄的信息存储起来。当查询的时候再使用哈希函数ChangeToHashValue(name)得到这个下标值,这样就很容易得到了这个英雄的信息。例如:ChangeToHashValue(刘备)为10,那么就将刘备存储到HashValue [10]里面。当查询的时候再次使用ChangeToHashValue(刘备)得到10,这个时候我们就可以很容易找到刘备的所有信息。在实际应用中如 果我们想把所有的英雄豪杰都存储进系统时,需要定义m>n。就是数组的大小要大于需要存储的信息量,所以说哈希表是一个以空间换取时间的数据结构。
这个时候问题来了,出现了这种情况ChangeToHashValue(关羽)和ChangeToHashValue(张飞)得到的值是一样的,都是250,我们岂不是在存储过程中会遇到麻烦,怎么安排他们二位的地方呢(总不能让二位打一架,谁赢了谁呆在那吧),这就需要一个解决冲突的方法。当遇到这 种情况时我们可以这样处理,先存储好了关羽,当张飞进入系统时会发现关羽已经是250了,那咱就加一位,251得了,这不就解决了。我们查找张飞的时候也 是,一看250不是张飞,那就加个1,就找到了。这时还存在一个问题。直接用ChangeToHashValue(赵云)为251,张飞已经早早占了他的 地方,那就再加1存到252呗。呵呵,这时我们会发现,当哈希函数冲突发生的机率很高时,可能会有一群英雄豪杰在250这个值后面扎堆排队。要命的是查找 的时候,时间算法复杂度早已不是O(1)了(所以我们说理想情况下哈希表的时间算法复杂度为O(1))。
这就是说哈希函数的编写是哈希表的一个关键问题,会涉及到一个存储值在哈希表中的统计分布。如果哈希函数已经定义好了,冲突的解决就成为了改变系统性能的关键因素。其实还有很多种方法来解决冲突情况下的存储和查找问题,不一定非要线性向后排队,如果有好的哈希表冲突的解决方法也能很大程度上提高系统的效 率。
好了,写到这里,哈希表的概念应该搞清楚了吧。今天咱这也是现学现卖,其实我还没有使用过这个数据结构。有不对的地方还请高手指出来,耽误了我自己不怕,免得误导了别人
@总结:
1,哈希表,就是声明一个数组来存放value值(存储的内容),然后声明一个哈希函数,哈希表利用哈希函数将需要存储的内容的关键值转换为这个有序数组中的某个值,在被存储内容和有序数组之间建立了映射关系,这样,下次我们对这个值进行查找时只要使用同一个哈希函数对存储的内容的关键值进行转换,找到这个数组值就可以了。
@值---hash表是一种映射关系,查找值时,先将值经过hash计算,计算后的值在hash表中查找,查找到了,就找到了对应的值。
2,前提是将所有存储的内容计算成唯一的hash值,这样对比才有效。
FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
1.插入排序:每次将一个待排的记录插入到前面的已经排好的队列中的适当位置。
①.直接插入排序
直接排序法在最好情况下(待排序列已按关键码有序),每趟排序只需作1次比较而不需要移动元素。所以n个元素比较次数为n-1,移动次数0。
最差的情况下(逆序),其中第i个元素必须和前面的元素进行比较i次,移动个数i+1,所以总共的比较次数 比较多,就不写出来了
总结:是一种稳定的排序方法,时间复杂度O(n^2),排序过程中只要一个辅助空间,所以空间复杂度O(1)
②.希尔排序
缩小增量排序,对直接插入排序的一种改进
分组插入方法。
总结:是一种不稳定的排序方法,时间复杂度O(n^1.25),空间复杂度O(1)
2.交换排序
①.冒泡排序
最好的情况下,就是正序,所以只要比较一次就行了,复杂度O(n)
最坏的情况下,就是逆序,要比较n^2次才行,复杂度O(n^2)
总结:稳定的排序方法,时间复杂度O(n^2),空间复杂度O(1),当待排序列有序时,效果比较好。
②.快速排序
通过一趟排序将待排的记录分割成独立的两部分,其中一部分记录的关键字均比另一个部分的关键字小,然后再分别对这两个部分记录继续进行排序,以达到整个序列有效。
