我们知道 HashMap 是一种键值对形式的数据存储容器,但是它有一个缺点是,元素内部无序。由于它内部根据键的 hash 值取模表容量来得到元素的存储位置,所以整体上说 HashMap 是无序的一种容器。当然,jdk 中也为我们提供了基于红黑树的存储的 TreeMap 容器,它的内部元素是有序的,但是由于它内部通过红黑结点的各种变换来维持二叉搜索树的平衡,相对复杂,并且在并发环境下碍于 rebalance 操作,性能会受到一定的影响。
跳表(SkipList)是一种随机化的数据结构,通过“空间来换取时间”的一个算法,建立多级索引,实现以二分查找遍历一个有序链表。时间复杂度等同于红黑树,O(log n)。但实现却远远比红黑树要简单,本篇我们主要从以下几个方面来对这种并发版本的数据结构进行学习:
- 跳跃表的数据结构介绍
- ConcurrentSkipListMap 的前导知识预备
- 基本的成员属性介绍
- put 方法并发添加
- remove 方法的并发删除
- get 方法获取指定结点的 value
- 其它的一些方法的简单描述
一、跳跃表的数据结构介绍

跳跃表具有以下几个必备的性质:
- 最底层包含所有节点的一个有序的链表
- 每一层都是一个有序的链表
- 每个节点都有两个指针,一个指向右侧节点(没有则为空),一个指向下层节点(没有则为空)
- 必备一个头节点指向最高层的第一个节点,通过它可以遍历整张表
当我们查找一个元素的时候就是这样的:

查找的过程有点像我们的二分查找,不过这里我们是通过为链表建立多级索引,以空间换时间来实现二分查找。所以,跳表的查询操作的时间复杂度为 O(logN)。
接着我们看看跳表的插入操作:
首先,跳表的插入必然会在底层增加一个节点,但是往上的层次是否需要增加节点则完全是随机的,SkipList 通过概率保证整张表的节点分布均匀,它不像红黑树是通过人为的 rebalance 操作来保证二叉树的平衡性。(数学对于计算机还是很重要的)。
通过概率算法得到新插入节点的一个 level 值,如果小于当前表的最大 level,从最底层到 level 层都添加一个该节点。例如:

如图,首先 119 节点会被添加到最底层链表的合适位置,然后通过概率算法得到 level 为 2,于是 1---level 层中的每一层都添加了 119 节点。
如果概率算法得到的 level 大于当前表的最大 level 值的话,那么将会新增一个 level,并且将新节点添加到该 level 上。

跳表的删除操作其实就是一个查找加删除节点的操作

好了,有关跳表这种数据结构的基本理论知识已经简单的介绍了,下面我们看 jdk 中对该数据结构的基本实现情况,并了解它的并发版本是如何实现的。
二、ConcurrentSkipListMap 的前导知识预备
在实际分析 put 方法之前,有一些预备的知识我们需要先有个大致的了解,否则在实际分析源码的时候会感觉吃力些。
首先是删除操作,在我们上述的跳表数据结构中谈及的删除操作主要是定位待删结点+删除该结点的一个复合操作。而在我们的并发跳表中,删除操作相对复杂点,需要分为以下三个步骤:
- 找到待删结点并将其 value 属性值由 notnull 置为 null,整个过程是基于 CAS 无锁式算法的
- 向待删结点的 next 位置新增一个 marker 标记结点,整个过程也是基于 CAS 无锁式算法
- CAS 式删除具体的结点,实际上也就是跳过该待删结点,让待删结点的前驱节点直接越过本身指向待删结点的后继结点即可
例如我们有以下三个结点,n 为待删除的结点。
+------+ +------+ +------+
... | b |------>| n |----->| f | ...
+------+ +------+ +------+
第一步是找到 n ,然后 CAS 该结点的 value 值为 null。如果该步骤失败了,那么 ConcurrentSkipListMap 会通过循环再次尝试 CAS 将 n 的 value 属性赋值为 null。
第二步是建立在第一步成功的前提下的,n 的当前 value 属性的值为 null,ConcurrentSkipListMap 试图在 n 的后面增加一个空的 node 结点(marker)以分散下一步的并发冲突性。
+------+ +------+ +------+ +------+
... | b |------>| n |----->|marker|---->| f | ...
+------+ +------+ +------+ +------+
第三步,断链操作。如果 marker 添加失败,将不会有第三步,直接回重新回到第一步。如果成功添加,那么将试图断开 b 到 n 的链接,直接绕过 n,让 b 的 next 指向 f。那么,这个 n 结点将作为内存中的一个游离结点,最终被 GC 掉。断开失败的话,也将回到第一步。
+------+ +------+
... | b |----------------------->| f | ...
+------+ +------+
主要还是有关删除这方面的预备知识,其它的信息点我们将从实际方法的源码中再进行分析。
三、基本的成员属性介绍
static final class Node {
final K key;
volatile Object value;
volatile Node next;
Node(K key, Object value, Node next) {
this.key = key;
this.value = value;
this.next = next;
}
//省略其它的一些基于当前结点的 CAS 方法
} 这是 node 结点类型的定义,是最基本的数据存储单元。
static class Index {
final Node node;
final Index down;
volatile Index right;
Index(Node node, Index down, Index right) {
this.node = node;
this.down = down;
this.right = right;
}
//省略其它的一些基于当前结点的 CAS 方法
} Index 结点封装了 node 结点,作为跳表的最基本组成单元。
static final class HeadIndex extends Index {
final int level;
HeadIndex(Node node, Index down, Index right, int level) {
super(node, down, right);
this.level = level;
}
} 封装了 Index 结点,作为每层的头结点,level 属性用于标识当前层次的序号。
/**
* The topmost head index of the skiplist.
*/
private transient volatile HeadIndex head; 整个跳表的头结点,通过它可以遍历访问整张跳表。
//比较器,用于比较两个元素的键值大小,如果没有显式传入则默认为自然排序
final Comparator comparator;/**
* Special value used to identify base-level header
* 特殊的值,用于初始化跳表
*/
private static final Object BASE_HEADER = new Object();紧接着,我们看看它的几个构造器:
//未传入比较器,则为默认值
public ConcurrentSkipListMap() {
this.comparator = null;
initialize();
}
public ConcurrentSkipListMap(Comparator comparator) {
this.comparator = comparator;
initialize();
}//所有的构造器都会调用这个初始化的方法
private void initialize() {
keySet = null;
entrySet = null;
values = null;
descendingMap = null;
head = new HeadIndex(new Node(null, BASE_HEADER, null),null, null, 1);
} 这个初始化方法主要完成的是对整张跳表的一个初始化操作,head 头指针指向这个并没有什么实际意义的头结点。
基本的成员属性就简单介绍到这,重点还是那三个内部类,都分别代表了什么样的结点类型,都使用在何种场景下,务必清晰。
四、put 并发添加的内部实现
//基本的 put 方法,向跳表中添加一个节点
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}put 方法的内部调用的是 doPut 方法来实现添加元素的,但是由于 doPut 方法的方法体很长,我们分几个部分进行分析。
//第一部分
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node z;
//边界值判断,空的 key 自然是不允许插入的
if (key == null)
throw new NullPointerException();
//拿到比较器的引用
Comparator cmp = comparator;
outer: for (;;) {
//根据 key,找到待插入的位置
//b 叫做前驱节点,将来作为新加入结点的前驱节点
//n 叫做后继结点,将来作为新加入结点的后继结点
//也就是说,新节点将插入在 b 和 n 之间
for (Node b = findPredecessor(key, cmp), n = b.next;;) {
//如果 n 为 null,那么说明 b 是链表的最尾端的结点,这种情况比较简单,直接构建新节点插入即可
//否则走下面的判断体
if (n != null) {
Object v; int c;
Node f = n.next;
//如果 n 不再是 b 的后继结点了,说明有其他线程向 b 后面添加了新元素
//那么我们直接退出内循环,重新计算新节点将要插入的位置
if (n != b.next)
break;
//value =0 说明 n 已经被标识位待删除,其他线程正在进行删除操作
//调用 helpDelete 帮助删除,并退出内层循环重新计算待插入位置
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
//b 已经被标记为待删除,前途结点 b 都丢了,可不得重新计算待插入位置吗
