SSD源码解析4-损失函数(理论+源码)
SSD源码解析1-整体结构和框架
SSD源码解析2-input_pipeline()
SSD源码解析3-ssd_model_fn()
SSD源码解析4-损失函数(理论+源码)
参考文章:
博客园:深度学习笔记(七)SSD 论文阅读笔记简化
知乎:SSD
知乎:目标检测|SSD原理与实现
知乎:SSD-TensorFlow 源码解析
TensorFlow之estimator详解
解析代码:
解析源码地址
SSD源码简单版
看了一下两个版本的代码,如上面链接所示,
简单版,代码和之前解析的源码类型是一致的,更容易理解些,但是只有预测部分而没有训练部分。虽然能很容易理解,但里面没有标签处理,损失计算等部分。即使看懂了,也有种啥都没学到的感觉。
复杂版,当时看到这个源代码是有点懵的,为啥呢?因为看不懂啊,之前没见过用这种方式写的代码,套路不太一样。反反复复犹犹豫豫了好几次,想着要不要花点精力看复杂版的,也尝试在github上搜了一下看看有没有更合适的版本,结果是并没有,所以就硬着头皮解析这个比较复杂的代码了。前期是先跳过了看不懂的部分,直接去看网络构建部分,anchor生成部分,计算损失部分,数据预处理部分,但是整体运行逻辑还是有点懵。后来看了一点有关TensorFlow的Estimator讲解,稍微有点眉目,但是还不是很了解,有点不知所以然。主要是Estimator的方式不太习惯,如果只把他当作一种框架,你按它固定的格式传入相应的参数就行,还可以接受些。具体的网络搭建,anchor创建,损失计算等和之前还是一样的。
SSD损失函数
相比较YOLOv3,SSD的损失函数相对直观些,这次就不贴手写的了,因为要贴损失计算实现的代码,手写太费事了。
SSD损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和(实际代码中还会加上l2_loss以防止过拟合):
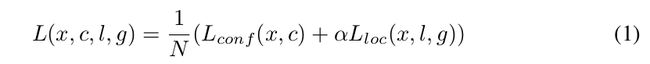
其中 是先验框的正样本数量。这里
是先验框的正样本数量。这里 ![]() 为一个指示参数,当
为一个指示参数,当![]() 时表示第i 个先验框与第j 个ground truth匹配,并且ground truth的类别为 p 。 c 为类别置信度预测值。
时表示第i 个先验框与第j 个ground truth匹配,并且ground truth的类别为 p 。 c 为类别置信度预测值。  为先验框的所对应边界框的位置预测值,而 g 是ground truth的位置参数。
为先验框的所对应边界框的位置预测值,而 g 是ground truth的位置参数。
下面盗一张图再来说明一下:
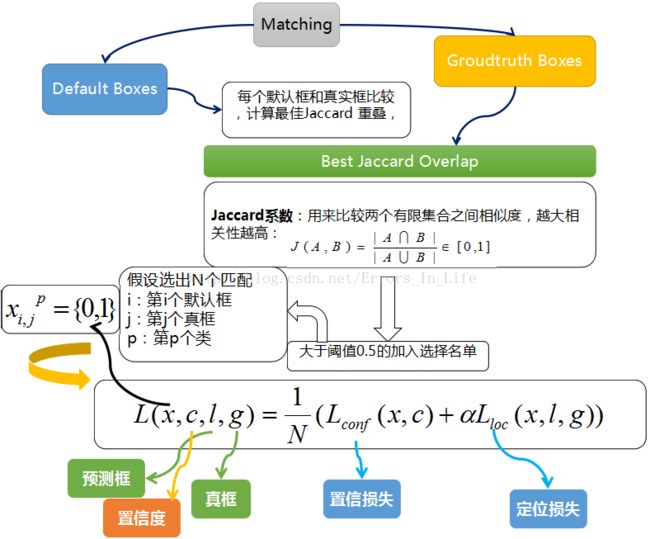
1,对于位置误差
其采用Smooth L1 loss,定义如下:

由于![]() 的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的g 进行编码得到
的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的g 进行编码得到 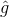 (偏移量),因为预测值 也是编码值,若设置variance_encoded_in_target=True,编码时要加上variance=[0.1, 0.1, 0.2, 0.2]:
(偏移量),因为预测值 也是编码值,若设置variance_encoded_in_target=True,编码时要加上variance=[0.1, 0.1, 0.2, 0.2]:

上面公式在实际代码中的操作如下(encode_all_anchors()函数中):
gt_cy = (gt_cy - anchor_cy) / anchor_h / self._prior_scaling[0] # [0.1, 0.1, 0.2, 0.2]
gt_cx = (gt_cx - anchor_cx) / anchor_w / self._prior_scaling[1]
gt_h = tf.log(gt_h / anchor_h) / self._prior_scaling[2]
gt_w = tf.log(gt_w / anchor_w) / self._prior_scaling[3]smooth_l1的公式如下,实际计算中x=g-l,g为ground_truth,l为预测值。