总结:在所有同数量级O(nlogn)的排序方法中,快速排序是性能最好的一种方法,在待排序列无序时最好。算法的时间复杂度是O(nlogn),最坏的时间复杂度O(n^2),空间复杂度O(nlogn)
3.选择排序
①.直接选择排序
和序列的初始状态无关
总结:时间复杂度O(n^2),无论最好还是最坏
②.堆排序
直接选择排序的改进
总结:时间复杂度O(nlogn),无论在最好还是最坏情况下都是O(nlogn)
4.归并排序
总结:时间复杂度O(nlogn),空间复杂度O(n)
5.基数排序
按组成关键字的各个数位的值进行排序,是分配排序的一种。不需要进行排码值间的比较就能够进行排序。
总结:时间复杂度O(d(n+rd))
总总结:
n比较小的时候,适合 插入排序和选择排序
基本有序的时候,适合 直接插入排序和冒泡排序
n很大但是关键字的位数较少时,适合 链式基数排序
n很大的时候,适合 快速排序 堆排序 归并排序
无序的时候,适合 快速排序
稳定的排序:冒泡排序 插入排序 归并排序 基数排序
复杂度是O(nlogn):快速排序 堆排序 归并排序
辅助空间(大 次大):归并排序 快速排序
好坏情况一样:简单选择(n^2),堆排序(nlogn),归并排序(nlogn)
最好是O(n)的:插入排序 冒泡排序
| 排序法 |
最差时间分析 |
平均时间复杂度 |
稳定度 |
空间复杂度 |
| 冒泡排序 |
O(n2) |
O(n2) |
稳定 |
O(1) |
| 快速排序 |
O(n2) |
O(n*log2n) |
不稳定 |
O(log2n)~O(n) |
| 选择排序 |
O(n2) |
O(n2) |
稳定 |
O(1) |
| 二叉树排序 |
O(n2) |
O(n*log2n) |
不一顶 |
O(n) |
| 插入排序 |
O(n2) |
O(n2) |
稳定 |
O(1) |
| 堆排序 |
O(n*log2n) |
O(n*log2n) |
不稳定 |
O(1) |
| 希尔排序 |
O |
O |
不稳定 |
O(1) |
TTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTT
访问数组中第 n 个数据的时间花费是 O(1) 但是要在数组中查找一个指定的数据则是 O(N)。当向数组中插入或者删除数据的时候,最好的情况是在数组的末尾进行操作,时间复杂度是O(1) ,但是最坏情况是插入或者删除第一个数据,时间复杂度是 O(N) 。在数组的任意位置插入或者删除数据的时候,后面的数据全部需要移动,移动的数据还是和数据个数有关所以总体的时间复杂度仍然是 O(N) 。
在链表中查找第 n 个数据以及查找指定的数据的时间复杂度是 O(N) ,但是插入和删除数据的时间复杂度是 O(1) ,因为只需要调整指针就可以:
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
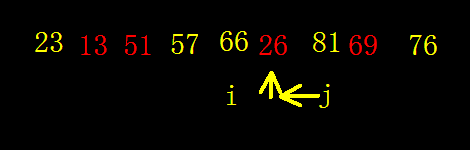
对关键码序列(66,13,51,76,81,26,57,69,23)进行快速排序。
求第一趟划分后的结果。
关键码序列递增。
以第一个元素为划分基准。
【主要方法步骤】如下:
将两个指针i,j分别指向表的起始和最后的位置。
反复操作以下两步:
(1)j逐渐减小,并逐次比较j指向的元素和目标元素的大小,若p(j)
(2)i逐渐增大,并逐次比较i指向的元素和目标元素的大小,若p(i)>T则交换位置。
直到i,j指向同一个值,循环结束。
工具/原料
对关键码序列(66,13,51,76,81,26,57,69,23)进行快速排序。
方法/步骤
-
首先设置两个变量i,j。
分别指向序列的首尾元素。
-
该例子是以第一个元素为基准,从小到大进行排列。
让j从后向前进行查询,直到找到第一个小于66的元素。
则将最后一个j指向的数23,和i指向的66交换位置。
然后将i从前向后查询,直到找到第一个大于66的元素76.
-
将76和66位置互换。
让j从后向前进行查询,直到找到第一个小于66的元素57
-
-
然后将i从前向后查询,直到找到第一个大于66的元素81.
-
将81和66交换位置。
让j从后向前进行查询,直到找到第一个小于66的元素26
-
将26和66交换位置。
此时i,j都同时指向了目标元素66.
查找停止。
所得到的序列就是第一趟排序的序列
HEHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHE八大排序算法http://blog.csdn.net/yxb_yingu/article/list/2
HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
//冒泡排序
public static void bubbleSort(int[] array){
boolean isExchange = false;
for (int i = 0; i < array.length - 1; i++) {//最大趟数length-1趟
for (int j = 0; j < array.length - 1 - i; j++) {//每次最大数放到后面,则每次减少比较次数
if (array[j]> array[j +1]) {//相邻两个数比较,将较大的放到后面
array[j] ^= array[j + 1];
array[j + 1] ^= array[j];
array[j] ^= array[j + 1];
isExchange = true;
}
}
if (!isExchange) {//如果没有交换,说明中途已经排序完成,可以终止循环,直接退出,优化算法
break;
}
}
}
//选择排序
public static void chooseSort(int[] array){
for (int i = 0; i < array.length - 1; i++) {//循环length - 1趟
int minIndex = i;//将本趟的第一个数暂时定义为最小值,则其下标为最小值下标
for (int j = i; j < array.length; j++) {//每次隔过前面的数,从第i个数开始循环;
if (array[minIndex] > array[j]) {
minIndex = j;//拿最小数跟后面的所有数比较,发现有比它小的,记录下标;
}
}
if (minIndex != i) {//如果最小数不是本身,说明找到了另外的最小数,通过交换将这个最小数放到本趟循环的最前面;
array[i] ^= array[minIndex];//通过异或运算交换两个数的数值;
array[minIndex] ^= array[i];
array[i] ^= array[minIndex];
}
}
}
//直接插入排序
public static void insertSort(int[] array){
for (int i = 1; i < array.length; i++) {
int temp = array[i];//取出本趟第一个数字作为基准
int j = i - 1;
while (j >= 0 && temp < array[j]) {//从现在的位置往前依次寻找
array[j + 1] = array[j];
j --;
}
array[j + 1] = temp;//找到合适的位置插入
}
}
//快速排序主方法
public static void quickSort(int[] array, int low, int high){
if (low < high) {
int mid = findMid(array, low, high);//将第一个数作为基准,将数组分成前后两部分
quickSort(array, low, mid - 1);//递归调用将左半部分再一次往下分,直至左半部分完成排序
quickSort(array, mid + 1, high);//递归调用将右半部分再一次往下分,直至右半部分完成排序
}
}
//将第一个数作为基准,将数组分成前后两部分--填坑法
public static int findMid(int[] array, int low, int high){
int temp = array[low];//将第一个数作为基准拿出,拿出留下一个坑
while (low < high) {
while (low < high && temp <= array[high]) {//从右开始找
high --;
}
if (low < high) {//发现比基准数字小的,就把它填到之前基准数字留下的坑里
array[low ++] = array[high];
}
while (low < high && temp >= array[low]) {//从左开始找
low ++;
}
if (low < high) {//发现比基准数字大的,就把它填到之前被拿出数字留下的坑里
array[high --] = array[low];
}
}
array[low] = temp;//将基准数字放到中间将左右分成两部分
return low;//返回基准数字的下标
}
//希尔排序
public static void shellSort(int[] array){
int d = array.length / 2;
while(d >= 1){
//采用插入排序的思想将增量间隔的数字排序,当增量为1时,即跟直接插入排序相同
for (int i = d; i < array.length; i++) {
int temp = array[i];
int j = i - d;
while(j >= 0 && temp < array[j]){
array[j + d] = array[j];
j -= d;
}
array[j + d] = temp;
}
d /= 2;//增量每次减小
}
}
//归并排序主方法
public static void mergeSort(int[] array){
//拿出三个list作为工具完成归并
ArrayList list1 = new ArrayList();
ArrayList list2 = new ArrayList();
ArrayList list3 = new ArrayList();
for (int gap = 1; gap < array.length ; gap *= 2) {//运行趟数,每次将被归并的数组都会变大,直至完全归并为一个数组
for (int i = 0; i < array.length; i++) {
if (list1.size() < gap) {//往第一个list里加数
list1.add(array[i]);
}else if (list2.size() < gap){//往第二个list里加数
list2.add(array[i]);
}
if ((list1.size() == gap && list2.size() == gap) || (list1.size() == gap && list2.size() < gap && i == array.length - 1)) {
merger(list1, list2, list3);//将前面两个list里的数归并后放入第三个list
list1.clear();//清空第一个list循环使用
list2.clear();//清空第二个list循环使用
}
}
//将已达到目的的第三个list里的数复制到数组里,完成一趟排序;
for (int i = 0; i < array.length; i++) {
array[i] = list3.get(i);
}
list3.clear();
}
}
//将两个有序的数组归并成一个有序的数组的方法:传入list1,list2,最后得到list3
public static void merger(ArrayList list1, ArrayList list2, ArrayList list3){
int m = 0;
int n = 0;
while(m < list1.size() && n < list2.size()){
while (m < list1.size() && n < list2.size() && list1.get(m) < list2.get(n)) {
list3.add(list1.get(m));
m ++;
}
while(m < list1.size() && n < list2.size() && list1.get(m) >= list2.get(n)){
list3.add(list2.get(n));
n ++;
}
}
while (m < list1.size()) {
list3.add(list1.get(m));
m ++;
}
while (n < list2.size()) {
list3.add(list2.get(n));
n ++;
}
}
希尔排序

归并排序
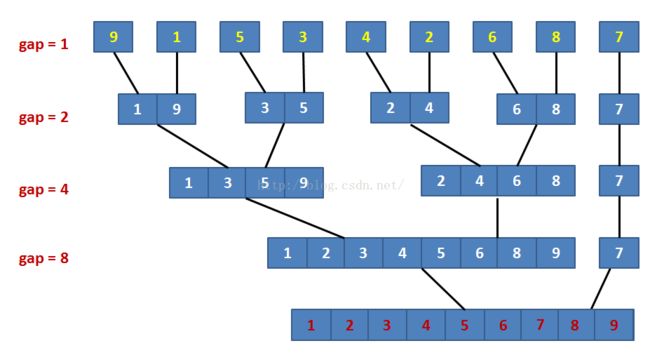
快速排序

ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
最优情况下时间复杂度
快速排序最优的情况就是每一次取到的元素都刚好平分整个数组(很显然我上面的不是);
此时的时间复杂度公式则为:T[n] = 2T[n/2] + f(n);T[n/2]为平分后的子数组的时间复杂度,f[n] 为平分这个数组时所花的时间;
下面来推算下,在最优的情况下快速排序时间复杂度的计算(用迭代法):
T[n] = 2T[n/2] + n ----------------第一次递归
令:n = n/2 = 2 { 2 T[n/4] + (n/2) } + n ----------------第二次递归
= 2^2 T[ n/ (2^2) ] + 2n
令:n = n/(2^2) = 2^2 { 2 T[n/ (2^3) ] + n/(2^2)} + 2n ----------------第三次递归
= 2^3 T[ n/ (2^3) ] + 3n
......................................................................................