if (b.value == null || v == n)
break;
//如果新节点的 key 大于 n 的 key 说明找到的前驱节点有误,按序往后挪一个位置即可
//回到内层循环重新试图插入
if ((c = cpr(cmp, key, n.key)) > 0) {
b = n;
n = f;
continue;
}
//新节点的 key 等于 n 的 key,这是一次 update 操作,CAS 更新即可
//如果更新失败,重新进循环再来一次
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
break;
}
}
//无论遇到何种问题,到这一步说明待插位置已经确定
z = new Node(key, value, n);
if (!b.casNext(n, z))
break;
//如果成功了,退出最外层循环,完成了底层的插入工作
break outer;
}
} 以上这一部分主要完成了向底层链表插入一个节点,至于其中具体的怎么找前驱节点的方法稍后介绍。但这其实只不过才完成一小半的工作,就像红黑树在插入后需要 rebalance 一样,我们的跳表需要根据概率算法保证节点分布稳定,它的调节措施相对于红黑树来说就简单多了,通过往上层索引层添加相关引用即可,以空间换时间。具体的我们来看:
//第二部分
//获取一个线程无关的随机数,占四个字节,32 个比特位
int rnd = ThreadLocalRandom.nextSecondarySeed();
//和 1000 0000 0000 0000 0000 0000 0000 0001 与
//如果等于 0,说明这个随机数最高位和最低位都为 0,这种概率很大
//如果不等于 0,那么将仅仅把新节点插入到最底层的链表中即可,不会往上层递归
if ((rnd & 0x80000001) == 0) {
int level = 1, max;
//用低位连续为 1 的个数作为 level 的值,也是一种概率策略
while (((rnd >>>= 1) & 1) != 0)
++level;
Index idx = null;
HeadIndex h = head;
//如果概率算得的 level 在当前跳表 level 范围内
//构建一个从 1 到 level 的纵列 index 结点引用
if (level <= (max = h.level)) {
for (int i = 1; i <= level; ++i)
idx = new Index(z, idx, null);
}
//否则需要新增一个 level 层
else {
level = max + 1;
@SuppressWarnings("unchecked")
Index[] idxs =(Index[])new Index[level+1];
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index(z, idx, null);
for (;;) {
h = head;
int oldLevel = h.level;
//level 肯定是比 oldLevel 大一的,如果小了说明其他线程更新过表了
if (level <= oldLevel)
break;
HeadIndex newh = h;
Node oldbase = h.node;
//正常情况下,循环只会执行一次,如果由于其他线程的并发操作导致 oldLevel 的值不稳定,那么会执行多次循环体
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex(oldbase, newh, idxs[j], j);
//更新头指针
if (casHead(h, newh)) {
h = newh;
idx = idxs[level = oldLevel];
break;
}
}
} 这一部分的代码主要完成的是根据 level 的值,确认是否需要增加一层索引,如果不需要则构建好底层到 level 层的 index 结点的纵向引用。如果需要,则新创建一层索引,完成 head 结点的指针转移,并构建好纵向的 index 结点引用。
//第三部分
if ((rnd & 0x80000001) == 0){
//省略第二部分的代码段
//第三部分的代码是紧接着第二部分代码段后面的
splice: for (int insertionLevel = level;;) {
int j = h.level;
for (Index q = h, r = q.right, t = idx;;) {
//其他线程并发操作导致头结点被删除,直接退出外层循环
//这种情况发生的概率很小,除非并发量实在太大
if (q == null || t == null)
break splice;
if (r != null) {
Node n = r.node;
int c = cpr(cmp, key, n.key);
//如果 n 正在被其他线程删除,那么调用 unlink 去删除它
if (n.value == null) {
if (!q.unlink(r))
break;
//重新获取 q 的右结点,再次进入循环
r = q.right;
continue;
}
//c > 0 说明前驱结点定位有误,重新进入
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
//尝试着将 t 插在 q 和 r 之间,如果失败了,退出内循环重试
if (!q.link(r, t))
break; // restart
//如果插入完成后,t 结点被删除了,那么结束插入操作
if (t.node.value == null) {
findNode(key);
break splice;
}
// insertionLevel-- 处理底层链接
if (--insertionLevel == 0)
break splice;
}
//--j,j 应该与 insertionLevel 同步,它代表着我们创建的那个纵向的结点数组的索引
//并完成层次下移操作
if (--j >= insertionLevel && j < level)
