Kali Linux下社工密码字典生成工具Cupp和Cewl教程
安装:apt-get install cupp


查看命令:cupp
参数说明

-v 查看cupp版本号
-h 查看参数列表
-l 从github仓库下载字典
-i 使用交互式的提问创建用户密码字典,cupp的主要功能,本文主要演示此参数
-w 在已存在的字典上进行扩展
以freebuf为例生成字典
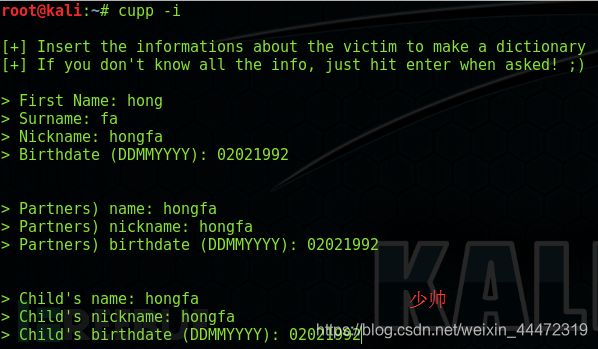
执行cupp -i
Kali Linux下社工密码字典生成工具Cupp和Cewl教程
然后和工具开始交互,会让你输入被攻击目标的姓、名、外号、生日、父母的名字、外号、生日、子女的名字、外号、生日等等一系列的信息。如果你有这些信息,直接输入,如果没有直接回车进行下一步。

然后是宠物、公司等名称,需要不需要加关键字当前缀后缀等等,如果不知道或者不想加,直接回车跳过。
最后在命令执行的目录里生成字典文件。
注意:输入生日信息的时候是按照日、月、年的顺序,如11021990就是1990年2月11日
最后查看生成的字典文件

cewl教程:
cewl是通过爬取网站的时候,根据爬取内容的关键字生成一份字典,通过这种方式生成的字典可以作为cupp生成字典的补充。如果常见的字典都爆破了还没拿下目标,那你只能挂个十几G几十G的字典去跑了,具体是跑到几百年或者几千年以后,这个要看人品哈!哈哈@!
cewl是kali自带的脚本工具,我崇尚日常使用都使用自带的工具,即使虚拟机坏了,再找一个虚拟机立马就能干活而不需要配置环境。
接下来看图:输入cewl –help会在屏幕打印如下,下面我给大家翻译一下,译文用Python的注释方式
cewl [OPTION] … URL
–help, -h: show help #显示帮助
--keep, -k: keep the downloaded file #保存下载的文件
--depth x, -d x: depth to spider to, default 2 #网站爬取深度,默认为2,建议不要太大
--min_word_length, -m: minimum word length, default 3 #字典的最小单词长度,如果小于此不收入字典
--offsite, -o: let the spider visit other sites #让爬虫爬取其他站点,针对外链的
--write, -w file: write the output to the file #爬取的内容输出到文件
--ua, -u user-agent: user agent to send #使用useragent,这个可以突破简单防御
--no-words, -n: don't output the wordlist #不要输出字典
--meta, -a include meta data #包含网页中的meta数据
--meta_file file: output file for meta data #为meta数据输出个文件
--email, -e include email addresses #包含email地址
--email_file file: output file for email addresses #输出email地址
--meta-temp-dir directory: the temporary directory used by exiftool when parsing files, default /tmp
--count, -c: show the count for each word found #展示发现的每个单词的数量
Authentication
--auth_type: digest or basic
--auth_user: authentication username
--auth_pass: authentication password
Proxy Support
--proxy_host: proxy host
--proxy_port: proxy port, default 8080
--proxy_username: username for proxy, if required
--proxy_password: password for proxy, if required
Headers
--header, -H: in format name:value - can pass multiple
--verbose, -v: verbose
URL: The site to spider.
下面用firet少帅力少帅力est网站做演示,演示其他网站我怕被请喝茶

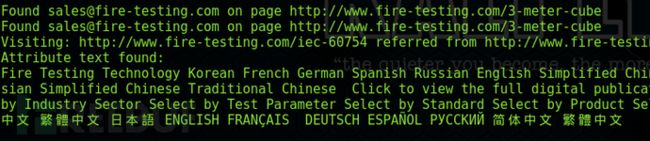
如果显示进度就用-v参数,这里演示我只爬取深度设为1
完成以后查看字典如下:

转载自:https://www.freebuf.com/sectool/144740.html