其中smooth_l1的代码实现如下:
'''
smooth_l1损失
'''
def modified_smooth_l1(bbox_pred, bbox_targets, bbox_inside_weights=1., bbox_outside_weights=1., sigma=1.):
"""
ResultLoss = outside_weights * SmoothL1(inside_weights * (bbox_pred - bbox_targets))
SmoothL1(x) = 0.5 * (sigma * x)^2, if |x| < 1 / sigma^2
|x| - 0.5 / sigma^2, otherwise
"""
with tf.name_scope('smooth_l1', values=[bbox_pred, bbox_targets]):
sigma2 = sigma * sigma
inside_mul = tf.multiply(bbox_inside_weights, tf.subtract(bbox_pred, bbox_targets))
smooth_l1_sign = tf.cast(tf.less(tf.abs(inside_mul), 1.0 / sigma2), tf.float32)
smooth_l1_option1 = tf.multiply(tf.multiply(inside_mul, inside_mul), 0.5 * sigma2) # 0.5x^2
smooth_l1_option2 = tf.subtract(tf.abs(inside_mul), 0.5 / sigma2) # |x|-0.5
smooth_l1_result = tf.add(tf.multiply(smooth_l1_option1, smooth_l1_sign),
tf.multiply(smooth_l1_option2, tf.abs(tf.subtract(smooth_l1_sign, 1.0))))
outside_mul = tf.multiply(bbox_outside_weights, smooth_l1_result)
return outside_mul
实际程序中计算smooth_l1损失的代码如下(其中location_pred是预测边框的编码值,flaten_loc_targets是标记边框的编码值):
#*******预测框回归smooth_l1损失
loc_loss = modified_smooth_l1(location_pred, flaten_loc_targets, sigma=1.) # 这时是框坐标的偏移量
loc_loss = tf.reduce_mean(tf.reduce_sum(loc_loss, axis=-1), name='location_loss')
tf.summary.scalar('location_loss', loc_loss)
tf.losses.add_loss(loc_loss)
2,对于置信度误差
其采用softmax loss:

权重系数  通过交叉验证设置为1。
通过交叉验证设置为1。
实际程序中对应的代码如下(其中flaten_cls_targets是类别标记值,cls_pred是预测类别值):
# 分类的交叉熵损失,并乘以权重系数3+1
cross_entropy = tf.losses.sparse_softmax_cross_entropy(labels=flaten_cls_targets, logits=cls_pred) * (params['negative_ratio'] + 1.)
# 创建一个名为cross_entropy_loss的张量用于记录。
tf.identity(cross_entropy, name='cross_entropy_loss')
tf.summary.scalar('cross_entropy_loss', cross_entropy)3,l2_loss
在实际代码中,为了防止过拟合,加入了l2_loss(l2_loss一般用于优化目标函数中的正则项,防止参数太多复杂容易过拟合)。
不过正常的l2范数是求变量平方和再开根号,但是实际代码中并不是完全这样做的,而是求变量平方和的一半。
# l2_loss一般用于优化目标函数中的正则项,防止参数太多复杂容易过拟合
# l2 计算模型中所有可训练变量(除了带_bn和conv4_3_scale的变量)的l2范数(变形版,求平方和的一半),l2范数是求平方和开根号
l2_loss_vars = []
for trainable_var in tf.trainable_variables():
if '_bn' not in trainable_var.name:
if 'conv4_3_scale' not in trainable_var.name:
l2_loss_vars.append(tf.nn.l2_loss(trainable_var)) #tf.nn.l2_loss 利用L2范数来计算张量的误差值,output = sum(t^2)/2
else:
l2_loss_vars.append(tf.nn.l2_loss(trainable_var) * 0.1)4,total_loss
total_loss是将上面的loc_loss,cross_loss,l2_loss_vars相加得到整个模型的损失。
- total_loss=cross_loss+loc_loss+weight_decay*l2_loss_vars
# Add weight decay to the loss. We exclude the batch norm variables because doing so leads to a small improvement in accuracy.
# 增加重量衰减。 我们将批处理规范变量排除在外,因为这样做会导致准确性略有提高。
total_loss = tf.add(cross_entropy + loc_loss, tf.multiply(params['weight_decay'], tf.add_n(l2_loss_vars), name='l2_loss'), name='total_loss')上面的weight_decay在一开始得参数定义中定义。
tf.app.flags.DEFINE_float(
'weight_decay', 5e-4, 'The weight decay on the model weights.') 模型l2_loss上的权重衰减系数SSD的损失确实相对好理解些,好了,到此SSD的源码算是粗略地解析完了,如果发现其中的错误,欢迎批评指正!我是一个菜鸟,需要不断学习提高!加油!
