MIT6.824 分布式系统之lab1 mapReduce
本篇博文记录了我的lab1实现原理,思路以及答案。希望对大家有所帮助,也希望大家踊跃的指出错误和欢迎提出更好的思路算法。共勉。
前言
首先在做本实验之前,必须先阅读mapReduce论文
《MapReduce: Simplified Data Processing on Large Cluster 》
能看懂英文原版的当然看英文最好,看不懂的网上也有很多翻译版,大家自行查阅。可能翻译版都是靠翻译软件翻译的,很多地方有逻辑语义错误,不过问题不大,只是读起来别扭,看懂应该没问题的。
实验解析
论文我就不说了,不是本文的重点,本文重在讲解实验。
实验0 实验准备
做实验之前要先把官方提供的实验代码下载下来
具体下载方法实验指导书上面也写的很详细。大家按着提示下载就行了
$ git clone git://g.csail.mit.edu/6.824-golabs-2018 6.824
$ cd 6.824
实验一 映射/减少输入和输出
本实验完成common_map.go中的doMap()函数和 common_reduce.go中的doReduce()这两个函数。
doMap管理一个映射任务:它应该读取一个输入文件(inFile),为该文件的内容调用用户定义的映射函数(mapF),并将mapF的输出划分为nReduce中间文件。也就是说doMap的任务是把输入文件的内容分成一个一个的键值对然后进行输出
每个reduce任务有一个中间文件。文件名包含map任务编号和reduce任务编号。需要用到官方提供的
reduceName(jobName, mapTask, r)生成的文件名作为reduce任务r的中间文件,这个r如何取值呢?官方提供了一个ihash函数,将每个key传入ihash函数,返回一个int,最后再用此int mod nReduce就可以了。
还有一点就是由于reduce的输出必须是json格式,为了方便起见,这里的输出文件最好也输出为json格式(非必须)
func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,
) {
// 打开输入文件
file,err:=os.OpenFile(inFile,os.O_RDONLY,0644)
if err!=nil {
fmt.Println("map 66文件打开失败:",err)
}
//记得关闭文件
defer file.Close()
//文件内容读取操作
reader:=bufio.NewReader(file)
FileContent,err1:=ioutil.ReadAll(reader)
if err1!=nil {
fmt.Println("map 74 文件打开失败:",err1)
}
ReduceKeyValue:=mapF(inFile,string(FileContent))
//生成reduce中间文件
for i:=0;i<nReduce;i++{
//中间文件命名规则 由项目提供的函数命名
RName:=reduceName(jobName,mapTask,i)
mapOutFile,err2:=os.OpenFile(RName,os.O_CREATE|os.O_WRONLY|os.O_APPEND,0644)
if err2!=nil{
fmt.Println(RName,"map 82 文件打开失败",err2)
}
//写入文件 使用json格式
enc:=json.NewEncoder(mapOutFile)
for _,value:=range ReduceKeyValue{
if ihash(value.Key)%nReduce==i {
err3:=enc.Encode(&value)
if err3!=nil {
fmt.Println("map 92 文件写入失败", err3)
}
}
}
mapOutFile.Close()
}
}
doReduce管理一个reduce任务:它应该读取任务的中间文件,根据键对中间键/值对进行排序,为每个键调用用户定义的reduce函数(reduceF),并将reduceF的输出写到磁盘上。也就是说reduce的任务是把map生成的中间键值对整合起来,然后以json格式输出到文件
type keyValues []KeyValue
func (s keyValues) Len() int {return len(s)}
func (s keyValues) Swap(i,j int){s[i],s[j]=s[j],s[i]}
func (s keyValues) Less(i,j int) bool{return s[i].Key<s[j].Key}
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTask int, // which reduce task this is
outFile string, // write the output here
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
//读取输入文件内容
var reduceDate []KeyValue
//打开-所有-中间文件
var ReduceInputFileName string
for i:=0;i<nMap ;i++ {
//获取输入文件名
ReduceInputFileName=reduceName(jobName,i,reduceTask)
file,err:=os.Open(ReduceInputFileName)
if err!=nil {
fmt.Println(ReduceInputFileName,"reduce 71 文件打开失败:",err)
}
//json 解码 必须循环获取 不能按照网上的传入结构体切片
decoder :=json.NewDecoder(file)
for {
var v KeyValue
err2:=decoder.Decode(&v)
if err2 != nil {
break
}
reduceDate = append(reduceDate, v)
}
//最后关闭文件 不要用defer
file.Close()
