pytorch SSD代码解读(2)
一、预测过程
letterbox_image为了防止失帧,不进行简单的resize,先放大图片,进行三次样条插值,创建一个300*300的灰色图片,把放大后的图片粘贴到灰色图片上,相当于在边缘加上灰条。
def letterbox_image(image, size):
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale) # nw,nh一定有一个是300
nh = int(ih*scale)
image = image.resize((nw,nh), Image.BICUBIC) # 三次样条插值
new_image = Image.new('RGB', size, (128,128,128)) # 创建一个300*300的灰色图
new_image.paste(image, ((w-nw)//2, (h-nh)//2)) # 把插值后的图片粘贴到灰色图中,指定左上角坐标
return new_image
将预测的的框变成真实图片的框
def encode(matched, priors, variances):
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
g_cxcy /= (variances[0] * priors[:, 2:])
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
return torch.cat([g_cxcy, g_wh], 1)
计算所有的先验框和真实框的重合程度
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
# 计算所有的先验框和真实框的重合程度
# [truth_box, num_prior]
overlaps = jaccard(
truths,
point_form(priors)
)
# 所有真实框和先验框的最好重合程度
# [truth_box,1]
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
# 所有先验框和真实框的最好重合程度
# [1,prior]
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
# 找到与真实框重合程度最好的先验框,用于保证每个真实框都要有对应的一个先验框
best_truth_overlap.index_fill_(0, best_prior_idx, 2)
# 对best_truth_idx内容进行设置
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
# 找到每个先验框重合程度最好的真实框
matches = truths[best_truth_idx] # Shape: [num_priors,4]
conf = labels[best_truth_idx] + 1 # Shape: [num_priors]
# 如果重合程度小于threhold则认为是背景
conf[best_truth_overlap < threshold] = 0 # label as background
loc = encode(matches, priors, variances)
loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
conf_t[idx] = conf # [num_priors] top class label for each prior
检测图片
def detect_image(self, image):
image_shape = np.array(np.shape(image)[0:2])
# letterbox_image为了防止失帧,不是简单resize,而是在边缘加上灰条
crop_img = np.array(letterbox_image(image, (self.model_image_size[0],self.model_image_size[1])))
photo = np.array(crop_img,dtype = np.float64)
# 图片预处理,归一化
with torch.no_grad():
# 从每个图像通道中减去给定的均值,torch中是BGR,transpose转换一下
photo = torch.from_numpy(np.expand_dims(np.transpose(crop_img-MEANS,(2,0,1)),0)).type(torch.FloatTensor)
if self.cuda:
photo = photo.cuda()
preds = self.net(photo) # 把photo传入net中得到预测结果
top_conf = []
top_label = []
top_bboxes = []
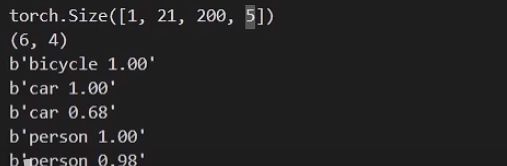
for i in range(preds.size(1)): # pred.size = (1,21,200,5),遍历21个类
j = 0
while preds[0, i, j, 0] >= self.confidence: # 判断先验框是否大于置信度阈值
score = preds[0, i, j, 0] # 得分是[置信度,左上角x,左上角y,右下角x,右下角y]中的置信度
label_name = self.class_names[i-1]
pt = (preds[0, i, j, 1:]).detach().numpy()
coords = [pt[0], pt[1], pt[2], pt[3]] # [左上角x,左上角y,右下角x,右下角y]
top_conf.append(score)
top_label.append(label_name)
top_bboxes.append(coords)
j = j + 1
# 将预测结果进行解码
if len(top_conf)<=0: # 是否检测到了物体
return image
top_conf = np.array(top_conf)
top_label = np.array(top_label)
top_bboxes = np.array(top_bboxes)
# top_xmin, top_ymin, top_xmax, top_ymax的size都为(200,1)
top_xmin, top_ymin, top_xmax, top_ymax = np.expand_dims(top_bboxes[:,0],-1),np.expand_dims(top_bboxes[:,1],-1),np.expand_dims(top_bboxes[:,2],-1),np.expand_dims(top_bboxes[:,3],-1)
# 去掉灰条
boxes = ssd_correct_boxes(top_ymin,top_xmin,top_ymax,top_xmax,np.array([self.model_image_size[0],self.model_image_size[1]]),image_shape)
font = ImageFont.truetype(font='model_data/simhei.ttf',size=np.floor(3e-2 * np.shape(image)[1] + 0.5).astype('int32'))
thickness = (np.shape(image)[0] + np.shape(image)[1]) // self.model_image_size[0]
for i, c in enumerate(top_label):
predicted_class = c
score = top_conf[i]
top, left, bottom, right = boxes[i]
top = top - 5
left = left - 5
bottom = bottom + 5
right = right + 5
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(np.shape(image)[0], np.floor(bottom + 0.5).astype('int32'))
right = min(np.shape(image)[1], np.floor(right + 0.5).astype('int32'))
# 画框框
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
print(label)
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[self.class_names.index(predicted_class)])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[self.class_names.index(predicted_class)])
draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font)
del draw
return image
利用训练好的模型进行预测
class SSD(object):
_defaults = {
