【蓝桥杯】历届试题 邮局(深度优先搜索dfs、组合方案)
历届试题 邮局
问题描述
C村住着n户村民,由于交通闭塞,C村的村民只能通过信件与外界交流。为了方便村民们发信,C村打算在C村建设k个邮局,这样每户村民可以去离自己家最近的邮局发信。
现在给出了m个备选的邮局,请从中选出k个来,使得村民到自己家最近的邮局的距离和最小。其中两点之间的距离定义为两点之间的直线距离。
输入格式
输入的第一行包含三个整数n, m, k,分别表示村民的户数、备选的邮局数和要建的邮局数。
接下来n行,每行两个整数x, y,依次表示每户村民家的坐标。
接下来m行,每行包含两个整数x, y,依次表示每个备选邮局的坐标。
在输入中,村民和村民、村民和邮局、邮局和邮局的坐标可能相同,但你应把它们看成不同的村民或邮局。
输出格式
输出一行,包含k个整数,从小到大依次表示你选择的备选邮局编号。(备选邮局按输入顺序由1到m编号)
样例输入
5 4 2
0 0
2 0
3 1
3 3
1 1
0 1
1 0
2 1
3 2
样例输出
2 4
数据规模和约定
对于30%的数据,1<=n<=10,1<=m<=10,1<=k<=5;
对于60%的数据,1<=m<=20;
对于100%的数据,1<=n<=50,1<=m<=25,1<=k<=10。
—— 分割线之初入江湖 ——
分析:
这道题的数据范围很有意思,n最大是取到50,m最大是取到25,而k最大是取到10,均不大于50。
于是我们的第一想法是能不能暴力求解(毕竟递归层次最多就在25,并没有超过30)?
怎么个暴力法?题目的意思不是让我们在m个候选位置中选k个么(这个正好是我们高中学的“组合”),那么我们就把这里面所有可能的组合方案都列出来,并对其中的每一种组合都进行计算,以求得在这种情况下k个邮局距居民的最近总距离。
比如对于m=5,n=3(即在5个侯选位置中选3个位置建立邮局),此时根据组合公式我们可以得到总方案数为:

这个数据量完全可以接受。当然,我们关心的问题是,具体的枚举方案是怎样的。
可以将其列出,如下所示(1表示选中,0表示未选中):

上表展示的是这10种情况的具体安排细节。
比如对于第1种方案,其意思是选择位置为1、2、3的三个候选位置建设邮局;
对于第6种方案,其意思是选择位置为1、4、5的三个候选位置建设邮局
……
对于某种安排,比如方案6,我们怎么求得其距离所有居民的最短距离呢?
很简单,我们只需要维护一个长度为当前录入的居民数的数组length[n]即可,该数组的实际意义是:对于某个给定的组合方案,length[i]指示了在这些备选位置中,距离居民i最近的邮局到居民i的距离。
就拿题目给的测试数据来举例说明:
5 4 2
0 0
2 0
3 1
3 3
1 1
0 1
1 0
2 1
3 2
为了更形象的解释,下面将其进行绘制,其中:居民位置用Hi来表示,候选邮局位置用Pi来表示
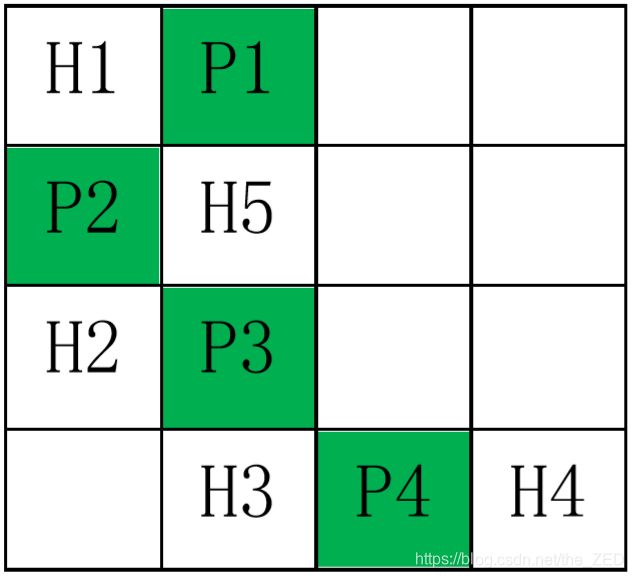
在程序录入所有居民和邮局的位置后,我们需要将所有的邮局和居民之间的距离计算出来以供后面的使用(免得到时候又重复计算,浪费时间)。这里我们用数组range[m][n]来存放这些信息,range[ i ][ j ] 表示第i个邮局到第j个居民的距离。下面给出测试数据这个例子的range数组内容,如下表所示:

假设现在我们的某个组合方案选择了候选邮局位置P2和P3,那么此时求length数组的整个过程如下:
初始化length数组中的每个元素为一个很大的值,即:length[5]={ INF,INF,INF,INF,INF };
然后判断当前组合方案选择的邮局能不能对length数组中的每个元素进行更新:
首先是P2,由于P2是第一个进来的,其距离各个居民的距离肯定比初始情况下的length数组小,于是更新length数组为range数组的第2行,即:length[5]={ 1, 1 , 1.414 , 3.606 , 1 }; 这意味着,当你选择P2所在位置作为邮局的建设位置时,此时距离5个居民的距离分别为:1、1、1.414、3.606、1。
接着是P3,此时我们把整个range[3][1-n]这一行都与length数组进行对比,一旦出现某项 range[ i ][ j ] 小于 length[ j ],我们就更新 length[ j ] = range[ i ][ j ],于是得到:length[5]={ 1 , 1 , 1 , 2.236 , 1 }; 这意味着,当你选择了P2和P3作为邮局的建设位置时,此时距离5个居民的最短距离分别为:1、1、1、2.236、1。当然,这也是length数组的最终具体情况。上述过程的代码描述为:
for(int j=1;j<=n;j++)
if(range[row][j]<length[j])
length[j]=range[row][j];
当执行完上面的流程后,我们就得到了在某个指定组合方案下的length数组。此时我们再将length数组中的所有值取出并累加进一个变量sum中,用以判断当前的length数组是否是最优解。显然,这里衡量是否为最优解的条件是sum越小越好(这意味着你选择的邮局位置会使每个居民距其最近邮局的距离和最短)。此时,我们就不可避免地需要再用一个全局变量minSum来存放在所有枚举情况中,sum的最小值。
比如在上面的举例中,首先是组合方案{ 2,3 }(即选择邮局P2和P3)的length数组,此时我们将length数组的结果进行累加,得到sum=1+1+1+2.236+1=6.236。由于sum < minSum,故更新minSum=sum=6.236(注:minSum最初需要被赋值为一个很大的值);
然后程序继续执行,当组合方案为{ 2,4 }(即选择邮局P2和P4)时,我们可以得到length数组为:{ 1,1,1,1,1 },此时容易得到sum=5,因为sum
当然了,这不是本题的最终目的,我们的终极目标应该是是输出具体的邮局序号。这也不难,我们可以再设一个外部变量(vector) v来存放当前的具体组合方案,每当minSum更新时,就意味着v也需要更新。比如在minSum=6.236时,v={ 2,3 };而当minSum更新为5时,v则需要更新为{ 2,4 }。
最终随着组合方案的枚举结束,向量v里存放的也就是我们想要的答案了。
—— 分割线之大梦初醒 ——
总结一下具体步骤:
① 枚举各个组合方案;
② 在每个组合方案下,找到其对应的length数组;
③ 对于每个length数组,求出其元素总和sum;
④ 判断sum是否小于minSum:是则更新向量v;否则继续执行①直到结束。
有同学肯定要问了,怎么枚举出具体的组合方案呢?
确实,求组合数固然简单,但是求具体的枚举方案却是一项技术活。
在上面的分析中,我们直接给出了某个具体的组合方案,比如我直接分析了选择序号{ 2,3 }和{ 2,4 }的情形。现在我们的问题是,怎么枚举出所有的具体组合方案。
实际上,枚举具体的组合方案主要有两种方法:回溯法、数组打表。
数组打表的方法,就是通过循环的方式得到前面我们绘出的那个表格(见下图)。如果采用这个办法,尽管我们可以用滚动数组的方式来节约内存,但是我们却不可避免地会进行大量的重复运算。
比如在方案一中,位置1、2、3被标记为选取,因此我们需要在这个情况下计算length数组;而在方案2中,位置1、2、4被标记为选取,我们又需要在这个情况下重新计算length数组。可实际上,方案1和方案2都含有位置1、2,但我们在求length数组的时候却忽略了这样一个事实,于是导致了重复计算length数组中的前两项(length[1]和length[2])。这给我们的程序带来了极大的时间浪费,显然是不可取的。
那回溯法呢?在利用回溯法求具体的组合方案时,我们其实就是在进行一个固定规律的搜索(dfs)。而在搜索过程中,当你深入下一层的时候,实际上你是保存着上一次的状态的。这里的状态包含了很多信息,比如之前你遍历了哪些情况,以及在那些情况下计算出的相关结果!这不正好么?可以克服由于情况转变而带来的重复计算。因此,本题在对具体组合方案的枚举上,采用了搜索算法。
下面我将“求具体组合方案以及组合总数”的代码贴上,贴这个代码的目的很简单——这是求解本题的算法基础。当然,如果对这个算法很熟悉的同学你就可以跳过这一部分啦。
利用回溯法求具体组合方案的完整代码如下:
#include下面我们简单测试下,比如我在程序中输入3 5,程序输出的结果如下:
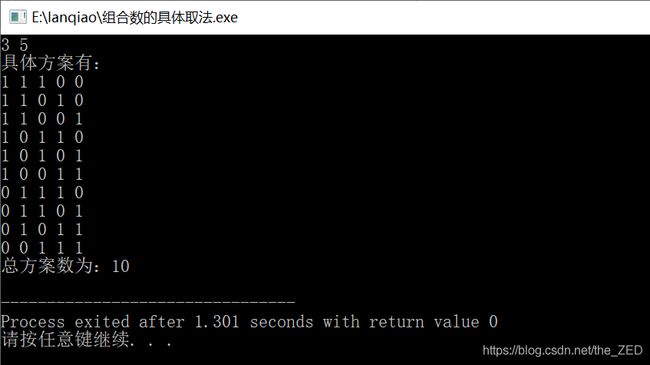
对比前面的表格:
你会发现结果是一致的。
好了,关于求解本题的步骤①到此就算是解决了。对于剩下的步骤②③④,我们可以将他们放到这个搜索过程中实现,具体的实现方式和上面描述的一样,在此不再赘述,下面给出暴力枚举法的完整代码(附详细解释):
#include—— 分割线之沧海横流 ——
上面的代码交上去只得了80分,剩下两组数据因为超时而过不了。
对于这个结果我只能说是意料之中,因为:

300多万种情况下,枚举能做到这个份已经算是仁慈义尽了,鼓掌!!!接下来我们需要想办法优化,对于搜索而言也就是剪枝。