t = t.down;
//至此,新节点在当前层次的前后引用关系已经被链接完成,现在处理下一层
q = q.down;
r = q.right;
}
}
}
return null;
} 我们根据概率算法得到了一个 level 值,并且通过第二步创建了 level 个新节点并构成了一个纵向的引用关联,但是这些纵向的结点并没有链接到每层中。而我们的第三部分代码就是完成的这个工作,将我们的新节点在每个索引层都构建好前后的链接关系。下面用三张图描述着三个部分所完成的主要工作。
初始化的跳表如下:
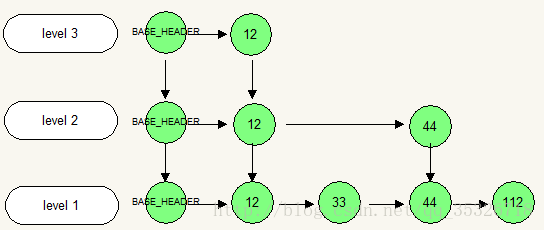
第一部分,新增一个结点到最底层的链表上。

第二部分,假设概率得出一个 level 值为 10,那么根据跳表的算法描述需要新建一层索引层。

第三步,链接各个索引层次上的新节点。

这样就完成了新增结点到跳表中的全部过程,大体上已如上图描述,至于 ConcurrentSkipListMap 中关于并发处理的细节之处,图中无法展示,大家可据此重新感受下源码的实现过程。下面我们着重描述下整个 doPut 方法中还涉及的其他几个方法的具体实现。
首先是 findPredecessor 方法,我们说该方法将根据给定的 key,为我们返回最合适的前驱节点。
private Node findPredecessor(Object key, Comparator cmp) {
if (key == null)
throw new NullPointerException();
for (;;) {
for (Index q = head, r = q.right, d;;) {
//r 为空说明 head 后面并没有其他节点了
if (r != null) {
Node n = r.node;
// r 节点处于待删除状态,那么尝试 unlink 它,失败了将重新进入循环再此尝试
//否则重新获取 q 的右结点并重新进入循环查找前驱节点
if (n.value == null) {
if (!q.unlink(r))
break; // restart
r = q.right; // reread r
continue;
}
//大于零说明当前位置上的 q 还不是我们要的前驱节点,继续往后找
if (cpr(cmp, key, k) > 0) {
q = r;
r = r.right;
continue;
}
}
//如果当前的 level 结束了或者 cpr(cmp, key, k) <= 0 会达到此位置
//往低层递归,如果没有低层了,那么当前的 q 就是最合适的前驱节点
//整个循环只有这一个出口,无论如何最终都会从此处结束方法
if ((d = q.down) == null)
return q.node;
//否则向低层递归并重置 q 和 r
q = d;
r = d.right;
}
}
} 最后总结下 findPredecessor 方法的大体逻辑,首先程序会从 head 节点开始在当前的索引层上寻找最后一个比给定 key 小的结点,它就是我们需要的前驱节点(q),我们只需要返回它即可。
其次我们看看 helpDelete 方法,当检测到某个结点的 value 属性值为 null 的时候,一般都会调用这个方法来删除该结点。
/*
一般的调用形式如下:
n.helpDelete(b, f);
*/
void helpDelete(Node b, Node f) {
if (f == next && this == b.next) {
if (f == null || f.value != f)
casNext(f, new Node(f));
else
b.casNext(this, f.next);
}
} 该方法是 Node 结点的内部实例方法,逻辑相对简单,此处不再赘述。通过该方法可以完成将 b.next 指向 f,完成对 n 结点的删除。
至此,有关 put 方法的源码分析就简单到这,大部分的代码还是用于实现跳表这种数据结构的构建和插入,关于并发的处理,你会发现基本都是双层 for 循环+ CAS 无锁式更新,如果遇到竞争失利将退出里层循环重新进行尝试,否则成功的话就会直接 return 或者退出外层循环并结束 CAS 操作。下面我们看删除操作是如何实现的。
五、remove 并发删除操作的内部实现
remove 方法的部分内容我们在介绍相关预备知识中已经提及过,此处的理解想必会容易些。
public V remove(Object key) {
return doRemove(key, null);
}//代码比较多,建议读者结合自己的 jdk 源码共同来分析
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator cmp = comparator;
outer: for (;;) {
//找到 key 的前驱节点
//因为删除不单单是根据 key 找到对应的结点,然后赋 null 就完事的,还要负责链接该结点前后的关联
for (Node b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
//目前 n 基本上就是我们要删除的结点,它为 null,那自然不用继续了,已经被删除了
if (n == null)
break outer;
Node f = n.next;
//再次确认 n 还是不是 b 的后继结点,如果不是将退出里层循环重新进入
if (n != b.next)
break;
//如果有人正在删除 n,那么帮助它删除
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
//b 被删除了,重新定位前驱节点
if (b.value == null || v == n)
break;
//正常情况下,key 应该等于 n.key
//key 大于 n.key 说明我们要找的结点可能在 n 的后面,往后递归即可
//key 小于 n.key 说明 key 所代表的结点根本不存在
if ((c = cpr(cmp, key, n.key)) < 0)
break outer;
if (c > 0) {