}
//对输入内容排序 使用函数库里面的sort进行排序
var SortedReduceDate keyValues=reduceDate[:]
sort.Sort(SortedReduceDate)
//准备输出文件
ReduceOutFile,err1:=os.OpenFile(outFile,os.O_WRONLY|os.O_APPEND|os.O_CREATE,0644)
if err1!=nil {
fmt.Println(outFile,"reduce 70 文件打开失败:",err1)
}
defer ReduceOutFile.Close()
//json 对输出内容文件编码输出
encoder:=json.NewEncoder(ReduceOutFile)
var dateForPerKey []string
key:=SortedReduceDate[0].Key
for _,value:=range SortedReduceDate {
if key==value.Key{
dateForPerKey=append(dateForPerKey,value.Value)
} else{
outString:=reduceF(key,dateForPerKey)
encoder.Encode(KeyValue{key,outString})
key=value.Key
//清空上一个dateForPerKey
dateForPerKey=dateForPerKey[:0]
dateForPerKey=append(dateForPerKey,value.Value)
}
}
//最后一个key
if(len(dateForPerKey)!=0){
outString:=reduceF(key,dateForPerKey)
encoder.Encode(KeyValue{key,outString})
}
}
这里用到了官方库的sort排序方法。还有reduce输出的时候对相同key的value整合有点麻烦,这里是考虑到前面本来就是排序了的,所以直接比较key就好了。还有一种更巧妙的方法是创建一个map[string] []string
这样只需要往相同的key里面加值就可以了
实验二 单工字数统计

实验1里面用到了两个函数 一个是mapF() 另一个是reduceF(),这两个函数是doMap()和doReduce()的精髓。其实这两个函数里面都是空的,本实验就是要你自己完成这两个函数,实现统计一篇文章或多篇文章里面单词的出现次数。
mapF的任务就是将单词分成 {key:"…" value:" …"}(value通常是1)这样的键值对。然后reduceF把相同的key的value相加起来。这样不就完成了对单词的统计了吗。
func mapF(filename string, contents string) []mapreduce.KeyValue {
// Your code here (Part II).
f:=func (c rune) bool{
//只要不是字母 就默认为是分割符
return !unicode.IsLetter(c)
}
var temp=strings.FieldsFunc(contents,f)
var result []mapreduce.KeyValue
for _,value:=range temp{
result= append(result, mapreduce.KeyValue{Key:value,Value:"1"})
}
return result
}
这里用到了strings.FieldsFunc函数,这个函数是用来分割字符串的,也就是把文章内容分割成一个一个的单词,这里我们默认只要不是字母就是分隔符,比如说 空格 回车 逗号句号等等。
func reduceF(key string, values []string) string {
// Your code here (Part II).
if len(values)==0{
fmt.Println("values =0")
}
var count int
var result string
for _,v:=range values{
Int,err:=strconv.Atoi(v)
if err!=nil{
fmt.Println("Int 40 v 不是一个数字",v)
}
count+=Int
}
result=strconv.Itoa(count)
return result
}
这里用到了两个函数Atoi和Itoa,Int Array相互转换的函数。也很简单,照着用就行了。
实验三 分发MapReduce任务
这个实验我认为是这几个实验中最难的,代码不难,理解难。前面两个实验都是线性( Sequence)的,也就是先做map再做reduce,而且map也是一个文件一个文件挨着读,再一个文件一个文件挨着写的,这样的好处是方便调试。但是不符合分布式系统的理念。所以这个实验就是通过多核计算机的并发机制来模拟多个计算机同时处理一个计算任务的场景。这里用到了go语言的并发,GO语言的通道机制,以及死锁避免。woker都是系统提供好的,所以你的任务就是把任务并发的分配给所有woker,您的工作是 在mapreduce / schedule.go中实现schedule()。
func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) {
var ntasks int
var n_other int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mapFiles)
n_other = nReduce
case reducePhase:
ntasks = nReduce
n_other = len(mapFiles)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other)
// All ntasks tasks have to be scheduled on workers. Once all tasks
// have completed successfully, schedule() should return.
//
// Your code here (Part III, Part IV).
//
var threadMaster sync.WaitGroup
for i:=0;i<ntasks;i++{
//并发分配任务
threadMaster.Add(1)
go func(inputFile string,TaskNumber int) {
//call函数可能失败 循环发送直到发送成功
for {
rpcAdr:=<-registerChan
ok:=call(rpcAdr,"Worker.DoTask",DoTaskArgs{
JobName: jobName,
File: inputFile,
Phase: phase,
TaskNumber: TaskNumber,
NumOtherPhase: n_other,
},nil)
if ok {
//任务完成后 将此worker重新加入registerChan 表示此woker可用
//特别注意 一定要先done了只有再往通道里面发送数据,因为此通道是无缓冲通道,当最后一个woker被填入通道
//而通道对面没有接受,此时此线程会永久阻塞在这里从而无法运行到done,主程序的wait也会永久阻塞,造成死锁
go func() {
registerChan<-rpcAdr
}()
break
}
}
threadMaster.Done()
}(mapFiles[i],i)
}
fmt.Printf("Schedule: %v done\n", phase)
threadMaster.Wait()
}
实验四 处理工人失败
您将使主服务器处理失败的工作程序。MapReduce使此操作相对容易,因为工作人员没有持久状态。如果一个工作进程在处理来自主服务器的RPC时失败,则由于超时,主服务器的call()最终将返回false。在这种情况下,主服务器应将分配给失败的工作人员的任务重新分配给另一工作人员。
这里其实实验三的代码里面已经考虑到这一点了。
![]()

这两个地方就考虑到了woker宕机。在这个for死循环中,直到call返回true,也就是服务器回应了才把此woker重新加入通道。否则就从通道中重新取出一位woker处理当前任务。
这里需要避免死锁
特别注意 一定要先done了只有再往通道里面发送数据,因为此通道是无缓冲通道,当最后一个woker被填入通道而通道对面没有接受,此时此线程会永久阻塞在这里从而无法运行到done,主程序的wait也会永久阻塞,造成死锁
实验五 倒排索引生成(可选,不计入成绩)
实验二让你完成了mapF和reduceF两个函数,目的实现统计文件单词数目的功能,这个其实也差不多,也就是统计单词在那个文件里面出现过的功能,也就是所谓的倒排索引,很简单,只要把mapF里面的value换成文件名不就行了吗。不过题目要求要排序,所以要在reduceF里面进行排序,这次排序就不用了像上次一样再重新创建个接口了。因为库里面有直接对字符串数组的排序函数
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// Your code here (Part V).
f:=func (c rune) bool{
//只要不是字母 就默认为是分割符
return !unicode.IsLetter(c)
}
var temp=strings.FieldsFunc(value,f)
var result []mapreduce.KeyValue
mapSS :=make(map[string]string)
//注意这里要去掉重复的key
for _,word:=range temp{
mapSS[word]=document
}
for Word,Document:=range mapSS{
result=append(result,mapreduce.KeyValue{Key:Word,Value:Document})
}
return result
}
func reduceF(key string, values []string) string {
// Your code here (Part V).
sort.Strings(values)
var result string
for i,tmp:=range values{
if i!=0{
result +=","
}else {
result=strconv.Itoa(len(values))+" "
}
result+=tmp
}
return result
}
最后5个实验检测一下
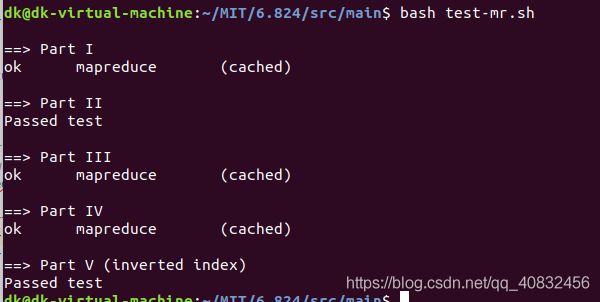
ok 全部正确。搞定完事儿