题目有这么一句话“现在给出了m个备选的邮局,请从中选出k个来,使得村民到自己家最近的邮局的距离和最小”。那如果我们在dfs到某个深度的时候,发现剩下的邮局再加上之前选中的邮局都达不到k个,这种情况显然就不行。于是我们可以在dfs的一开始就进行一个判断,以检测是否会出现这样的情况,是就直接return;否则才能继续dfs。
这里肯定有一部分同学会这么想:虽然剩下的邮局再加上之前选中的邮局都达不到k个,但是如果在这样的情况下后面的邮局都无法为前面已选的邮局进行分担呢?题目又没有说最优解中的邮局一定能起到分担路程的作用,所以在这种情况下剩下的那些邮局修不修都无所谓啦!这样最终算出的minSum都是一样的呀!所以这道题出得不好!辣鸡!
对于这种同学,我愿意将他称之为“杠精”,并且送一句:“对不起,题目就是要选k个”
由于剪枝主要是对dfs进行的,程序的其他地方并未做任何改动,故下面仅给出剪枝后dfs部分的代码:
void dfs(int order,int num,float length[],vector<int> v)
{
if(m-(order-1)+num < k) return; //如果剩下的邮局再加上之前选中的邮局都达不到k个,则此情况不行
if(num==k) //表示当前已经选了k个邮局了
{
float sum=0;
for(int i=1;i<=n;i++) sum+=length[i];
if(sum<minSum){
minSum=sum;
ans=v;
}
return;
}
else if(order<=m) //order<=m表示后面还有邮局可选
{
bool flag=false; //标记当前邮局是否能起到分担缩小距离的作用
float temp[N];
memcpy(temp,length,sizeof(temp));
for(int i=1;i<=n;i++){
if(range[order][i]<length[i]){
length[i]=range[order][i];
flag=true;
}
}
if(flag){ //是则可以修建第order个邮局
v.push_back(order); //将其放进结果向量v中
dfs(order+1,num+1,length,v); //然后继续往下寻找
v.pop_back(); //回退时将前面推进的第order个邮局退出
}
dfs(order+1,num,temp,v); //无论flag取值如何都可以不选当前邮局
}
}
改进后的代码得了90分,最后一组数据还是过不了!我们还需要继续优化!
—— 分割线之否极泰来 ——
试想,如果你在某次dfs的时候,发现有一个邮局没起到分担缩小距离的作用,那么这就意味着这个邮局在最优解中一定是不存在的。所以我们可以将其标记,以便之后再遇到这个邮局的时候,直接跳过。如此便可以让那个邮局所在的那一层递归树变为单子树,从而以折半的方式对整个程序进行优化。
下面给出改进后,最终的满分代码(含详细注释):
#include最后我有个小问题想请教各位:请看以下代码,这是最初我进行标记优化时写的dfs的代码,我个人认为这个dfs与最终满分代码中的dfs效果一致。
但是结果却是:最后两组测试数据过不了,不是超时,而是错误!!!
这里我希望路过的大神帮忙给个解释,谢谢啦!~~~
void dfs(int order,int num,float length[],vector<int> v)
{
if(m-(order-1)+num < k) return;
if(num==k)
{
float sum=0;
for(int i=1;i<=n;i++) sum+=length[i];
if(sum<minSum){
minSum=sum;
ans=v;
}
return;
}
else if(order<=m)
{
bool flag=false;
float temp[N];
memcpy(temp,length,sizeof(temp));
if(unuseable[order]) goto label;
for(int i=1;i<=n;i++){
if(range[order][i]<length[i]){
length[i]=range[order][i];
flag=true;
}
}
if(flag){ //如果可以就修建当前邮局
v.push_back(order);
dfs(order+1,num+1,length,v);
v.pop_back();
}
else unuseable[order]=true;
label: dfs(order+1,num,temp,v); //不修建当前邮局
}
}
欢迎各路大仙评论区指点,谢谢咯!!!