RocketMQ(8)消息队列Offset和CommitLog
RocketMQ消息偏移量Offset
目录
RocketMQ消息偏移量Offset
RocketMQ消息存储CommitLog
高性能分析之ZeroCopy零拷贝技术
什么是offset
message queue是无限长的数组,一条消息进来下标就会长1,下标就是offset,消息在某个MessageQueue里的位置,通过offset的值可以定位到这条消息,或者指示Consumer从这条消息开始向后处理
message queue中的maxOffset表示消息的最大offset, maxOffset并不是最新的那条消息的offset,而是最新消息的offset+1,minOffset则是现存在的最小offset。
fileReserveTime=48 默认消息存储48小时后,消费会被物理地从磁盘删除,message queue的min offset也就对应增长。所以比minOffset还要小的那些消息已经不在broker上了,就无法被消费
类型(父类是OffsetStore):

- 本地文件类型 ( )
DefaultMQPushConsumer的BROADCASTING模式,各个Consumer没有互相干扰,使用LoclaFileOffsetStore把Offset存储在本地
- Broker代存储类型
DefaultMQPushConsumer的CLUSTERING模式,由Broker端存储和控制Offset的值,使用RemoteBrokerOffsetStore
阅读源码的正确姿势:
先有思路,明白大体流程
再看接口
再看实现类
- 有什么用
主要是记录消息的偏移量,有多个消费者进行消费
集群模式下采用RemoteBrokerOffsetStore, broker控制offset的值
广播模式下采用LocalFileOffsetStore, 消费端存储 - 建议采用pushConsumer,RocketMQ自动维护OffsetStore,如果用另外一种pullConsumer需要自己进行维护OffsetStore
RocketMQ消息存储CommitLog
- 消息存储是由ConsumeQueue和CommitLog配合完成
ConsumeQueue: 是逻辑队列(存CommitLog的偏移量)CommitLog是真正存储消息文件的,存储的是指向物理存储的地址
Topic下的每个message queue都有对应的ConsumeQueue文件,内容也会被持久化到磁盘
默认地址:store/consumequeue/{topicName}/{queueid}/fileName
(store默认在用户的根路径中)
- 什么是CommitLog:
消息文件的存储地址
- 生成规则:
每个文件的默认1G =1024 * 1024 * 1024,commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;
比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1 073 741 824Byte;
当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824, 消息存储的时候会顺序写入文件,当文件满了则写入下一个文件
判断消息存储在哪个CommitLog上
例如 1073742827 为物理偏移量,则其对应的相对偏移量为 1003 = 1073742827 - 1073741824,并且该偏移量位于第二个 CommitLog。
- Broker里面一个Topic
里面有多个MesssageQueue
每个MessageQueue对应一个ConsumeQueue
ConsumeQueue里面记录的是消息在CommitLog里面的物理存储地址
高性能分析之ZeroCopy零拷贝技术
- 高效原因
CommitLog顺序写, 存储了MessagBody、message key、tag等信息(磁盘的顺序写非常快可达几百M)
ConsumeQueue(用索引,相当于书中按目录查询,否则全书扫描)随机读 + 操作系统的PageCache + 零拷贝技术ZeroCopy
- 非零拷贝技术
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
例子:将一个File读取并发送出去(Linux有两个上下文,内核态,用户态)
File文件的经历了4次copy
调用read,将文件拷贝到了kernel内核态
CPU控制 kernel态的数据copy到用户态
调用write时,user态下的内容会copy到内核态的socket的buffer中
最后将内核态socket buffer的数据copy到网卡设备中传送
缺点:增加了上下文切换、浪费了2次无效拷贝(即步骤2和3)

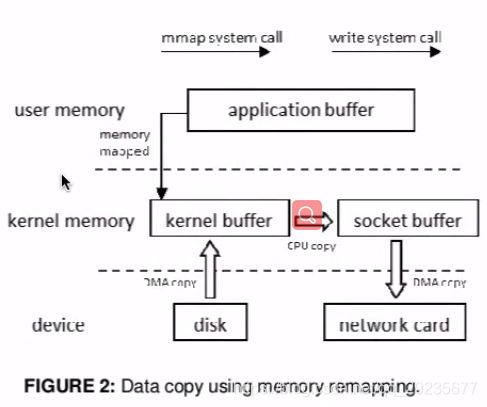
- ZeroCopy:
请求kernel直接把disk的data传输给socket,而不是通过应用程序传输。Zero copy大大提高了应用程序的性能,减少不必要的内核缓冲区跟用户缓冲区间的拷贝,从而减少CPU的开销和减少了kernel和user模式的上下文切换,达到性能的提升
- 对应零拷贝技术有mmap及sendfile
mmap:小文件传输快
RocketMQ 选择这种方式,mmap+write 方式,小块数据传输,效果会比 sendfile 更好
sendfile:大文件传输比mmap快
Java中的TransferTo()实现了Zero-Copy
应用:Kafka、Netty、RocketMQ等都采用了零拷贝技术