敏捷数据科学—大数据项目中的敏捷开发
什么是敏捷开发
2001年,Kent Beck和其他16位知名软件从业者共同签署了下面的这份“敏捷软件开发宣言”:
我们正在通过亲身实践 以及帮助他人实践的方式来揭示更好的软件开发之路,通过这项工作,我们认识到:
· 个人和他们之间的交流胜过了开发过程和工具
· 可运行的软件胜过了宽泛的文档
· 客户合作胜过了合同谈判
· 对变更的良好响应胜过了按部就班地遵循计划
也就是说,虽然上述右边各项很有价值,但我们认为左面的各项具有更大的价值。
之所以有这份宣言的出现,是因为一部分人不满足于传统软件开发过程为了适应需求变更而付出的昂贵成本。
在现代经济生活中,市场变化迅速、用户需求变更无法控制、新的竞争对手不断出现,因此很多情况下需求变更成为常态。
在传统软件过程中需求变更需要重新进行设计、修改、测试、评审并因此产生巨大的变更成本。为了适应这种变化,必须采用一种敏捷过程以拉低需求变更的成本。
敏捷数据科学
敏捷数据科学能否照搬软件的敏捷开发?答案是否定的。数据科学相比较于普通软件开发增加了不确定性(即不确定早期建立的数据模型是否可用)、研究团队和工程团队的合作。
传统的数据科学是一门严肃的研究,需要花费很长时间的从原始数据中构建有效的数据模型,这带给应用开发者很大的压力,因为等待数据模型完善的过程中,往往已错过了最佳的上市时间,并且每一次需求变更都会带来巨大的时间和其他成本。
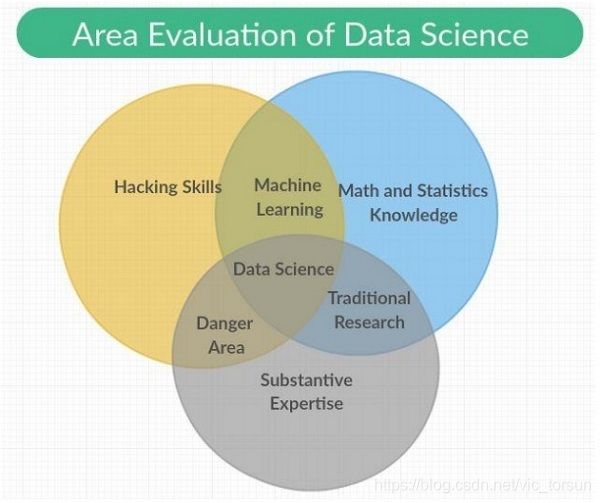
因此诞生了敏捷数据科学,它的目标是记录探索数据分析的过程并促进和指导这一过程,以期发现实现一款引人注目的数据分析产品的关键路径,并沿着这条路走下去。
敏捷数据科学深入本质,关注探索数据分析的过程,并记录在过程中收获的认知。敏捷数据分析把这些当作产品的主要工作。通过抓住本质,我们把整个过程的焦点放在可预测的事务上,而不是放在产品不可预测的输出上,这样便于我们管理整个过程。
敏捷数据科学是一种围绕网络应用开发展开的数据科学实践。敏捷数据科学认为,适用于机构中发挥作用的数据科学过程的最有效输出应为网络应用程序。它还认为应用开发是数据科学家的基本技能。
因此,从事数据科学变成了构建用于描述应用程序,包括快速的原型设计、探索性数据分析、交互式可视化以及应用机器学习。
敏捷数据科学宣言
敏捷数据科学是围绕下面这几条原则进行组织的。
- 迭代,迭代,再迭代
- 发布阶段性结果
- 原型实验高于实施任务
- 在产品管理中仔细考虑数据的情况
- 上下求索于数据价值金字塔
- 找到实现杀手级产品的关键路径并遵照执行
- 抓住本质
一、迭代,迭代,再迭代
构建准确的用的数据模型可能需要经过多轮特征工程和超参数调优。在数据科学中,迭代是提取、可视化以及产品化不可或缺的环节。构建数据科学应用就意味着迭代。
二、发布阶段性结果
迭代是构建分析型应用不可或缺的行为,这意味着每个周期结束时我们都会留下一些难以解决的遗憾。但如果我们不在周期结束前发布暂未完成的阶段性作品,那就无法称作敏捷开发。
在敏捷数据科学中,我们记录和分享我们在工作中创建的未完成的数据。我们把所有工作都提交到代码管理系统中,我们定期与团队成员分享工作成果,也应尽快与最终用户分享。
三、原型实验高于实施任务
数据科学与传统软件工程的不同之处之一就在于它一般是研究一半是工程。在软件工程中,产品经理让开发者在某个阶段完成一张图表的开发。开发者将这个任务转换为具体的代码语句,并创建一个网页用于展示。在数据分析项目中这样任务就完成了吗?没有,如此具体的图表不大可能有什么数据分析价值。
管理数据科学团队意味着监督多个并行开展的实验,而不仅仅是分配任务。良好的数据资产(表格、图表、报表、预测)是作为探索性数据分析的结果出现的,所以我们应该多从实验的立场思考问题而不是完成任务的立场。
四、在产品管理中仔细考虑数据的情况
能做成什么与想做成什么一样重要。知道孰难孰易与知道需要什么一样重要。在软件开发中,有三个方面需要考虑:客户、开发人员、业务。而在分析型应用程序开发中,还有一个方面需要考虑:数据。如果不掌握数据对于某个功能“不得不说的意见”,产品负责人就不算尽职。在产品讨论中要始终考虑数据的情况,这意味着产品讨论必须以可视化为基础,我们的工作重点在于通过内部应用程序进行探索性数据分析。
五、上下求索于数据价值金字塔
数据价值金字塔是模仿马斯洛需求层次理论发展出的五层金字塔模型。它表达了原始数据经过表格、图表、报表到预测模型的层层提炼所包含的越来越多的价值,每一层的目的都是提供更多行为依据或是改进现有的行为:
- 数据价值金字塔的第一层(记录)与连通(plumbing)有关,目的在于打通数据集从采集到在应用中展示之间的流程。
- 图表(chart)和表格(table)层是数据优化和分析的起点。
- 报表(report)层提供沉浸式数据探索,帮助推理并了解数据。
- 预测(prediction)层创造了更多价值,但要创建好的预测模型,就需要进行特征工程,这需要低层的支持。
- 最后一层,行动(action)层,它是人工智能热潮发挥作用的一层。如果你所得出的见解无法产生新的行动或是改进现有行动,那这个见解就不那么有价值。

数据价值金字塔为我们的工作制订了提纲。我们应该不仅仅要把这个金字塔当作要遵守的规则,还要时刻牢记在心。有的时候你会跳过一些步骤,有的时候你会搞错顺序。如果直接把新数据放到预测模型中,而且不在底层把数据添加到应用的数据模型中使得数据集可以访问且对于应用透明,那么技术债就来了。你需要牢记,应该尽可能减少技术债。
六、找到实现杀手级产品的关键路径并遵照执行
为了尽可能地提高我们成功的概率,我们应该把大多数时间放在应用程序对于成功最重要的部分上。但是最重要的是哪部分呢?这需要通过实验才知道。分析型产品的开发就是搜寻和追求移动的目标。
一旦确定了一个目标,比如要做出预测,我们就必须找到实现目标的关键路径。如果这个目标被证明是有价值的,我们还要找到改进的关键路径。随着一个又一个任务的处理,数据被逐步提炼。分析型产品常常需要多个阶段的提炼,涉及ETL(提取、转化、加载)过程、统计学技术、信息访问、机器学习、人工智能、图分析等。
这些阶段的互动可以形成复杂的依赖网。团队领导者应当掌握依赖网。他的工作就是确保团队发现关键路径,然后组织团队按关键路径完成。产品经理无法自上而下管理关键路径,相反这应当由产品科学家自下而上找到。
七、 抓住本质
如果我们无法轻易按照开发常规应用的日程交付做好产品,那我们交付什么呢?如果不交付,我们就没有做到敏捷。为了解决这个问题,在敏捷数据科学中,我们“抓住本质”。核心就是记录分析过程,而不是我们要开发的应用的终极状态。在迭代攀登数据价值金字塔的过程中交付阶段性内容,遵循杀手级产品的关键路径,这让我们能够敏捷。所以,产品到底从何而来?从记录探索性数据分析的过程而来。
小结
这七条原则共同驱动了敏捷数据科学方法学。它们为探索性数据分析,并且据此为构建分析型应用程序提供了框架和参考。可以说这是敏捷数据科学的核心。
参考
- 《软件工程》(原书第10版)
- 《Spark 全栈数据分析》