b = n;
n = f;
continue;
}
//如果删除是根据键和值两个参数来删除的话,value 是不为 null 的
//这种情况下,如果 n 的 value 属性不等于我们传入的 value ,那么是不进行删除的
if (value != null && !value.equals(v))
break outer;
//下面三个步骤才是整个删除操作的核心,大致的逻辑我们也在上文提及过了,此处想必会容易理解些
//第一步,尝试将待删结点的 value 属性赋值 null,失败将退出重试
if (!n.casValue(v, null))
break;
//第二步和第三步如果有一步由于竞争失败,将调用 findNode 方法根据我们第一步的成果,也就是删除所有 value 为 null 的结点
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key);
//否则说明三个步骤都成功完成了
else {
findPredecessor(key, cmp);
//判断此次删除后是否导致某一索引层没有其他节点了,并适情况删除该层索引
if (head.right == null)
tryReduceLevel();
}
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
}
return null;
} remove 方法其实从整体上来看,首先会有一堆的判断,根据给定的 key 和 value 会判断是否存在与 key 对应的一个节点,也会判断和待删结点相关的前后结点是否正在被删除,并适情况帮助删除。其次才是删除的三大步骤,核心步骤还是将待删结点的 value 属性赋 null 以标记该结点无用了,至于这个 marker 也是为了分散并发冲突的,最后通过 casNext 完成结点的删除。
六、get 方法获取指定结点的 value
算上本小节将要介绍的 "查" 方法,我们就完成了对并发跳表 "增删改查" 的全部分析。 相对于“增”来说,其他的三种操作还是相对容易的,尤其是本小节的“查”操作,下面我们看看它的内部实现:
public V get(Object key) {
return doGet(key);
}private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator cmp = comparator;
//依然是双层循环来处理并发
outer: for (;;) {
for (Node b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
//以下的一些判断的作用已经描述了多次,此处不再赘述了
if (n == null)
break outer;
Node f = n.next;
if (n != b.next)
break;
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n)
break;
//c = 0 说明 n 就是我们要的结点
if ((c = cpr(cmp, key, n.key)) == 0) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
//c < 0 说明不存在这个 key 所对应的结点
if (c < 0)
break outer;
b = n;
n = f;
}
}
return null;
} doGet 方法的实现相对还是比较简单的,所以并没有给出太多的注释,主要还是由于大量的并发判断的代码都是一样的,大多都已经在 doPut 方法中给予了详细的注释了。
七、其它的一些方法的简单描述
//是否包含指定 key 的结点
public boolean containsKey(Object key) {
return doGet(key) != null;
}//根据 key 返回该 key 所代表的结点的 value 值,不存在该结点则返回默认的 defaultValue
public V getOrDefault(Object key, V defaultValue) {
V v;
return (v = doGet(key)) == null ? defaultValue : v;
}//返回跳表的实际存储元素个数,采取遍历来进行统计
public int size() {
long count = 0;
for (Node n = findFirst(); n != null; n = n.next) {
if (n.getValidValue() != null)
++count;
}
return (count >= Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) count;
} //返回所有键的集
public NavigableSet keySet() {
KeySet ks = keySet;
return (ks != null) ? ks : (keySet = new KeySet(this));
} //返回所有值的集
public Collection values() {
Values vs = values;
return (vs != null) ? vs : (values = new Values(this));
} 这里需要说明一点的是,虽然返回来的是键或者值的一个集合,但是无论你是通过这个集合获取键或者值,还是删除集合中的键或者值,都会直接映射到当前跳表实例中。原因是这个集合中没有一个方法是自己实现的,都是调用传入的跳表实例的内部方法,具体的大家查看源码即可知晓,此处不再贴出源码。
至此,有关 SkipList 这种跳表数据结构及其在 jdk 中的实现,以及它的并发版本 ConcurrentSkipListMap 的实现,我们都已经简单的分析完了,有理解错误之处,望指出,相互学习!
参考的几篇优秀博文
Java并发容器之SkipList(需要***)
深入Java集合学习系列:ConcurrentSkipListMap实现原理
Java多线程(四)之ConcurrentSkipListMap深入分析