《CornerNet:Detecting Objects as Paired Keypoints》论文笔记
1. 概述
这篇文章提出了CornerNet的目标检测模型,该模型是一个直通检测检测模型,与Faster RCNN那种两阶段的检测模型不一样,更类似于SSD与YOLO。但是与SSD等模型不同的是其并不使用anchor boxes,而是提出了一种叫做corner pooling的操作帮助网络更好地定位目标。在COCO数据集上的表现性能超过了所有现有的检测网路。
anchor boxes机制在现有两阶段以及直通检测网络模型中被广泛使用,这些模型中也是通过anchor的检出来进行边界的回归。但是anchor也会带来其的缺点,该文章中大体给出了两点:
1)通常需要大量的anchor,在DSSD中需要40k,而在RetinaNet中则需要100k。这么大量的anchor就带来了正例anchor的数量与负例anchor的比例及其不成比例,从而降低了网络的训练速度。
2)anchor boxes的引入带来了许多的超参数,并且需要进行细致设计。包括anchor boxes的数量、尺寸、长宽比例。特别是在单一网络在多尺度进行预测的情况下会变得复杂,每个尺度都需要独立设计。
下图是这篇文章中使用的网络结构可以描述为:
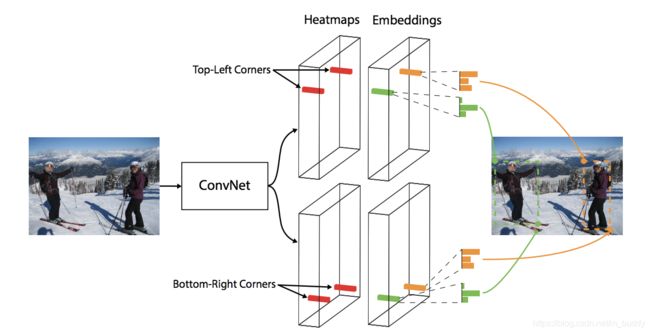
在该方法中舍弃传统的anchor boxes思路,提出CornerNet模型预测目标边界框的左上角和右下角一对顶点。使用单一卷积模型生成热点图和连接矢量:所有目标的左上角和所有目标的右下角热点图,每个顶点的连接矢量(embedding vector)。也就是该方法在卷积的输出结果上,分别预测边界框的左上角与右下角,之后寻找它们之间的对应关系。
主要思路其实来源于一篇多人姿态估计的论文。基于CNN的2D多人姿态估计方法,通常有2个思路(Bottom-Up Approaches和Top-Down Approaches):
Top-Down framework:就是先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成每个人的姿态,缺点是受人体检测框影响较大,代表算法有RMPE;
Bottom-Up framework:就是先对整个图片进行每个人体关键点部件的检测,再将检测到的人体部位拼接成每个人的姿态,代表方法就是openpose。
在文章中给出了两个创新点:
1)文章将目标检测上升到方法论,基于多人姿态估计的Bottom-Up思想,首先同时预测定位框的顶点对(左上角和右下角)热点图和embedding vector,根据embedding vector对顶点进行分组,论文中提到分组的依据是同目标的两个角点距离是很小的。
2)文章提出了corner pooling用于定位顶点。自然界的大部分目标是没有边界框也不会有矩形的顶点,依top-left corner pooling 为例,对每个channel,分别提取特征图对应位置处的水平和垂直方向的最大值,然后求和。

3)文中提出的CornerNet模型基于hourglass架构,使用focal loss的变体训练神经网络。
为什么基于角点的检测要比基于anchor boxes的检测效果更好,这里假设了两个原因:
1)anchor boxes的中心是依赖于目标的四条边,但是角点却只需要两个边,而且还是使用了corner pooling,因而表现比anchor好。
2)采用了更加高效的空间检测框机制,这里只使用 O ( w ∗ h ) O(w*h) O(w∗h)个角点就代表了 O ( W 2 ∗ h 2 ) O(W^2*h^2) O(W2∗h2)的可能检测框。
2. CornerNet
CornerNet的整体结构:

上面的图中给出的是CornerNet的网络结构图,可以看出CornerNet模型架构包含三部分,Hourglass Network,Bottom-right corners&Top-left Corners Heatmaps和Prediction Module。
其中Hourglass Network是人体姿态估计的典型架构,论文堆叠两个Hourglass Network生成Top-left和Bottom-right corners,每一个corners都包括corners Pooling,以及对应的Heatmaps, Embeddings vector和offsets(为了提升框的精度)。embedding vector使相同目标的两个顶点(左上角和右下角)距离最短, offsets用于调整生成更加紧密的边界定位框。最后预测框也是在这三个生成的结果的基础上使用后处理算法进行实现的。
2.1 Detecting Corners
Paper模型生成的heatmaps包含C channels(C是目标的类别,没有background channel),每个channel是二进制掩膜,表示相应类别的顶点位置。

