[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读
今天开始要正式做Action Localization方向的研究了,之前也是磕磕绊绊地看了几篇论文也看不进去,还是需要写博客督促自己啊。
第一次做弱监督,理解上真是太难了。首先数据集以THUMOS为例,官网上给出的训练集是UCF101但事实上动作定位的训练集是THUMOS的验证集,二十个类别视频,这也就是为什么开源代码直接用I3D处理后的features一共才20类,而不是101类。每个视频里面包含一个动作,动作帧和非动作帧交叉,弱监督学习只有视频级标签,没有帧级标签,也就是说动作序列的起始帧和终止帧没有标注。弱监督动作定位有两个任务,一个是分类,需要知道未剪辑的视频中动作序列的类别,和回归任务,需要知道动作序列的起始帧和终止帧,好比时序维度的目标检测,但常见的目标检测算法可不是弱监督,难在这里。
数据集:THUMOS 14
20个类的验证子集来训练模型,这个子集由200个未修剪的视频组成,没有时间注解。使用带有时间注释的20个类测试子集中的212个视频来评估算法。这个数据集具有挑战性,因为有些视频相对较长(长达26分钟),并且包含多个动作实例。动作的长度变化很大,从不到一秒到几分钟不等。
数据集:ActivityNet
ActivityNet1.3,它最初包含10,024个用于培训的视频、4,926个用于验证的视频和5,044个用于testing1的视频,其中包含200个活动类。这个数据集包含大量的自然视频,这些视频按照语义分类涉及各种人类活动。
目前算法常见思路,一种是注意力机制,另一种就是常见的卷积网络+全连接,还有一种就是图卷积。
ECCV2020:
Two-Stream Consensus Network for Weakly-Supervised Temporal Action Localization
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第1张图片](http://img.e-com-net.com/image/info8/412ca55eb7954f18b96c02b411d740ab.jpg)
Challenge:1,由于场景帧和动作帧相似,而容易误识别,影响定位效果;2,过去方法的动作proposal的生成是通过对激活序列设置阈值,比如大于0.5认为是动作序列。这个阈值依赖于实验和经验,阈值过高会使proposal不完整,过低会把非动作帧包含在内。
Contribution:迭代更新帧级伪标签监督训练;注意力规范化损失使注意力值趋向于0和1,提高动作proposal的质量。
目前大部分弱监督动作定位算法都利用预训练的I3D提取特征,有时间再看看I3D,所以开源代码网络的输入直接是I3D处理后的RGB特征1024维和Flow特征1024维,上图则体现了RGB与Flow在该任务上的各自优势。由于二者融合后的效果更佳,所以涉及到early fusion和late fusion,本文是late fusion,下面的AAAI2020是early fusion。
非动作帧被预测为动作帧成为False positive action proposals,本文为降低误识别,需要引入帧级的标签,由于弱监督不提供帧级标注,所以作者引入帧级伪标签。算法框架如下图,
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第2张图片](http://img.e-com-net.com/image/info8/1a05d27c9212423cbf15021c3c92e914.jpg)
网络可分为三部分(1)Feature Extraction:就是预训练的I3D。(2)Two-Stream Base Models。视频v可以视为由T个不重叠的片段组成,因此RGB features和Flow features用![]() 表示,其经过一次卷积后得到
表示,其经过一次卷积后得到![]() ,接下来是注意力层Ai,其表示相对应的帧是前景还是背景,大部分算法都使用了注意力层,注意力值属于[0,1],注意力层就是一个全连接层。X和A乘积之后得到前景特征Xfg用于分类任务。此外还有一个Attention Normalization Loss
,接下来是注意力层Ai,其表示相对应的帧是前景还是背景,大部分算法都使用了注意力层,注意力值属于[0,1],注意力层就是一个全连接层。X和A乘积之后得到前景特征Xfg用于分类任务。此外还有一个Attention Normalization Loss
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第3张图片](http://img.e-com-net.com/image/info8/6771e484ddee48b198a64497a993c9a3.jpg)
CVPR2018:
Weakly Supervised Action Localization by Sparse Temporal Pooling Network
Contribution: 新的网络结构和Sparsity Loss。
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第4张图片](http://img.e-com-net.com/image/info8/e924508f4ed142e69b2a4b83c8df9553.jpg)
