【题目泛做】学军信友队欢乐赛 E (线段树)(凸包)(单调栈)

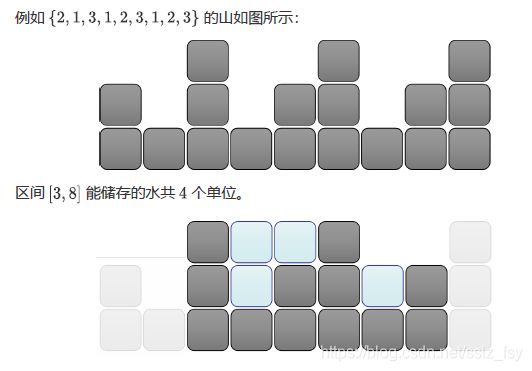
-
神题
-
考虑维护上界和下界,下界是个区间求和
上界是个阶梯状的(前缀 m a x max max 和 后缀 m a x max max)
假设询问全部是 [ 1 , n ] [1,n] [1,n],那么我们预处理一个点在 [ l i , r i ] [l_i,r_i] [li,ri] 的时间内作为前缀最大值
然后按时间排序,插入当前作为最大值的点,线段树维护这个单调栈的贡献
现在需要解决区间是 [ l , r ] [l,r] [l,r] 的情况,这种情况我们在线段树上拆分成 l o g log log 个区间,按顺序跟前面的拼接,于是发现要知道在 [ l , r ] [l,r] [l,r] 中作为前缀最大值的点集
就是要预处理仅考虑 [ l , r ] [l,r] [l,r] 的区间,每个点作为前缀最大值的出现时间区间
这个是一个动态半平面交问题,我们考虑对线段树每个点维护一个凸包,然后从底向上跳,如果是右儿子就在左儿子里的凸包查询,卡出出现时间的范围 -
总结(一句话题解):拆成 l o g log log 个查询区间,依次考虑跟前面的拼接(这个需要线段树维护单调栈在线段树上二分),内层线段树维护单调栈的贡献,预先用线段树和凸包预处理出每个点在每个区间作为前缀最大值的时间,每个结点按时间排序动态维护前缀最大值的集合吗,复杂度每一个过程都是 O ( n l o g 2 n ) O(nlog^2n) O(nlog2n)
#include