对java集合类的知识归纳与总结
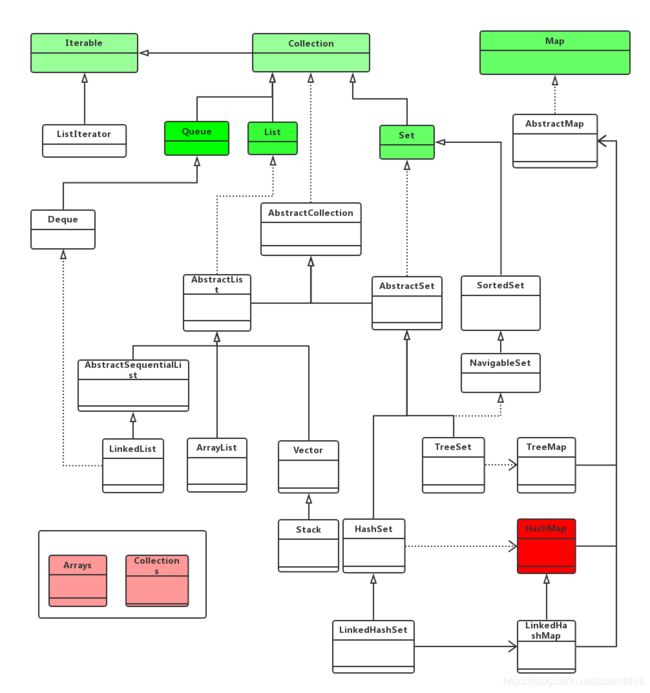 java集合框架
java集合框架
Java中的集合的两大类:
Collecton类:可以理解为主要存放的是单个对象,Collection继承了Iterate接口,Iterate用于集合内迭代器抽象接口,其子类均实现接口中方法。
Map类:可以理解为主要用来存储key-value类型的对象。
Collection类下有Queue,List,Set集合。其中Set集合的实现依赖于Map的实现。
Map类下有HashMap以及HashMap衍生的其他map类型。
HashMap与ConcurrentHashMap
1.HashMap
1.1 HashMap必须了解的一些概念
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
HashMap的底层结构是一个数组,数组中的每一项是一条链表。
HashMap与HashTable相比,HashMap是线程不安全的。而HashTable的虽然支持多线程,但是其多线程的性能较差,不支持高并发,这个在后面ConcurrentHashMap再细说。
HashMap中的key-value都是存储在Entry类中的。
HashMap通过hashCode()方法和equals方法保证键的唯一性。即先判断hashCode是否相同,相同用equals()方法比较,看是否正对相同,相同则已存在键,不相同则将放在链表后面。多线程的并发问题:多线程put时可能导致元素丢失;resize时可能出现环链导致死循环;fail-fast策略:在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException。
HashMap的用String类作为键。原因是:String类使用final修饰,而且重写了equals与hashCode方法。再加上String的不可变性,保证了其线程安全性。
1.2 hash碰撞的解决方法
解决哈希冲突主要有三种方法:开放定址法(再散列法),拉链法,再哈希法。HashMap是采用拉链法解决哈希冲突的。
其中开发地址法,就是一旦发生冲突,就往后寻找空的散列地址。缺点是容易产生堆积问题,造成性能过慢。
拉链法是使用数组链表的数据结构,将冲突的对象往链表后面放。不会产生堆积问题,切查找速度较快。java1.8之后对链表做了优化,默认超过8个节点后,链表会转为红黑树。
再哈希就是设置多个hash函数,一旦冲突就是用其他的hash函数再hash,直到没有冲突为止。
建立溢出表:将发生冲突的元素直接放入溢出表中。
1.3 HashMap与HashTable的区别
Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。
Hashtable中不允许出现null键与null值,当有值或键被设置为null时,运行时会报空指针异常。HashMap中null可以作为键,也可以作为值。作为键时只能有一个null键,作为值是可以有很多。而用get方法返回null时可以表示没有这个键,也可以表示键对应的值是null,所以不能使用get方法判断hashmap中是否存在某个键,而是要使用containsKey方法。
之所以这样设计,是因为Hashtable和concurrentHashMap一样,都是支持多线程的,而单线程的HashMap可以通过containsKey来判断是否有某个键,而多线程情况下,一个线程先get(key)再containKey(key),这两个方法的中间时刻,可能有其他线程来对集合做操作,使得线程不安全。
哈希值的使用不同,Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模。HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸。
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式不同。HashTable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,增加的方式是old*2,所以一定是2的指数。
1.4 HashMap的容量一定是2的n次方
为了在hash时保证一定程度上的性能,将元素均匀的放在数组链表中,HashMap使用的hash函数是取余运算,而在对2^n做取余时,等价于对2^n-1做与运算,与运算相对于取余运算性能上要厉害的多。
1.5 HashSet底层用HashMap来实现的
是一个用来存储不重复的元素的集合,用到了HashMap的KEY,不过HashSet的所有value都是都是同一个Object,无太大意义。
1.6 HashMap的具体实现
