爬虫框架scrapy
scrapy简介
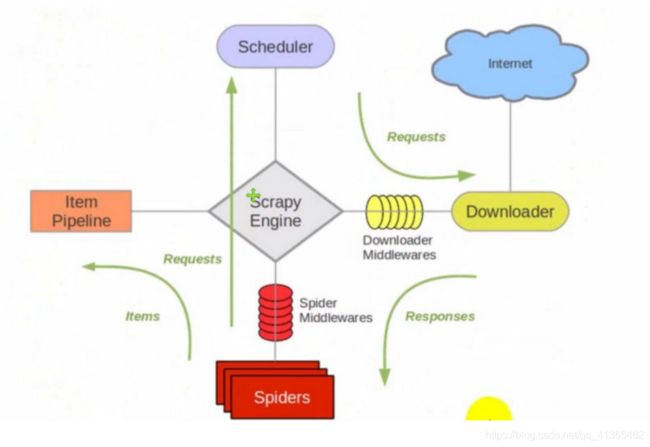
通用爬虫框架流程

Scrapy 框架运行流程
案例:基于 Scrapy 框架影视信息采集与分析
需求:以“豆瓣电影”为爬取目 标,爬取网站中的影视信息。主要包括网站排名 “ Top250 ”和喜剧、动作类电影
的电影名称、电影评分、电影导演, 电影上映时间以及电影评语。
创建工程:scrapy startproject DouBan
建爬虫程序:
cd DouBan/
scrapy
genspider douban 'douban.com'
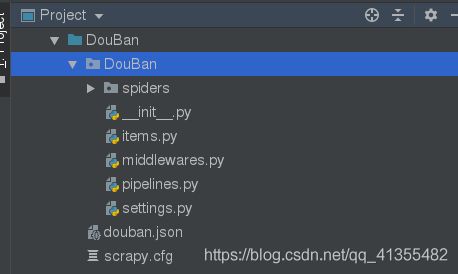
自动创建目录及文件
编写爬虫文件(douban.py)
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from DouBan.items import DoubanItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com']
# start_urls = ['http://douban.com/']
start_urls = ['https://movie.douban.com/top250']
url='https://movie.douban.com/top250'
def parse(self, response):
item=DoubanItem()
movies=response.xpath('//ol[@class="grid_view"]/li')
print(movies)
for movie in movies:
print(movie)
# 电影名称
title=movie.xpath('.//span[@class="title"]/text()').extract()[0]
#电影评分
score=movie.xpath('.//span[@class="rating_num"]/text()').extract()[0]
#电影评语
quote=movie.xpath('.//span[@class="inq"]/text()').extract()
#演员信息
info=movie.xpath('.//div[@class="bd"]/p/text()').extract()[0]
#评论数量
comment_num=movie.xpath('.//div[@class="star"]/span/text()').extract()[1]
item['title']=title
item['score']=score
item['quote']=quote[0] if quote else ''
item['director']=info.split('主演')[0].strip()
item['comment_num']=comment_num.split("人评价")[0]
item['image_url']=movie.xpath('.//div[@class="pic"]/a/img/@src').extract()[0]
item['detail_url']=movie.xpath('.//div[@class="hd"]/a/@href').extract()[0]
yield item
nextLink=response.xpath('//span[@class="next"]/a/@href').extract()
if nextLink:
nextLink=nextLink[0]
# print('*'*50)
# print(nextLink)
yield Request(self.url+nextLink,callback=self.parse)
编辑item文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()#电影名称
score=scrapy.Field()#电影评分
quote=scrapy.Field()#电影短评
director=scrapy.Field()#导演
comment_num=scrapy.Field()# 评论数
image_url=scrapy.Field()
detail_url=scrapy.Field()
# image_path=scrapy.Field()
编辑pipelines文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
import pymysql
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class DoubanPipeline(object):
def process_item(self, item, spider):
return item
class AddScoreNum(object):
def process_item(self, item, spider):
if item['score']:
score = float(item['score'])
item['score'] = str(score + 1)
return item
else:
raise Exception("没有爬取到score")
class JsonWritePiplineob(object):
def open_spider(self, spider):
self.file = open('douban.json', 'w')
def process_item(self, item, spider):
line = json.dumps(dict(item), indent=4, ensure_ascii=False)
self.file.write(line)
return item
def close_spider(self, spider):
self.file.close()
# class MysqlPipeline(object):
#
# def open_spider(self, spider):
# print('*'*10)
# self.conect = pymysql.connect(
# host='127.0.0.1',
# port=3306,
# db='scrapyProject',
# user='root',
# passwd='westos',
# charset='utf8',
# use_unicode=True,
# autocommit=True
# )
# print("connect: ", self.conect)
# self.cursor = self.conect.cursor()
# self.cursor.execute("create table if not exists DouBanTop("
# "title varchar(15),"
# "score float,"
# "quote varchar(25),"
# "director varchar(15),"
# "comment_num int); ")
#
# def process_item(self, item, spider):
# insert_sqli = "insert into DouBanTop(title,score,quote,director,comment_num) values ('%s','%s','%s','%s','%s')" % (
# item['title'], item['score'], item['quote'], item['director'], item['comment_num'])
#
# print(insert_sqli)
#
# try:
# self.cursor.execute(insert_sqli)
# self.conect.commit()
# except Exception as e:
# self.conect.rollback()
# return item
#
# def close_spider(self, spider):
# self.conect.commit()
# self.cursor.close()
# self.conect.close()
class MyImagesPipline(ImagesPipeline):
def get_media_requests(self,item,info):
yield scrapy.Request(item['image_url'])
def item_completed(self, results, item, info):
image_paths=[x['path'] for isok,x in results if isok]
if not image_paths:
raise DropItem("Item contaiins images")
item['image_path']=image_paths[0]
return item
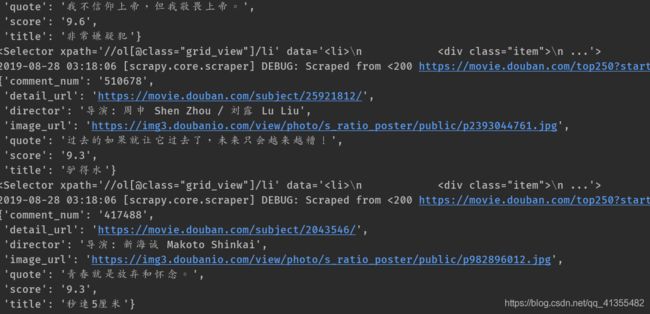
执行命令运行单个爬虫:scrapy crawl douban
效果如下: