有基础(Pytorch/TensorFlow基础)mxnet+gluon快速入门
import numpy as np
import mxnet as mx
import logging
logging.getLogger().setLevel(logging.DEBUG) # logging to stdout
mxnet基本数据结构
ndarray
ndarray是mxnet中最基本的数据结构,ndarray和mxnet的关系与tensor和pytorch的关系类似。该数据结构可以看成numpy的一种变体,基本上numpy的操作ndarray都可以实现。与ndarray相关的部分是mxnet.nd.,关于ndarray操作的API可查看官方API文档
ndarray操作
a = mx.nd.random.normal(shape=(4,3))
b = mx.nd.ones((4,3))
print(a)
print(b)
print(a + b)
[[ 0.23107234 0.30030754 -0.32433936]
[ 1.04932904 0.7368623 -0.0097888 ]
[ 0.46656415 1.72023427 0.87809837]
[-1.07333779 -0.86925656 -0.26717702]]
[[ 1. 1. 1.]
[ 1. 1. 1.]
[ 1. 1. 1.]
[ 1. 1. 1.]]
[[ 1.23107231 1.30030751 0.67566061]
[ 2.04932904 1.7368623 0.99021119]
[ 1.46656418 2.72023439 1.87809837]
[-0.07333779 0.13074344 0.73282301]]
ndarray与numpy相互转换
-
mxnet.nd.array()传入一个numpy矩阵可以将其转换为ndarray - 使用
ndarray.asnumpy()方法将ndarray转为numpy矩阵
a = np.random.randn(2,3)
print(a,type(a))
b = mx.nd.array(a)
print(b,type(b))
b = b.asnumpy()
print(b,type(b))
[[ 0.85512384 -0.58311797 -1.41627038]
[-0.56862628 1.15431958 0.13168715]]
[[ 0.85512382 -0.58311796 -1.41627038]
[-0.56862628 1.15431952 0.13168715]]
[[ 0.85512382 -0.58311796 -1.41627038]
[-0.56862628 1.15431952 0.13168715]]
symbol
symbol是另一个重要的概念,可以理解为符号,就像我们平时使用的代数符号x,y,z一样。一个简单的类比,一个函数$f(x) = x^{2}$,符号x就是symbol,而具体x的值就是ndarray,关于symbol的是mxnet.sym.,具体可参照官方API文档
基本操作
- 使用
mxnet.sym.Variable()传入名称可建立一个symbol - 使用
mxnet.viz.plot_network(symbol=)传入symbol可以绘制运算图
a = mx.sym.Variable('a')
b = mx.sym.Variable('b')
c = mx.sym.add_n(a,b,name="c")
mx.viz.plot_network(symbol=c)
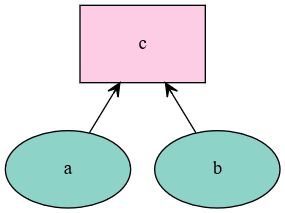
带入ndarray
使用mxnet.sym.bind()方法可以获得一个带入操作数的对象,再使用forward()方法可运算出数值
x = c.bind(ctx=mx.cpu(),args={"a": mx.nd.ones(5),"b":mx.nd.ones(5)})
result = x.forward()
print(result)
[
[ 2. 2. 2. 2. 2.]
]
mxnet的数据载入
深度学习中数据的载入方式非常重要,mxnet提供了mxnet.io.的一系列dataiter用于处理数据载入,详细可参照官方API文档。同时,动态图接口gluon也提供了mxnet.gluon.data.系列的dataiter用于数据载入,详细可参照官方API文档
mxnet.io数据载入
mxnet.io的数据载入核心是mxnet.io.DataIter类及其派生类,例如ndarray的iter:NDArrayIter
- 参数
data=:传入一个(名称-数据)的数据dict - 参数
label=:传入一个(名称-标签)的标签dict - 参数
batch_size=:传入batch大小
dataset = mx.io.NDArrayIter(data={'data':mx.nd.ones((10,5))},label={'label':mx.nd.arange(10)},batch_size=5)
for i in dataset:
print(i)
print(i.data,type(i.data[0]))
print(i.label,type(i.label[0]))
DataBatch: data shapes: [(5, 5)] label shapes: [(5,)]
[
[[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]]
]
[
[ 0. 1. 2. 3. 4.]
]
DataBatch: data shapes: [(5, 5)] label shapes: [(5,)]
[
[[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]]
]
[
[ 5. 6. 7. 8. 9.]
]
gluon.data数据载入
gluon的数据API几乎与pytorch相同,均是Dataset+DataLoader的方式:
- Dataset:存储数据,使用时需要继承该基类并重载
__len__(self)和__getitem__(self,idx)方法 - DataLoader:将Dataset变成能产生batch的可迭代对象
dataset = mx.gluon.data.ArrayDataset(mx.nd.ones((10,5)),mx.nd.arange(10))
loader = mx.gluon.data.DataLoader(dataset,batch_size=5)
for i,data in enumerate(loader):
print(i)
print(data)
0
[
[[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]]
,
[ 0. 1. 2. 3. 4.]
]
1
[
[[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1.]]
,
[ 5. 6. 7. 8. 9.]
]
class TestSet(mx.gluon.data.Dataset):
def __init__(self):
self.x = mx.nd.zeros((10,5))
self.y = mx.nd.arange(10)
def __getitem__(self,i):
return self.x[i],self.y[i]
def __len__(self):
return 10
for i,data in enumerate(mx.gluon.data.DataLoader(TestSet(),batch_size=5)):
print(data)
[
[[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]]
,
[[ 0.]
[ 1.]
[ 2.]
[ 3.]
[ 4.]]
]
[
[[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]]
,
[[ 5.]
[ 6.]
[ 7.]
[ 8.]
[ 9.]]
]
网络搭建
mxnet网络搭建
mxnet网络搭建类似于TensorFlow,使用symbol搭建出网络,再用一个module封装
data = mx.sym.Variable('data')
# layer1
conv1 = mx.sym.Convolution(data=data, kernel=(5,5), num_filter=32,name="conv1")
relu1 = mx.sym.Activation(data=conv1,act_type="relu",name="relu1")
pool1 = mx.sym.Pooling(data=relu1,pool_type="max",kernel=(2,2),stride=(2,2),name="pool1")
# layer2
conv2 = mx.sym.Convolution(data=pool1, kernel=(3,3), num_filter=64,name="conv2")
relu2 = mx.sym.Activation(data=conv2,act_type="relu",name="relu2")
pool2 = mx.sym.Pooling(data=relu2,pool_type="max",kernel=(2,2),stride=(2,2),name="pool2")
# layer3
fc1 = mx.symbol.FullyConnected(data=mx.sym.flatten(pool2), num_hidden=256,name="fc1")
relu3 = mx.sym.Activation(data=fc1, act_type="relu",name="relu3")
# layer4
fc2 = mx.symbol.FullyConnected(data=relu3, num_hidden=10,name="fc2")
out = mx.sym.SoftmaxOutput(data=fc2, label=mx.sym.Variable("label"),name='softmax')
mxnet_model = mx.mod.Module(symbol=out,label_names=["label"],context=mx.gpu())
mx.viz.plot_network(symbol=out)

Gluon模型搭建
Gluon模型搭建与pytorch类似,通过继承一个mx.gluon.Block或使用mx.gluon.nn.Sequential()来实现
一般搭建方法
class MLP(mx.gluon.Block):
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
with self.name_scope():
self.dense0 = mx.gluon.nn.Dense(256)
self.dense1 = mx.gluon.nn.Dense(64)
self.dense2 = mx.gluon.nn.Dense(10)
def forward(self, x):
x = mx.nd.relu(self.dense0(x))
x = mx.nd.relu(self.dense1(x))
x = self.dense2(x)
return x
gluon_model = MLP()
print(gluon_model)
# mx.viz.plot_network(symbol=gluon_model)
MLP(
(dense0): Dense(None -> 256, linear)
(dense2): Dense(None -> 10, linear)
(dense1): Dense(None -> 64, linear)
)
快速搭建方法
gluon_model2 = mx.gluon.nn.Sequential()
with gluon_model2.name_scope():
gluon_model2.add(mx.gluon.nn.Dense(256,activation="relu"))
gluon_model2.add(mx.gluon.nn.Dense(64,activation="relu"))
gluon_model2.add(mx.gluon.nn.Dense(10,activation="relu"))
print(gluon_model2)
Sequential(
(0): Dense(None -> 256, Activation(relu))
(1): Dense(None -> 64, Activation(relu))
(2): Dense(None -> 10, Activation(relu))
)
模型训练
mxnet模型训练
mxnet提供了两套不同层次上的训练封装,一般使用最方便的顶层封装fit()即可
mnist = mx.test_utils.get_mnist()
train_iter = mx.io.NDArrayIter(mnist['train_data'], mnist['train_label'], batch_size=100, data_name='data',label_name='label',shuffle=True)
val_iter = mx.io.NDArrayIter(mnist['test_data'], mnist['test_label'], batch_size=100,data_name='data',label_name='label')
INFO:root:train-labels-idx1-ubyte.gz exists, skipping download
INFO:root:train-images-idx3-ubyte.gz exists, skipping download
INFO:root:t10k-labels-idx1-ubyte.gz exists, skipping download
INFO:root:t10k-images-idx3-ubyte.gz exists, skipping download
mxnet_model.fit(train_iter, # train data
eval_data=val_iter, # validation data
optimizer='adam', # use SGD to train
optimizer_params={'learning_rate':0.01}, # use fixed learning rate
eval_metric='acc', # report accuracy during training
batch_end_callback = mx.callback.Speedometer(100, 200), # output progress for each 100 data batches
num_epoch=3) # train for at most 3 dataset passes
INFO:root:Epoch[0] Batch [200] Speed: 5239.83 samples/sec accuracy=0.890348
INFO:root:Epoch[0] Batch [400] Speed: 5135.49 samples/sec accuracy=0.971450
INFO:root:Epoch[0] Train-accuracy=0.977236
INFO:root:Epoch[0] Time cost=11.520
INFO:root:Epoch[0] Validation-accuracy=0.980300
INFO:root:Epoch[1] Batch [200] Speed: 5336.36 samples/sec accuracy=0.979453
INFO:root:Epoch[1] Batch [400] Speed: 5312.22 samples/sec accuracy=0.982550
INFO:root:Epoch[1] Train-accuracy=0.984724
INFO:root:Epoch[1] Time cost=11.704
INFO:root:Epoch[1] Validation-accuracy=0.980500
INFO:root:Epoch[2] Batch [200] Speed: 5522.89 samples/sec accuracy=0.982388
INFO:root:Epoch[2] Batch [400] Speed: 5562.08 samples/sec accuracy=0.984550
INFO:root:Epoch[2] Train-accuracy=0.985075
INFO:root:Epoch[2] Time cost=10.860
INFO:root:Epoch[2] Validation-accuracy=0.978000
gluon模型训练
gluon的模型训练包括:
- 初始化模型参数
- 定义代价函数和优化器
- 计算前向传播
- 反向传播计算梯度
- 调用优化器优化模型
def transform(data, label):
return data.astype(np.float32)/255, label.astype(np.float32)
gluon_train_data = mx.gluon.data.DataLoader(mx.gluon.data.vision.MNIST(train=True, transform=transform),
100, shuffle=True)
gluon_test_data = mx.gluon.data.DataLoader(mx.gluon.data.vision.MNIST(train=False, transform=transform),
100, shuffle=False)
gluon_model.collect_params().initialize(mx.init.Normal(sigma=.1), ctx=mx.gpu())
softmax_cross_entropy = mx.gluon.loss.SoftmaxCrossEntropyLoss()
trainer = mx.gluon.Trainer(gluon_model.collect_params(), 'sgd', {'learning_rate': .1})
for _ in range(2):
for i,(data,label) in enumerate(gluon_train_data):
data = data.as_in_context(mx.gpu()).reshape((-1, 784))
label = label.as_in_context(mx.gpu())
with mx.autograd.record():
outputs = gluon_model(data)
loss = softmax_cross_entropy(outputs,label)
loss.backward()
trainer.step(data.shape[0])
if i % 100 == 1:
print(loss.mean().asnumpy()[0])
2.3196
0.280345
0.268811
0.419094
0.260873
0.252575
0.162117
0.247361
0.169366
0.184899
0.0986493
0.251358
准确率计算
mxnet模型准确率计算
mxnet的模型提供score()方法用于计算指标,用法与sklearn类似,除了用该API,也可以使用ndarray搭建评估函数
acc = mx.metric.Accuracy()
mxnet_model.score(val_iter,acc)
print(acc)
EvalMetric: {'accuracy': 0.97799999999999998}
gluon模型准确率计算
gluon官方教程中没有使用提供好的准确率计算方法,需要使用mxnet函数的metric.Accuracy()搭建
def evaluate_accuracy():
acc = mx.metric.Accuracy()
for i, (data, label) in enumerate(gluon_test_data):
data = data.as_in_context(mx.gpu()).reshape((-1, 784))
label = label.as_in_context(mx.gpu())
output = gluon_model(data)
predictions = mx.nd.argmax(output, axis=1)
acc.update(preds=predictions, labels=label)
return acc.get()[1]
evaluate_accuracy()
0.95079999999999998
模型保存与载入
mxnet
mxnet保存模型
- mxnet在fit中使用
mx.callback.module_checkpoint()作为fit参数epoch_end_callback可以在训练中保存模型 - 训练完成后可以使用
module.save_checkpoint()保存模型
mxnet_model.save_checkpoint("mxnet_",3)
INFO:root:