学习笔记|Pytorch使用教程21(TensorBoard使用(二))
学习笔记|Pytorch使用教程21
本学习笔记主要摘自“深度之眼”,做一个总结,方便查阅。
使用Pytorch版本为1.2
- add_image and torchvision.utils.make_grid
- AlexNet卷积核与特征图可视化
- add_graph and torchsummary
一.add_image and torchvision.utils.make_grid
1.add_image()
功能:记录图像
![]()
- tag:图像的标签名,图的唯一标识
- img_tensor :图像数据,注意尺度
- global_step : x轴
- dataformats :数据形式,CHW, HWC,HW
测试代码:
import os
import torch
import time
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.utils as vutils
from tools.my_dataset import RMBDataset
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
from tools.common_tools import set_seed
from model.lenet import LeNet
set_seed(1) # 设置随机种子
# ----------------------------------- 3 image -----------------------------------
# flag = 0
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# img 1 random
fake_img = torch.randn(3, 512, 512)
writer.add_image("fake_img", fake_img, 1)
time.sleep(1)
# img 2 ones
fake_img = torch.ones(3, 512, 512)
time.sleep(1)
writer.add_image("fake_img", fake_img, 2)
# img 3 1.1
fake_img = torch.ones(3, 512, 512) * 1.1
time.sleep(1)
writer.add_image("fake_img", fake_img, 3)
# img 4 HW
fake_img = torch.rand(512, 512)
writer.add_image("fake_img", fake_img, 4, dataformats="HW")
# img 5 HWC
fake_img = torch.rand(512, 512, 3)
writer.add_image("fake_img", fake_img, 5, dataformats="HWC")
writer.close()
查看可视化输出:
查看img1:fake_img = torch.randn(3, 512, 512)
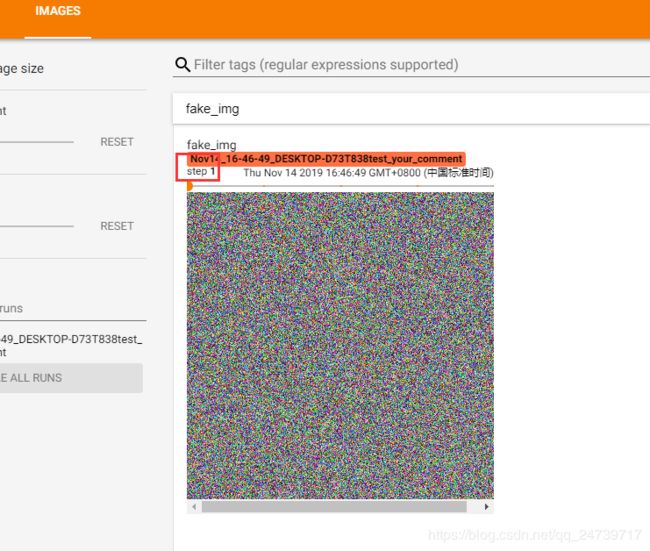
查看img2:fake_img = torch.ones(3, 512, 512)
这里的 是一个全为一的tensor,会认为这个tensor的区间为[0, 1],所以会自动 *255,使其区间为[0, 255],乘以255之后,图像的像素值为255,所以图像是白色的。