对于每个顶点,只有一个ground-truth,其他位置都是负样本。但是网络的输出并不会从开始就与上图标注的绿色虚线重合,因而是按照了一定的策略来进行组合的。具体来讲是这样的:在训练过程,模型减少负样本,在每个ground-truth顶点设定半径r区域内都是正样本,这是因为落在半径r区域内的顶点依然可以生成有效的边界定位框,论文中设置 I o U = 0.7 IoU=0.7 IoU=0.7。那么对于与实际的定位有偏移的网络输出论文使用了惩罚,是按照没有归一化的而为高斯函数 e − x 2 + y 2 2 σ 2 e^{-\frac{x^2+y^2}{2\sigma^2}} e−2σ2x2+y2设置的,其中 σ = 1 3 \sigma=\frac{1}{3} σ=31,中心坐标是标注的角点定位。
p c i j p_{cij} pcij表示类别为c,坐标是 ( i , j ) (i,j) (i,j)的预测热点图, y c i j y_{cij} ycij表示相应位置的ground-truth,其指融合了前面的提到的高斯半径。论文提出变体Focal loss表示检测目标的损失函数:

其中参数 N N N是图片中目标的总数,参数 α = 2 \alpha=2 α=2与 β = 4 \beta=4 β=4适用于控制每个部分的贡献程度。
在卷积神经网络中存在着下采样层,这样从原始的图像输入到最后的heatmap产生的这个过程会累计误差,特别是在对一些小目标的物体进行检测的时候,这样的误差就无法接受了,因而文章引入了偏移修正来修正它:

然后使用L1损失与原图标注的位置对其进行修正:

最后的网络损失函数是上面的几个相加的形式:
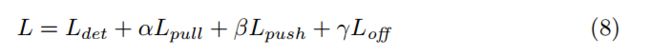
其中, α = β = 0.1 , γ = 1 \alpha=\beta=0.1,\gamma=1 α=β=0.1,γ=1。
2.2 Grouping Corners
输入图像会有多个目标,相应生成多个目标的左上角和右下角顶点。对顶点进行分组,论文引入Associative Embedding的思想,模型在训练阶段为每个corner预测相应的embedding vector,通过embedding vector使同一目标的顶点对距离最短,即是模型可以通过embedding vector为每个顶点分组。
模型训练 L p u l l 损 失 函 数 L_{pull}损失函数 Lpull损失函数使同一目标的顶点进行分组, L p u s h 损 失 函 数 L_{push}损失函数 Lpush损失函数用于分离不同目标的顶点。 e t k e_{tk} etk是左下角的顶点, e b k e_{bk} ebk是右下角的顶点。
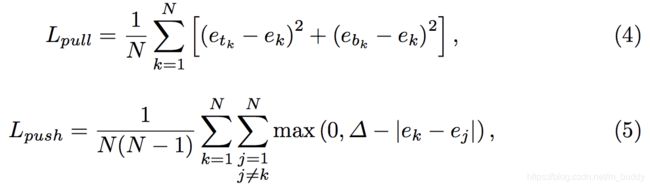
2.3 Corner Pooling
2.3.1 top-left corner
一般来说在heatmap上并不存在直观的选择依据,因而文章中采用了corner pooling的方法。对于在左上角的角点(顶点)使用其在水平与垂直方向上分分别使用max pooling,然后对其结果合并来实现角点的定位,其运算流程可以通过下面这幅图来进行说明

对于要判定点 ( x , y ) (x,y) (x,y)是不是左上角的角点, 这里使用 f t f_t ft与 f l f_l fl去代表这个左上角点pooling layer的特征图,使用 f t i , j f_{t_{i,j}} fti,j与 f l i , j f_{l_{i,j}} fli,j来代表在位置 ( i , j ) (i,j) (i,j)处 f t f_t ft与 f l f_l fl的特征向量。对于输入大小为 W ∗ H W*H W∗H大小的特征图,计算位置 ( i , j ) (i,j) (i,j)处到 ( i , H ) (i,H) (i,H)在 f t f_t ft的向量 t i , j t_{i,j} ti,j,计算位置 ( i , j ) (i,j) (i,j)处到 ( j , W ) (j,W) (j,W)在 f l f_l fl的向量 l i , j l_{i,j} li,j,最后再将两个加起来作为最后的输出。
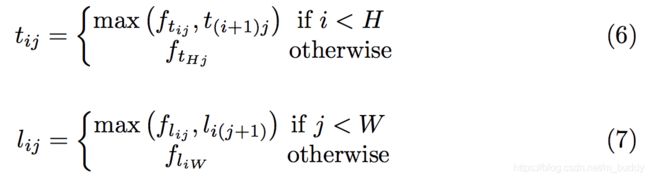
2.3.2 bottom-right corner
bottom-right corner的计算与上面top-left的计算是类似的。它在 ( 0 , j ) (0,j) (0,j)到 ( i , j ) (i,j) (i,j)的特征图与 ( i , 0 ) (i,0) (i,0)到 ( i , j ) (i,j) (i,j)的特征图上进行最大池化操作之后再将两者得到的结果相加得到最后的结果。
2.3.3 预测模块
预测模块使用的结构使用ResNet与卷积组合的形式,其结构(top-left corner部分)如下。最后预测生成Heatmap、Embeddings、Offsset。

2.4 Hourglass Network
Hourglass Network同时包含了bottom-up(from high resolutions to low resolutions)和top-down (from low resolutions to high resolutions)。而且,整个网络有多个bottom-up和top-down过程。这样设计的目的是在各个尺度下抓取信息。针对目标检测任务,论文调整了Hourglass一些策略。
3. 论文效果

**PS:**在这篇文章涉及到了SHM(Stack Hourglass Model),不了解的小伙伴可以参考这篇文章快速了解:Stacked Hourglass Networks - 堆叠沙漏网络结构详解