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第5张图片](http://img.e-com-net.com/image/info8/ee8ed6986f4e490098b70c688aee4843.jpg)
将输入视频分成T个片段,每个片段可以提取1024维度的特征向量,可以是RGB也可以是optical flow。Attention Module由两个全连接层和Sigmoid组成,既参与分类任务,额外的每个片段的注意力组成AttentionWeights,进行Sparsity Loss。
T个片段的1024维特征及其注意力权重,合成一个特征向量用于分类;注意力权值的Sparsity Loss就是对lambda计算L1范数,sigmoid和L1范数能够使lambda接近0或1(存疑)
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第6张图片](http://img.e-com-net.com/image/info8/4c9a484a6a4c4d919fa288fe0f8d364b.jpg)
w为最后一层全连接层的权重与对应的RGB特征或flow特征求得,下图表明注意力有益于动作定位,所以本文采用注意力加权的TCAM,结合阈值,生成proposal完成定位预测。

![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第7张图片](http://img.e-com-net.com/image/info8/358c02fc7bb34177b3d85217247bcc33.jpg)
AAAI 2020:
Background Suppression Network for Weakly-supervised Temporal Action Localization
论文链接:https://arxiv.org/pdf/1911.09963
代码链接:https://github.com/Pilhyeon/BaSNet-pytorch
Contribution:引入背景类,抑制非动作帧的激活。
以前的方法是通过聚合帧级的类分数来生成视频级的预测和学习视频级的动作标签。为了准确预测视频级别的标签,背景帧有时会被错误地分类为动作类。本文设计了基于非对称训练策略的双分支权值共享背景抑制网络(BaSNet)。这使BASNet能够抑制来自背景帧的激活,从而提高Localization的性能。
其实通过代码来分析这篇论文也不难。文章说引入背景类,实际上我们在THUMOS数据集上训练时,已经是20+1(背景)这样训练了。
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第8张图片](http://img.e-com-net.com/image/info8/c282f3d7834742bc96b7ebca48dc74af.jpg)
early fusion,构成T*2048维的特征向量,Base branch 卷积后得到T*21,并计算分数;Suppression Branch则先将T*2048转换成T*1,称之为前景权重,实际上和注意力一样,foreground weights与T*2048相乘得到T*2048,再计算分数。整体流程就是这样。
CVPR2019
Completeness Modeling and Context Separation for Weakly Supervised Temporal Action Localization
Challenges: 动作完整性建模和动作-上下文分离
动作实际上是由多个子运动组成的,比如投篮包括人抛球的动作和球在空中的运动;打台球视频中的台球桌容易被认为是动作帧导致动作与上下文混淆。
作者提出的多分支网络,每个分支用来定位动作序列的某一部分,如下图:
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第9张图片](http://img.e-com-net.com/image/info8/de40db0ecd054b56b5a55bbddb40d722.jpg)
多分支网络包含K+1个分支,K个分支用来生成类激活序列CAS,为了让每个分支学习到动作的不同部分,第i个CAS和第i+1个CAS计算余弦相似度,最小化相似度意味着让CAS负责不同的片段。(对于动作完整性建模,我们希望来自多个分支的用例彼此不同。然而,如果没有约束,分支可以懒洋洋地集中在单个相同的动作部分。为避免分支结果相同的退化情况,对以下情况施加基于余弦相似度的多样性损失)Diversity Loss如下:
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第10张图片](http://img.e-com-net.com/image/info8/4750a62160b64a5987946cccf146d8a1.jpg)
最后对K个CAS求平均,即为该完整视频的CAS,通过设置阈值完成Action Localization。此外增加一个正则项Lnorm,希望各分支的范数和均值范数更接近(我觉得和上面的损失有冲突)。
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第11张图片](http://img.e-com-net.com/image/info8/bbc8429041154f12b01ccd5ca74f65c7.jpg)
另一个分支就是注意力分支,注意力值与平均CAS完成视频级的预测。