令:n = n/( 2^(m-1) ) = 2^m T[1] + mn ----------------第m次递归(m次后结束)
当最后平分的不能再平分时,也就是说把公式一直往下跌倒,到最后得到T[1]时,说明这个公式已经迭代完了(T[1]是常量了)。
得到:T[n/ (2^m) ] = T[1] ===>> n = 2^m ====>> m = logn;
T[n] = 2^m T[1] + mn ;其中m = logn;
T[n] = 2^(logn) T[1] + nlogn = n T[1] + nlogn = n + nlogn ;其中n为元素个数
又因为当n >= 2时:nlogn >= n (也就是logn > 1),所以取后面的 nlogn;
综上所述:快速排序最优的情况下时间复杂度为:O( nlogn )
最差情况下时间复杂度
最差的情况就是每一次取到的元素就是数组中最小/最大的,这种情况其实就是冒泡排序了(每一次都排好一个元素的顺序)
这种情况时间复杂度就好计算了,就是冒泡排序的时间复杂度:T[n] = n * (n-1) = n^2 + n;
综上所述:快速排序最差的情况下时间复杂度为:O( n^2 )
平均时间复杂度
快速排序的平均时间复杂度也是:O(nlogn)
空间复杂度
其实这个空间复杂度不太好计算,因为有的人使用的是非就地排序,那样就不好计算了(因为有的人用到了辅助数组,所以这就要计算到你的元素个数了);我就分析下就地快速排序的空间复杂度吧;
首先就地快速排序使用的空间是O(1)的,也就是个常数级;而真正消耗空间的就是递归调用了,因为每次递归就要保持一些数据;
最优的情况下空间复杂度为:O(logn) ;每一次都平分数组的情况
最差的情况下空间复杂度为:O( n ) ;退化为冒泡排序的情况
还有个问题就是怎么取哨兵元素才能不会让这个算法退化到冒泡排序,想想了还是算了吧,越深入研究就会有越多感兴趣的问题,而我又不是搞算法分析的,所以就先这样吧。
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
在二叉排序树中,每个结点的值均大于其左子树上所有结点的值,小于其右子树上所有结点的值,对二叉排序树进行中序遍历得到一个有序序列。所以,二叉排序树是结点之间满足一定次序关系的二叉树;
堆是一个完全二叉树,并且每个结点的值都大于或等于其左右孩子结点的值(这里的讨论以大根堆为例),所以,堆是结点之间满足一定次序关系的完全二叉树。
具有n个结点的二叉排序树,其深度取决于给定集合的初始排列顺序,最好情况下其深度为log n(表示以2为底的对数),最坏情况下其深度为n;
具有n个结点的堆,其深度即为堆所对应的完全二叉树的深度log n 。
在二叉排序树中,某结点的右孩子结点的值一定大于该结点的左孩子结点的值;在堆中却不一定,堆只是限定了某结点的值大于(或小于)其左右孩子结点的值,但没有限定左右孩子结点之间的大小关系。
在二叉排序树中,最小值结点是最左下结点,其左指针为空;最大值结点是最右下结点,其右指针为空。在大根堆中,最小值结点位于某个叶子结点,而最大值结点是大根堆的堆顶(即根结点)。
二叉排序树是为了实现动态查找而设计的数据结构,它是面向查找操作的,在二叉排序树中查找一个结点的平均时间复杂度是O(log n);
堆是为了实现排序而设计的一种数据结构,它不是面向查找操作的,因而在堆中查找一个结点需要进行遍历,其平均时间复杂度是O(n)。
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
1,红黑树与平衡二叉树区别?
2,操作系统中, 信号量与互斥锁使用与区别?
