正则表达式
简单模式:匹配$_中的内容,只需要将模式写在一对斜线(/)中就可以了。
如:#!/usr/bin/env perl
use 5.010;
$_="yabba dabba doo";
if(/abba/){
say "it matched!";
}
关于元字符
和shell中的差不多:
.==>任意字符;
*==>重复0次及其0次以上;
+==>重复一次及一次以上;
?==>重复0次或一次;
模式分组
在正则表达式中,用圆括号()对字符串分组。
反向引用的写法是在斜线后面接上数字编号,如\1 \2这样。相应的数字表示对应顺序的捕获组。
下面举例说明:

反向引用也不必进接在对应的捕获组的后面。下面的模式或匹配y后面的4个连续的非换行符,并用\1反向引用表示匹配d后也出现的4个字符的情况。
$_=”yabba dabba doo”;
If (/y(....) d\1/){
Print “It matched the same after y and d!\n”;
}
也可以用多个括号来分成多组,每个组都可以有自己的反向引用。
$_=”yabba dabba doo”;
If (/y(.)(.)\2\1/){ #匹配 ‘abba’
Print “It matched the same after y and d!\n”;
}
那么如何区分哪个括号是第几组呢?Larry给出的解释:只要一次点算左括号(包括嵌套括号)的序号就OK了。如:
$_=”yabba dabba doo”;
if (/y((.)(.)\3\2) d\1/){
print “It matched the same after y and d!\n”;
}
拆开:( #第一个括号
(.) #第二个括号
(.) #第三个括号
\3
\2
)
怎么想想这种关系呢?
在我看来,就是\1所对应的括号的内容在\1的这个位置在重复一遍,\2所对应的括号的内容在\2的这个位置在重复一遍。那么如果是(.)(.)\2\1 abba就能匹配,(.)a(.)\2\1那么caddc就能匹配。
上面遗留的问题:
$_=”aa11bb”;
If (/(.)\111/){
print “It matched!\n”;
}
原本是打算匹配aa11 ,现在好了。Perl将其理解为匹配第111组括号,根本找不到这个括号,报错。
解决方法:\g{1} 就可以消除反向引用与模式的直接量部分的二义性。
use 5.010;
$_=”aa11bb”;
If (/(.)\g{1}11/){
print “It matched.”.”\n”;
}
而且用\g{N}还有一个好处就是N可以是负数,也就是说可以为-1 -2等。表示的意思就是倒数或者说相对位置。
-1 表示离\g{-1}最近的第一个左括号;
-2 表示离\g{-2}最近的第二个左括号;
use 5.010;
$_=”aa11bb”;
if (/(.)(.)\g{-1}11/){
print “It matched.”.”\n”;
}
择一匹配
(|)
如:/fred(and|or)barney/
字符集
[a-zA-Z]
[^a-zA-Z]
字符集的简写
表示任意一个数字的字符集简写\d;
$_=’The HAL-9000 requires authorization to continue.’;
if (/HAL-[\d]+/){
say “It matched.”
}
修饰符/a,写在正则表达式末尾,表示按照ASCII的语义展开(从Perl 5.14引入的修饰符):
use 5.014;
$_=’The HAL-9000 requires authorization to continue.’;
If (/HAL-[\d]+/a){ #俺老的ASCII字符解释
say “It matched.”
}
说明:引入/a的主要原因是因为\d 现在的语义不仅再是[0-9]这个范围了,它还表示了很多比较特殊的数字符。
\s能匹配以下5个空白字符:换页符\f 水平制表符\v 垂直制表符\h 回车符\n 空格符\p
use 5.014;
if (/\s/a){ #按老的ASCII字符语义解释
say “The string matched ASCII whitescape”;
}
\R匹配断行符,无论是\r\n还是\n都能匹配。
\w匹配“单词”字符,所谓单词其实是[a-zA-Z0-9]组成的。
反义简写
\D 表示[^\d]
\W 表示[^\w]
\S 表示[^\s]
这些简写既可以做为模式里独立的字符集,也可以作为方括号里字符集的一部分。比如:/[\dA-Fa-f]/
用正则表达式进行匹配
用m//进行匹配
前面所讲的用//写法表示模式,比如/fred/事实上是m/fred/的简写。
通用像qw //一样,分隔符也是可选的如:m{fred} m
模式修饰符
/a 表示按照ASCII的语义展开
/i 表示进行大小写无关的匹配
print “would you like to play a game?”;
chomp($_=
If(/yes/i){ #大小写无关的匹配
say “i like too.”;
}
/s 表示匹配任意字符;
