一文了解Shell中的awk命令
前言
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
基本用法
awk的基本用法格式: awk [options] ‘program’ FILE…
语句之间用分号分隔
[options]
-F : 指明输入时用到的字段分隔符
-v var=VALUE : 自定义变量
在awk中变量的引用不需要加$,而是直接引用
为了方便后面的讲解,我们新建一个测试的txt文件。

这里每行的数据我们以空格进行分割。
用法1: awk ‘{[pattern] action}’ {filenames} # 行匹配语句 awk ‘’ 只能用单引号
例如 查看每一行数据的第一列和第四列的内容:
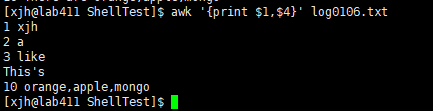
用法2:awk -F #-F相当于内置变量FS, 指定分割字符
例如,使用逗号,进行分割。

用法3:awk -v # 设置变量
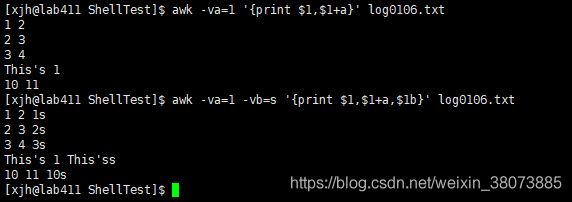
用法4:基本的运算符
例如判断大于或者相等:

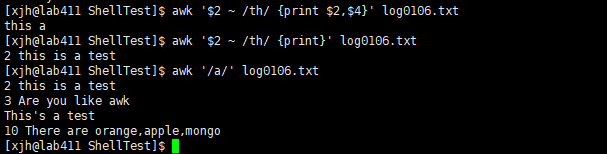
用法5:使用正则表达式进行字符串匹配
例如,下面的例子
- 输出第二列包含“th”,并打印第二列和第四列 或者打印整行
- 输出该文件中国包含"a"的行数据
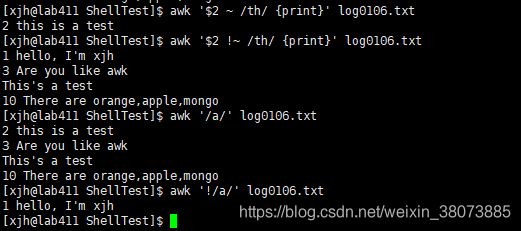
模式取反
内置变量
变量:分为内置变量和自定义变量;输入分隔符FS和输出分隔符OFS都属于内置变量。
内置变量就是awk预定义好的、内置在awk内部的变量,而自定义变量就是用户定义的变量。
FS(Field Separator):输入字段分隔符, 默认为空白字符
OFS(Out of Field Separator):输出字段分隔符, 默认为空白字符
RS(Record Separator):输入记录分隔符(输入换行符), 指定输入时的换行符
ORS(Output Record Separate):输出记录分隔符(输出换行符),输出时用指定符号代替换行符
NF(Number for Field):当前行的字段的个数(即当前行被分割成了几列)
NR(Number of Record):行号,当前处理的文本行的行号。
FNR:各文件分别计数的行号
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数
自定义变量的方法
方法一:-v varname=value ,变量名区分字符大小写。
方法二:在program中直接定义。
awk脚本
关于awk脚本,我们需要注意两个关键词BEGIN和END。
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
$ cat score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
我们的awk脚本如下:
$ cat cal.awk
#!/bin/awk -f
#运行前
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#运行中
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#运行后
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}
我们来看一下执行结果:
$ awk -f cal.awk score.txt
NAME NO. MATH ENGLISH COMPUTER TOTAL
---------------------------------------------
Marry 2143 78 84 77 239
Jack 2321 66 78 45 189
Tom 2122 48 77 71 196
Mike 2537 87 97 95 279
Bob 2415 40 57 62 159
---------------------------------------------
TOTAL: 319 393 350
AVERAGE: 63.80 78.60 70.00
关于awk sed和grep三者的比较
awk、sed、grep更适合的方向:
- grep 更适合单纯的查找或匹配文本
- sed 更适合编辑匹配到的文本
- awk 更适合格式化文本,对文本进行较复杂格式处理
可参考资料:
1.Linux awk 命令
2.Linux之awk详解