“信号量用在多线程多任务同步的,一个线程完成了某一个动作就通过信号量告诉别的线程,别的线程再进行某些动作(大家都在semtake的时候,就阻塞在 哪里)。而互斥锁是用在多线程多任务互斥的,一个线程占用了某一个资源,那么别的线程就无法访问,直到这个线程unlock,其他的线程才开始可以利用这 个资源。比如对全局变量的访问,有时要加锁,操作完了,在解锁。有的时候锁和信号量会同时使用的”
也就是说,信号量不一定是锁定某一个资源,而是流程上的概念,比如:有A,B两个线程,B线程要等A线程完成某一任务以后再进行自己下面的步骤,这个任务 并不一定是锁定某一资源,还可以是进行一些计算或者数据处理之类。而线程互斥量则是“锁住某一资源”的概念,在锁定期间内,其他线程无法对被保护的数据进 行操作。在有些情况下两者可以互换。
两者之间的区别:
作用域
信号量: 进程间或线程间(linux仅线程间的无名信号量pthread semaphore)
互斥锁: 线程间
上锁时
信号量: 只要信号量的value大于0,其他线程就可以sem_wait成功,成功后信号量的value减一。若value值不大于0,则sem_wait使得线程阻塞,直到sem_post释放后value值加一,但是sem_wait返回之前还是会将此value值减一
互斥锁: 只要被锁住,其他任何线程都不可以访问被保护的资源
以下是信号灯(量)的一些概念:
信号灯与互斥锁和条件变量的主要不同在于”灯”的概念,灯亮则意味着资源可用,灯灭则意味着不可用。如果说后两中同步方式侧重于”等待”操作,即资 源不可用的话,信号灯机制则侧重于点灯,即告知资源可用;
没有等待线程的解锁或激发条件都是没有意义的,而没有等待灯亮的线程的点灯操作则有效,且能保持 灯亮状态。当然,这样的操作原语也意味着更多的开销。
信号灯的应用除了灯亮/灯灭这种二元灯以外,也可以采用大于1的灯数,以表示资源数大于1,这时可以称之为多元灯。
1. 创建和 注销
POSIX信号灯标准定义了有名信号灯和无名信号灯两种,但LinuxThreads的实现仅有无名灯,同时有名灯除了总是可用于多进程之间以外,在使用上与无名灯并没有很大的区别,因此下面仅就无名灯进行讨论。
int sem_init(sem_t *sem, int pshared, unsigned int value)
这是创建信号灯的API,其中value为信号灯的初值,pshared表示是否为多进程共享而不仅仅是用于一个进程。LinuxThreads没有实现 多进程共享信号灯,因此所有非0值的pshared输入都将使sem_init()返回-1,且置errno为ENOSYS。初始化好的信号灯由sem变 量表征,用于以下点灯、灭灯操作。
int sem_destroy(sem_t * sem)
被注销的信号灯sem要求已没有线程在等待该信号灯,否则返回-1,且置errno为EBUSY。除此之外,LinuxThreads的信号灯 注销函数不做其他动作。
sem_destroy destroys a semaphore object, freeing the resources it might hold. No threads should be waiting on the
semaphore at the time sem_destroy is called. In the LinuxThreads implementation, no resources are associated with
semaphore objects, thus sem_destroy actually does nothing except checking that no thread is waiting on the semaphore.
2. 点灯和灭灯
int sem_post(sem_t * sem)
点灯操作将信号灯值原子地加1,表示增加一个可访问的资源。
int sem_wait(sem_t * sem)
int sem_trywait(sem_t * sem)
sem_wait()为等待灯亮操作,等待灯亮(信号灯值大于0),然后将信号灯原子地减1,并返回。sem_trywait()为sem_wait()的非阻塞版,如果信号灯计数大于0,则原子地减1并返回0,否则立即返回-1,errno置为EAGAIN。
3. 获取灯值
int sem_getvalue(sem_t * sem, int * sval)
读取sem中的灯计数,存于*sval中,并返回0。
4. 其他
sem_wait()被实现为取消点。(取消点事什么意思???)
sem_wait is a cancellation point.
取消点的含义:
当用pthread_cancel()一个线程时,这个要求会被pending起来,当被cancel的线程走到下一个cancellation point时,线程才会被真正cancel掉。
而且在支持原子”比较且交换CAS”指令的体系结构上,sem_post()是唯一能用于异步信号处理函数的POSIX异步信号 安全的API。
On processors supporting atomic compare-and-swap (Intel 486, Pentium and later, Alpha, PowerPC, MIPS II, Motorola 68k),
the sem_post function is async-signal safe and can therefore be called from signal handlers. This is the only thread syn-
chronization function provided by POSIX threads that is async-signal safe.