Hard Negative Video Generation:弱监督模型倾向于混淆真实行为与其周围环境,即hard negative,特别是当环境出现在该类别的大多数视频中。作者认为上下文应该是保持静态的,所以作者利用光流判断视频帧是动作帧还是上下文帧,光流强度小于一个阈值则把这个视频中的这些帧提取出来构成伪视频,并标记为背景类,添加到训练集中。
WACV2020:
Action Graphs: Weakly-supervised Action Localization with Graph Convolution Networks
作者说他是第一个在弱监督动作定位任务上应用图卷积的。
目前方法没有明确地利用视频时刻之间的关系。
Motivation:利用不同动作类别的前景片段的区别能够更准确地分类视频;利用相同前景片段之间的联系决定动作的范围;推断不同动作片段的相似性来指导背景;
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第12张图片](http://img.e-com-net.com/image/info8/854c1b291c2849c09404c4481af343db.jpg)
该算法将视频中的每个片段作为图的节点,节点之间的边由节点的相似性加权。
特征提取部分,仍然采用I3D,得到RGB和光流特征,各1024维,合在一起就是L*2048的特征向量,L是输入视频片段个数(每个视频片段是25FPS的视频16帧,或者0.64秒)
训练期间,每个时间片段是一个人图节点,特征空间中相关的时间片段越来越近,不相关的时间片段越来越分离。 图卷积可以鼓励更好的定位,因为网络被迫在它相似的其他时间段的上下文中检查和预测每个时间段的类别 。
三个损失函数:1,多实例损失函数,是动作定位常见的分类损失函数,就是对每个片段都进行交叉熵的计算。
2,L1稀疏损失,计算图边的权重L1范数,目的是丢弃权值较低的节点,它们更可能是背景。
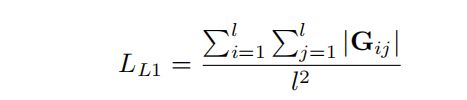
3,Co-Activity Similarity Loss: 先计算相同类别 i 的两个视频 j 和 k 的前景特征 f 和 背景特征 b ,再计算特征向量之间的余弦距离。该损失函数的目的是让同一类别视频的前景特征之间的距离小于前景与背景之间的距离。
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第13张图片](http://img.e-com-net.com/image/info8/916c0a30b66d4a6f9ab1941493e86987.jpg)
Final Loss:
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第14张图片](http://img.e-com-net.com/image/info8/f56a08d1c09b450da6426ad13ce42170.jpg)
WACV2020
Weakly Supervised Temporal Action Localization Using Deep Metric Learning
Contribution:提出了一个新的分类模块和一个度量学习模块。
度量学习的目的是学习一个良好的距离度量,使同一类型数据之间的距离减小,不同类型数据之间的距离扩大。 在人脸能识别领域有广泛的研究。
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第15张图片](http://img.e-com-net.com/image/info8/ac617033b99d4b969d33578d6264526f.jpg)
输入视频一直到Feature Extraction是固定不变的,可操作的部分就是特征提取之后。Feature Embedding 由全连接relu和drop out组成,目的是把原始特征转换成特定任务特征,维度什么的都不变。
Classification Module:
该分类模块的特别之处首先是考虑了视频长度不同得到的片段个数不同,所以作者就将视频分块,每块包含相等数量的连续片段。最终每块的分类分数决定整个视频的类别。其次,作者考虑到视频类别不平衡问题,损失函数项除以该类别的样本数解决样本失衡。
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第16张图片](http://img.e-com-net.com/image/info8/d2e919a9c4bc41698c765dd81a6a8e37.jpg)
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第17张图片](http://img.e-com-net.com/image/info8/ffd7dcdf1dfc46698b16fd8b938a82b8.jpg)
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第18张图片](http://img.e-com-net.com/image/info8/6d8d60dcbbd04317893e11264c721fa2.jpg)
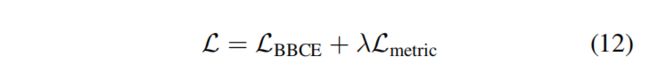
Coming Soon。。。。。。。
![[综述]弱监督动作定位Weakly Supervised Temporal Action Localization 论文阅读_第19张图片](http://img.e-com-net.com/image/info8/f4750a8db8a94e2d9fc4f04395d0fc71.jpg)