"model_path": 'model_data/ssd_weights.pth',
"classes_path": 'model_data/voc_classes.txt',
"model_image_size" : (300, 300, 3),
"confidence": 0.5,
"cuda": True,
}
我们修改SSD下的defaults,把model_path改成自己训练好的路径,把classes_path改成自己的类别,再运行predict.py


二、训练过程

数据增强
和yolo v3类似
def get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=1.5, val=1.5):
'''r实时数据增强的随机预处理'''
line = annotation_line.split()
image = Image.open(line[0])
iw, ih = image.size
h, w = input_shape
box = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
# resize image
new_ar = w/h * rand(1-jitter,1+jitter)/rand(1-jitter,1+jitter) # 随机生成宽高比
scale = rand(.5, 1.5) # 随机生成缩放比例
# 生成新的宽高比
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
#随机水平位移
dx = int(rand(0, w-nw))
dy = int(rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image = new_image
# 随机翻转
flip = rand()<.5
if flip:
image = image.transpose(Image.FLIP_LEFT_RIGHT)
# 颜色抖动 RGB->HVS->RGB
hue = rand(-hue, hue)
sat = rand(1, sat) if rand()<.5 else 1/rand(1, sat)
val = rand(1, val) if rand()<.5 else 1/rand(1, val)
x = cv2.cvtColor(np.array(image,np.float32)/255, cv2.COLOR_RGB2HSV)
x[..., 0] += hue*360
x[..., 0][x[..., 0]>1] -= 1
x[..., 0][x[..., 0]<0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x[:,:, 0]>360, 0] = 360
x[:, :, 1:][x[:, :, 1:]>1] = 1
x[x<0] = 0
image_data = cv2.cvtColor(x, cv2.COLOR_HSV2RGB)*255
# correct boxes
box_data = np.zeros((len(box),5))
if len(box)>0:
np.random.shuffle(box)
# 缩放
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
# 左右翻转
if flip: box[:, [0,2]] = w - box[:, [2,0]]
# 定义边界
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
# 计算新的长宽
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)] # 丢弃无效框
box_data = np.zeros((len(box),5))
box_data[:len(box)] = box
if len(box) == 0:
return image_data, []
if (box_data[:,:4]>0).any():
return image_data, box_data
else:
return image_data, []
生成数据增强后的图片和标签
def generate(self, train=True):
while True:
shuffle(self.train_lines)
lines = self.train_lines
inputs = []
targets = []
for annotation_line in lines:
img,y=self.get_random_data(annotation_line,self.image_size[0:2]) # 进行数据增强
if len(y)==0:
continue
boxes = np.array(y[:,:4],dtype=np.float32)
boxes[:,0] = boxes[:,0]/self.image_size[1] # 把图片的位置转化成小数的形式
boxes[:,1] = boxes[:,1]/self.image_size[0]
boxes[:,2] = boxes[:,2]/self.image_size[1]
boxes[:,3] = boxes[:,3]/self.image_size[0]
boxes = np.maximum(np.minimum(boxes,1),0)
if ((boxes[:,3]-boxes[:,1])<=0).any() and ((boxes[:,2]-boxes[:,0])<=0).any(): # 如果右下角在左上角的左边,就过滤掉
continue
y = np.concatenate([boxes,y[:,-1:]],axis=-1)
inputs.append(np.transpose(img-MEANS,(2,0,1))) # 把图片通道变换一下,变成GBR
targets.append(y)
if len(targets) == self.batch_size:
tmp_inp = np.array(inputs) # 图片
tmp_targets = np.array(targets) # 标签
inputs = []
targets = []
yield tmp_inp, tmp_targets
损失函数计算
def forward(self, predictions, targets):
# 回归信息,置信度,先验框
loc_data, conf_data, priors = predictions
# 计算出batch_size
num = loc_data.size(0)
# 取出所有的先验框
priors = priors[:loc_data.size(1), :]
# 先验框的数量
num_priors = (priors.size(0))
# 创建一个tensor进行处理
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
priors = priors.cuda()
for idx in range(num):
# 获得框
truths = targets[idx][:, :-1]
# 获得标签
labels = targets[idx][:, -1]
# 获得先验框
defaults = priors
# 找到标签对应的先验框
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
# 转化成Variable
loc_t = loc_t, requires_grad=False
conf_t = conf_t, requires_grad=False
# 所有conf_t>0的地方,代表内部包含物体
pos = conf_t > 0
# 求和得到每一个图片内部有多少正样本
num_pos = pos.sum(dim=1, keepdim=True)
# 计算回归loss
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
# 转化形式
batch_conf = conf_data.view(-1, self.num_classes)
# 你可以把softmax函数看成一种接受任何数字并转换为概率分布的非线性方法
# 获得每个框预测到真实框的类的概率
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
loss_c = loss_c.view(num, -1)
loss_c[pos] = 0
# 获得每一张图新的softmax的结果
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
# 计算每一张图的正样本数量
num_pos = pos.long().sum(1, keepdim=True)
# 限制负样本数量
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# 计算正样本的loss和负样本的loss
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
N = num_pos.data.sum()
loss_l /= N
loss_c /= N
return loss_l, loss_c