On the Intel 386 and the Sparc, the current LinuxThreads implementation of sem_post is not async-signal safe by lack of
the required atomic operations.
互斥量(Mutex)
互斥量表现互斥现象的数据结构,也被当作二元信号灯。一个互斥基本上是一个多任务敏感的二元信号,它能用作同步多任务的行为,它常用作保护从中断来的临界段代码并且在共享同步使用的资源。

Mutex本质上说就是一把锁,提供对资源的独占访问,所以Mutex主要的作用是用于互斥。Mutex对象的值,只有0和1两个值。这两个值也分别代表了Mutex的两种状态。值为0, 表示锁定状态,当前对象被锁定,用户进程/线程如果试图Lock临界资源,则进入排队等待;值为1,表示空闲状态,当前对象为空闲,用户进程/线程可以Lock临界资源,之后Mutex值减1变为0。
Mutex可以被抽象为四个操作:
- 创建 Create
- 加锁 Lock
- 解锁 Unlock
- 销毁 Destroy
Mutex被创建时可以有初始值,表示Mutex被创建后,是锁定状态还是空闲状态。在同一个线程中,为了防止死锁,系统不允许连续两次对Mutex加锁(系统一般会在第二次调用立刻返回)。也就是说,加锁和解锁这两个对应的操作,需要在同一个线程中完成。
不同操作系统中提供的Mutex函数:
| 动作\系统 |
Win32 |
Linyx |
Solaris |
| 创建 |
CreateMutex |
pthread_mutex_init |
mutex_init |
| 加锁 |
WaitForSingleObject |
pthread_mutex_lock |
mutex_lock |
| 解锁 |
ReleaseMutex |
pthread_mutex_unlock |
mutex_unlock |
| 销毁 |
CloseHandle |
pthread_mutex_destroy |
mutex_destroy |
信号量
信号量(Semaphore),有时被称为信号灯,是在多线程环境下使用的一种设施, 它负责协调各个线程, 以保证它们能够正确、合理的使用公共资源。
信号量可以分为几类:
² 二进制信号量(binary semaphore):只允许信号量取0或1值,其同时只能被一个线程获取。
² 整型信号量(integer semaphore):信号量取值是整数,它可以被多个线程同时获得,直到信号量的值变为0。
² 记录型信号量(record semaphore):每个信号量s除一个整数值value(计数)外,还有一个等待队列List,其中是阻塞在该信号量的各个线程的标识。当信号量被释放一个,值被加一后,系统自动从等待队列中唤醒一个等待中的线程,让其获得信号量,同时信号量再减一。
信号量通过一个计数器控制对共享资源的访问,信号量的值是一个非负整数,所有通过它的线程都会将该整数减一。如果计数器大于0,则访问被允许,计数器减1;如果为0,则访问被禁止,所有试图通过它的线程都将处于等待状态。
计数器计算的结果是允许访问共享资源的通行证。因此,为了访问共享资源,线程必须从信号量得到通行证, 如果该信号量的计数大于0,则此线程获得一个通行证,这将导致信号量的计数递减,否则,此线程将阻塞直到获得一个通行证为止。当此线程不再需要访问共享资源时,它释放该通行证,这导致信号量的计数递增,如果另一个线程等待通行证,则那个线程将在那时获得通行证。
Semaphore可以被抽象为五个操作:
- 创建 Create
- 等待 Wait:
线程等待信号量,如果值大于0,则获得,值减一;如果只等于0,则一直线程进入睡眠状态,知道信号量值大于0或者超时。
-释放 Post
执行释放信号量,则值加一;如果此时有正在等待的线程,则唤醒该线程。
-试图等待 TryWait
如果调用TryWait,线程并不真正的去获得信号量,还是检查信号量是否能够被获得,如果信号量值大于0,则TryWait返回成功;否则返回失败。
-销毁 Destroy
信号量,是可以用来保护两个或多个关键代码段,这些关键代码段不能并发调用。在进入一个关键代码段之前,线程必须获取一个信号量。如果关键代码段中没有任何线程,那么线程会立即进入该框图中的那个部分。一旦该关键代码段完成了,那么该线程必须释放信号量。其它想进入该关键代码段的线程必须等待直到第一个线程释放信号量。为了完成这个过程,需要创建一个信号量,然后将Acquire Semaphore VI以及Release Semaphore VI分别放置在每个关键代码段的首末端。确认这些信号量VI引用的是初始创建的信号量。