在很多情况下(.)是没有办法匹配到换行符的,但如果字符串中含有换行符,而你有希望匹配这些换行符,那么就可以用/s修饰符完成。(实现原理是,Perl会将点号转换成字符集[\d\D]来处理,就是说会匹配任意字符)
$_=”I saw Barney\n down at the bowling alley\nwith Fred\nlast night.\n”;
If (/Barney.*Fred/s){
Print “That string mentions Fred after Barney\n”;
}
出现的问题:/s会把模式中所出现的.都修改成能匹配任意字符,那如果我们只是想其中几个匹配任意字符呢?可以用\N(不太懂???)
/x 表示加入空白符;
![]()
举例如下:
#!/usr/bin/env perl
use 5.010;
$_="fred";
if(/fre d/x){
say "it matched."
}
![]()
当然上面的修饰符都可以组合:
if(/barney.*fred/is){#同时使用/i和/s
print “That string mentions Fred after Barney!\n”;
}
锚位(5.010以后)
默认情况下,如果给定模式不匹配字符串的开头,就会顺移到下一个字符继续尝试。而通过锚位我们可以让模式仅在字符串指定位置匹配。
\A锚位匹配字符串的绝对开头,也就是说如果开头不匹配就会顺移到下一个位置继续尝试;如:m{\Ahttp://i}此处用{}作为界定符而不用//,主要就是为了和http://中的反斜线进行区分;
\z 锚位匹配字符串的绝对末尾,如:m{\.png\z}i (注意如果一行包含了换行符,他也会进行匹配。如 i am picture.png\n 就匹配不上了。所以要么去掉换行符要么使用下面的\Z )
\Z 锚位运行末尾出现换行符;
有时候可能需要同时匹配行首和行尾,如:/\A\s*\Z/ 匹配的就是一个空行;
当然也可以用^和$.
可以用$锚位和/m修饰符表示对多行内容进行匹配;同样^和$也有类似的作用,下面举例说明:
#!/usr/bin/env perl
use 5.010;
$_="This is a wilma line
fred barney is on another line
hello,fred
you are a good fred line
";
if(/\Afred/){
say "It matched.";
}
上面内容不能匹配。
改为:if(/^fred/m)
便能进行匹配;
同样:如果是 if(/fred\z/)不能匹配;
如果是if(/fred$/m)则能进行匹配;
大部分用个还是$和^,配合/m使用。谨慎使用\A和\z 。
单词锚位
\b 进行单词边界锚位,它匹配任何单词的首尾;(此处所说的单词和\w+ 意思相似)
如:/\bfred\b/可以匹配fred,但是不能匹配frederick alfred manfredmanm等。这种情况通常称为“整词匹配”。
绑定操作符=~
默认情况下模式匹配的操作对象是$_,绑定操作符=~告诉Perl需要拿右边的模式来匹配左边的字符串,而不是匹配$_。
my $some_other="I dream of betty rubble.";
if($some_other =~ /\brub/){
print "Aye,there is the rub.";
}
模式的内插
#!/usr/binenv perl -w
my $what="larry";
while(<>){
if(/\A($what)/){
print "$what in begining of $_."
}
}
很多时候what的值不一定要直接写在变量中,可以通过@ARGV取得命令参数。
如果$what=(fred/barney) 则匹配时要么匹配fred 要么匹配barney。
但如果$what=fred(barney 的话,那就变成了/\A(fred(barney)/ 直接报错。
捕获变量
直接用例子说明吧!!!
$_="Hello there,neighbor";
if(/(\S+) (\S+),(\S+)/){ #\S表示非空格
say "words were $1 $2 $3\n"; #注意和\1 \2 \3 做对比
}
结果: words were Hello there neighbor
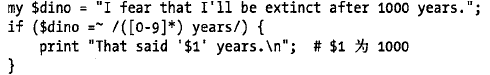
捕获变量的存续期
捕获变量通常能存活到下一次成功匹配为止。也就是说,失败的匹配不会改动上一次成功匹配的内容,而成功的匹配会将他们的值重置。
my $wilma='123';
$wilma=~/([0-9]+)/;#匹配成功,$1的值是123
$wilma=~/([a-zA-Z]+)/; #匹配失败
say "$1"; #现在$1中的内容还是123
这就是为什么匹配模式总是出现在if或者while循环表达式中的原因:
if($wilma =~ /[a-zA-Z]/){
say "$1";
}else{
print "$wilma doesn't have a word."
}
重点:

不捕获模式
前面的所有圆括号都会捕获部分的匹配字符串到变量中,而有时候却需要关闭这个功能。

使用(?:),告诉Perl这一对圆括号完全是为了分组而已。

命名捕获
直接对捕获的内容进行命名,无需用$1 $2 ...
具体就是(?
访问时用:$+{LABEL}

自动捕获变量: $`(匹配前的内容) $&(匹配的内容) $'(匹配后的内容)
if("hello there,neighbor"=~ /\s(\w+),/){
say "That was ($`)($&)($')";
}
![]()
注意输出的结果中,$&=there, 还有一个逗号。

通用量词
/a{5,15}/可以匹配重复出现5到15次的字母a;
/(fred){3,}/匹配三次或者三次以上的fred; /(fred){3}/只匹配重复三次的fred。
提示:运用通用量词便可以实现 * + ? 等的功能。
模式测试程序
编写Perl程序时,每个程序员都免不了要使用正则表达式,但很多时候很难轻易看出一个模式是干嘛用的。而且常常出现匹配的范围总比预期的大些或者小些。
下面这个程序非常实用,可用于检测某些字符串是否能够被指定模式匹配以及在什么位置匹配。

正则表达式用于修改文本
用s///进行替换

![]()
注意上一个模式中 $1 的使用。
一些例子:

用/g进行全局替换

后面除了接/g之外同样还可以接/i /x /s
无损替换
如何在进行替换的同时保留原来的字符串?
传统做法:

现在做法:
![]()
注意括号的位置。
split操作符
目的:根据模式拆分字符串;
基本格式:my @field=split /separator/,$string;
my @field=split /:/,"abc:deg:g:h";#得到("abc","def","g","h")
如果两个分隔符连在一起的话会产生孔子段:
my @fields=split /:/,"abc:def::g:h";#得到("abc","def","","g","h")
注意有一个默认规则:split 会保留开头处的空子段,却会舍弃结尾处的空字段。
my @fileds=split /:/,":::a:b:c:::";#得到("","","","a","b","c")
利用split的/\s+/模式根据空白分隔符字段也是比较常见的用法。如:
my $some_input="This is a \t test.\n";
my @args=split /\s+/,$some_input; #得到("This","is","a","test,")
注意:经测试上面的用例甚至可以把末尾的换行符号都去掉。
默认split会以空白符分隔$_中的字符串:
my @fields=split;#等效于split /\s+/,$_;
join 函数
join的作用和split的恰恰相反。
![]()
join的第一个参数理解为胶水,注意后面列表中至少含有两个元素才行,否则胶水无法涂进去。
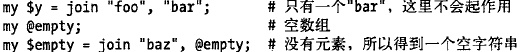
列表上下文中的m//
在使用split时,模式指定的是分隔符:分解得到的字符未必就是我们所需要的数据。所以有时候指定所要的数据反而更加简单。
在列表上下文中用模式匹配操作符(m//)时,如果模式匹配成功,那么返回的是所有捕获变量的列表;如果失败,则返回空列表。
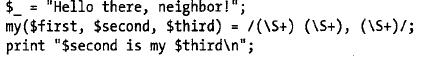
之前在s///的例子中看到的/g修饰符也可以用到m//操作符上,其效果就是让模式能够匹配到字符串中多个地方。

更加强大的正则表达式
非贪婪量词
+? *? ?? 等。
具体解决的问题是什么呢?
看例子:
如果需要去除掉

而出现这样的情况,使用 s#
?? 一样会匹配零次或者一次,但是优先选择零次。
{5,10}? 或者{8,}? 也是支持的。
一次更新多个文件
还是用实例来说明吧!!!(小骆驼pdf 191)
文件fred03.bat中内容如下:
Program name:granite
Author:Gilbert Bates
Company:RockSoft
DepartMent:R&D
Phone:+1 503 555-0095
Date:Tues March 9,2004
Version:2.1
Size:21k
Staus:Final beta
需要修改成下面内容:
Program name:granite
Author:Randal L.Schwartz
Company:RockSoft
DepartMent:R&D
Date: 2015年 07月 23日 星期四 16:30:02 CST
Version:2.1
Size:21k
Staus:Final beta
简单说来有三项需要改动:Author字段姓名要改,Date要改成今天的日期,而Phone则需要删除。
使用的代码:
#!/usr/bin/env perl
use strict;
chomp (my $date =`data`);
$^I=".bak";
while(<>){
s/^Author:.*/Author:Randal L.Schwartz/;
s/^Phone:.*\n//;
s/^Date:.*/Date: $date/;
print;
}
运行结果:

大概过程:$^I的默认值为undef,不会造成什么影响。但是如果将其赋值成某个字符串,如上面的.bak,那么钻石操作符就会有一些不一样.
首先假设钻石操作符正好打开fred03.bat。除了像以前一样打开文件外,他还会把文件名fred03.dat.bak。紧接着钻石操作符会打开一个新文件并取名为fred03.bat。现在钻石操作符会把默认的输出设定为新打开的这个文件,所以输出来的所有内容都会被写进这个文件中。
从命令直接编辑
如果需要更新上百个文件,把里面的Randall的名字改成只有一个l的Randal。一方面可以用上面例子中类似的程序完成,或者使用下面的命令:
$ perl -p -i.bak -w -e 's/Randall/Randal/g' fred*.bat
-p 选项可以让Perl自动生成一个小程序,如下:
while(<>) {
print;
}
-i.bak 的效果和$^I=".bak" 差不多;
-w 当然是warning功能;
-e 则是用来告诉Perl后面跟着的可供执行的程序代码。也就是说s/Randall/Randal/g 这个字符串会直接当作Perl程序代码。
上面命令就类似于下面的代码:
#!/usr/bin/env perl -w
$^I=".bak";
while(<>){
s/Randall/Randal/g;
print;
}