查看img3:fake_img = torch.ones(3, 512, 512) * 1.1
由于乘以1.1之后,最大值大于1了,认为区间为[0, 255], 所以图像是黑色的。
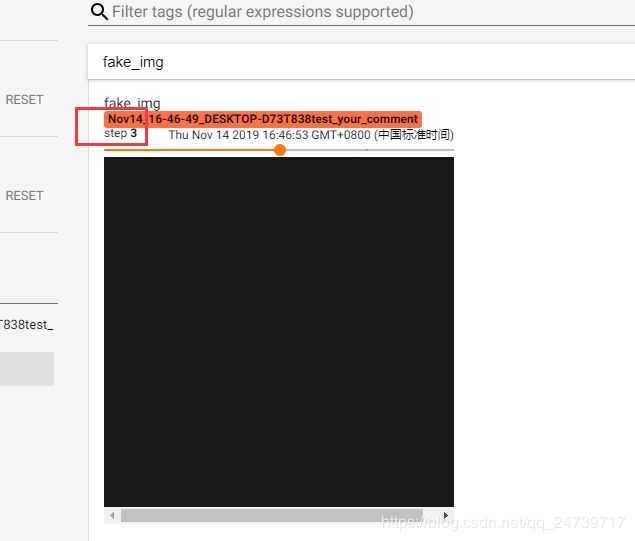
查看img4:fake_img = torch.rand(512, 512)
这是一张单通道的灰度图
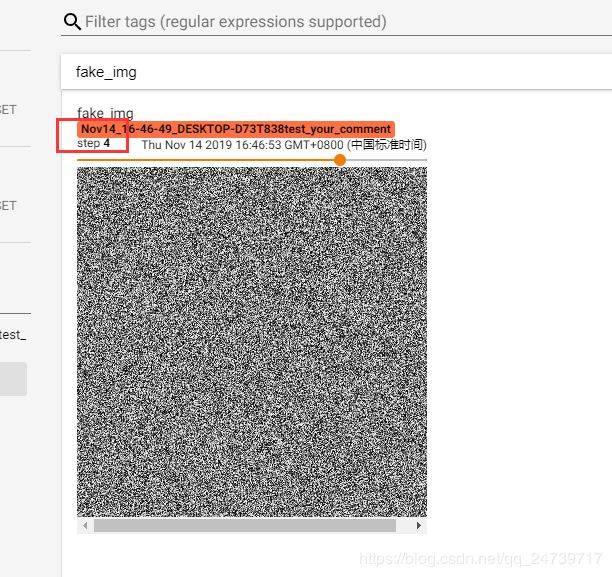
查看img5:fake_img = torch.rand(512, 512, 3)
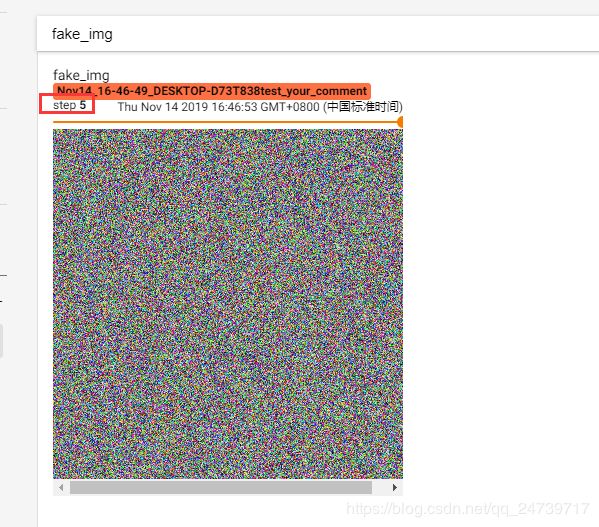
2.torchvision.utils.make_ grid
功能:制作网格图像

- tensor :图像数据,BCH*W形式
- nrow:行数(列数自动计算)
- padding :图像间距(像素单位)
- normalize :是否将像素值标准化
- range:标准化范围
- scale_each:是否单张图维度标准化
- pad_value : padding的像素值
测试代码:
# ----------------------------------- 4 make_grid -----------------------------------
# flag = 0
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
# train_dir = "path to your training data"
transform_compose = transforms.Compose([transforms.Resize((32, 64)), transforms.ToTensor()])
train_data = RMBDataset(data_dir=train_dir, transform=transform_compose)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
data_batch, label_batch = next(iter(train_loader))
# img_grid = vutils.make_grid(data_batch, nrow=4, normalize=True, scale_each=True)
img_grid = vutils.make_grid(data_batch, nrow=4, normalize=False, scale_each=False)
writer.add_image("input img", img_grid, 0)
writer.close()
可视化结果:
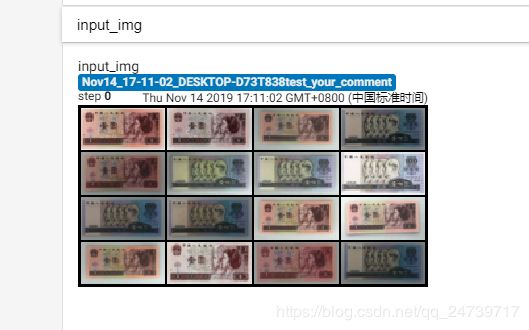
当设置:img_grid = vutils.make_grid(data_batch, nrow=4, normalize=True, scale_each=True)