| 动作\系统 |
Win32 |
POSIX |
| 创建 |
CreateSemaphore |
sem_init |
| 等待 |
WaitForSingleObject |
sem _wait |
| 释放 |
ReleaseMutex |
sem _post |
| 试图等待 |
WaitForSingleObject |
sem _trywait |
| 销毁 |
CloseHandle |
sem_destroy |
互斥量和信号量的区别
1. 互斥量用于线程的互斥,信号量用于线程的同步。
这是互斥量和信号量的根本区别,也就是互斥和同步之间的区别。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源
2. 互斥量值只能为0/1,信号量值可以为非负整数。
也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量是,也可以完成一个资源的互斥访问。
3. 互斥量的加锁和解锁必须由同一线程分别
对应使用,信号量可以由一个线程释放,
另一个线程得到。
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
由此我们可以得出结论:对于给定的黑色高度为 N 的红黑树,从根到叶子节点的最短路径长度为 N-1,最长路径长度为 2 * (N-1)。
提示:排序二叉树的深度直接影响了检索的性能,正如前面指出,当插入节点本身就是由小到大排列时,排序二叉树将变成一个链表,这种排序二叉树的检索性能最低:N 个节点的二叉树深度就是 N-1。
红黑树通过上面这种限制来保证它大致是平衡的——因为红黑树的高度不会无限增高,这样保证红黑树在最坏情况下都是高效的,不会出现普通排序二叉树的情况。
由于红黑树只是一个特殊的排序二叉树,因此对红黑树上的只读操作与普通排序二叉树上的只读操作完全相同,只是红黑树保持了大致平衡,因此检索性能比排序二叉树要好很多。
但在红黑树上进行插入操作和删除操作会导致树不再符合红黑树的特征,因此插入操作和删除操作都需要进行一定的维护,以保证插入节点、删除节点后的树依然是红黑树
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
史上最通俗易懂的关于二叉查找树、平衡二叉树、红黑树的关系讲解
这些关系是为了后面集合中TreeMap的学习打下基础,讨论TressMap删除、插入的效率就是以红黑树为基础。而红黑树又是优化了的二叉查找树。
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。
先来看一下基本的概念:
第一、二叉查找树(Binary Search Tree)和二叉排序树(Binary Sort Tree)都是一样的。
第二、二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:
若左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值;若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;左、右子树也分别为二叉排序树;没有键值相等的节点(no duplicate nodes)。
因为一棵由n个结点随机构造的二叉查找树的高度为lgn,所以顺理成章,二叉查找树的一般操作的执行时间为O(lgn)。但二叉查找树若退化成了一棵具有n个结点的线性链后,则这些操作最坏情况运行时间为O(n)。
第三、平衡二叉树:AVL树是根据它的发明者G. M. Adelson-Velskii和E. M. Landis命名的。AVL树本质上还是一棵二叉搜索树,它的特点是:
本身首先是一棵二叉查找树。带有平衡条
件:每个结点的左右子树的高度之差的绝
对值(平衡因子)最多为1。
第四、红黑树:虽然本质上是一棵二叉查
找树,但它在二叉查找树的基础上增加了
着色和相关的性质使得红黑树相对平衡,
从而保证了红黑树的查找、插入、删除的
时间复杂度最坏为O(log n)。
算法导论里是这样定义一棵红黑树的,
每个结点或是红色的,或是黑色的
根节点是黑色的每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。如果一个结点是红的,那么它的两个儿子都是黑的。对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。