put操作:先计算hash,再通过hash与hashmap的容积取模计算,得到一个index,把元素放在这个index对应的链表后面。当元素数量超过(临界值*加载因子,默认加载因子是0.75)会进行扩容,数组长度变为之前的长度*2。
这里1.8之前的版本是插入前判断是否扩容,为1.8之后的版本是插入之后判断是否扩容。
1.8版本同时加了优化,扩容是resize保持之前的顺序,避免出现死循环。
1.8版本还优化了链表,将桶的数量超过64且链表长度大于8的链表转化为红黑树。
get操作:先计算hash,在根据hash找到对应的桶,从桶里找到对应的元素返回。
remove操作:计算hash,根据hash找打对应的同,从桶里找到对应的元素删除。
resize操作:先创建一个新的数组链表,容量为之前的两倍。再把原hashmap里的元素rehash到新的数组链表里。
2 ConcurrentHashMap
2.1 java1.7版本的ConcurrentHashMap
1.7版本中ConcurrentHashMap的数据结构是由一个segment数组和对各HashEntry组成的,HashEntry数组链表结构的每一个元素。这个版本中的核心思想就是将一个大的table分割成多个小的segment来进行加锁(锁分离技术)。
segment继承ReentrantLock,segment里的主要变量有:
table:链表数组,每个数组元素是一个hash链表的头部。table是volatile的,使得每次都能读取到最新的table值而不需要同步。
count:Segment中元素的数量。
modCount:对table的结构进行修改的次数。
threshold:若 Segment 里的元素数量超过这个值,则就会对 Segment 进行扩容。
loadFactor:负载因子,threshold = capacity * threshold。
put操作:通过两次hash定位,一次用来定位segment,第二次hash操作用来定位对应的HashEntry位置。在插入元素时会通过ReentrantLock的方式去获取锁,插入完成后释放锁。
get操作:两次hash操作,第一次定位segment的位置,第二次定位hashEntry的位置,返回对应的元素。
size操作:先直接遍历两次,计算每个segment中的元素数量是否一致,完全一致就认为计算结果准确,返回;如果发现不一致,则将所以segment加上锁,再计算并返回。
2.2 java1.8版本的ConcurrentHashMap
java1.8摒弃了segment,采用Node数组+链表+红黑树的数据结构来实现。并发控制用synchronized锁和CAS锁来实现。
相比较于1.7,锁的粒度变的更小了,数据结构也更像hashmap。
1.8用synchronized代替ReentrantLock的原因:在粗粒度中,ReentrantLock有Condition控制各个边界更加灵活,而在更细的粒度中,这个优势不复存在。而且synchronized关键字用起来也是更加的自然,性能上相差也并不是很大。
List下的集合
1 ArrayList
arrayList内部使用object数组实现的,其大小是可以扩充的。由于是基于数组的,故其随机访问效率高O(1),而数据的插入与删除效率会低O(N)。
元素超过capcity会进行扩容,扩容至之前的1.5倍。扩容具体是先创建一个新的数组,再将原来的数组元素复制到新数组,再加上新增元素。
初始化容量为10。
线程不安全。
创建线程安全的 ArrayList 可以使用 Collections.synchronizedList 进行包装或者并发包下的 CopyOnWriteArrayList 类。
2 LinkedList
LinkList 对于随机访问效率是比较低的,因为它需要从头开始索引,所以其时间复杂度为O(i)。但是对于元素的增删,LinkList效率高,因为只需要修改前后指针即可,其时间复杂度为O(1)。
不可以在初始化时候指定大小,每次向其中加入元素时候,容量自动加1。
3 Vector
一般很少使用,是个线程安全的list,底层与ArrayList一样是使用object数组实现的。对其内部的每个方法都加了synchronized锁。性能很低。
Queue下的队列集合
1 LinkedBlockingQueue
链表实现的有界阻塞队列,默认大小为Integer.MAX_VALUE。
2 priorityQueue
优先级队列,底层由堆来实现,可以通过自定义Comparator来实现具体的优先级。线程不安全,相对应的安全的是priorityBlockingQueue。
fail-fast机制
在对collection迭代时,某线程对集合做了修改,会报出ConcurrentModificationException的异常