二.AlexNet卷积核与特征图可视化
1.卷积核可视化
测试代码:
import torch.nn as nn
from PIL import Image
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import torchvision.utils as vutils
from tools.common_tools import set_seed
import torchvision.models as models
set_seed(1) # 设置随机种子
# ----------------------------------- kernel visualization -----------------------------------
# flag = 0
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
alexnet = models.alexnet(pretrained=True)
kernel_num = -1
vis_max = 1
for sub_module in alexnet.modules():
if isinstance(sub_module, nn.Conv2d):
kernel_num += 1
if kernel_num > vis_max:
break
kernels = sub_module.weight
c_out, c_int, k_w, k_h = tuple(kernels.shape)
for o_idx in range(c_out):
kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1) # make_grid需要 BCHW,这里拓展C维度
kernel_grid = vutils.make_grid(kernel_idx, normalize=True, scale_each=True, nrow=c_int)
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)
kernel_all = kernels.view(-1, 3, k_h, k_w) # 3, h, w
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, w
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=322)
print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))
writer.close()
输出:
0_convlayer shape:(64, 3, 11, 11)
1_convlayer shape:(192, 64, 5, 5)
查看可视化效果:

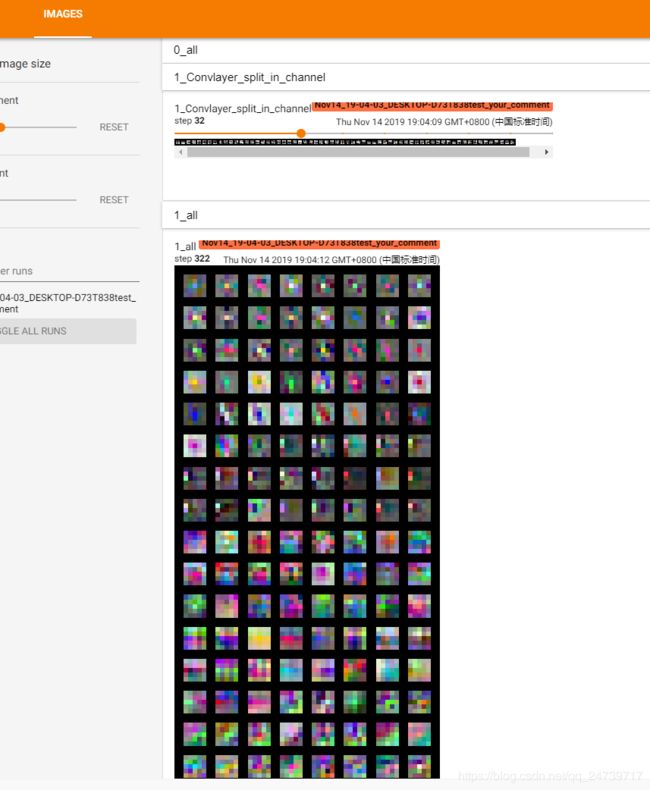
2.特征图可视化
测试代码:
# ----------------------------------- feature map visualization -----------------------------------
# flag = 0
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "./lena.png" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
alexnet = models.alexnet(pretrained=True)
# forward
convlayer1 = alexnet.features[0]
fmap_1 = convlayer1(img_tensor)
# 预处理
fmap_1.transpose_(0, 1) # bchw=(1, 64, 55, 55) --> (64, 1, 55, 55)
fmap_1_grid = vutils.make_grid(fmap_1, normalize=True, scale_each=True, nrow=8)
writer.add_image('feature map in conv1', fmap_1_grid, global_step=322)
writer.close()
可视化结果

三.add_graph and torchsummary
1.add_graph()
功能:可视化模型计算图

- model :模型,必须是nn.Module
- input_to_model:输出给模型的数据
- verbose :是否打印计算图结构信息
这个pytorch = 1.2 版本有问题,需要更新到 pytorch = 1.3 版本
测试代码:
# ----------------------------------- 5 add_graph -----------------------------------
# flag = 0
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 模型
fake_img = torch.randn(1, 3, 32, 32)
lenet = LeNet(classes=2)
writer.add_graph(lenet, fake_img)
writer.close()
from torchsummary import summary
print(summary(lenet, (3, 32, 32), device="cpu"))
输出:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 456
Conv2d-2 [-1, 16, 10, 10] 2,416
Linear-3 [-1, 120] 48,120
Linear-4 [-1, 84] 10,164
Linear-5 [-1, 2] 170
================================================================
Total params: 61,326
Trainable params: 61,326
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.05
Params size (MB): 0.23
Estimated Total Size (MB): 0.30
----------------------------------------------------------------
None
可视化结果


2.torchsummary
功能:查看模型信息,便于调试
![]()
- model : pytorch模型
- input_size :模型输入size
- batch_size : batch size
- device :“cuda”or“cpu”
测试代码如上。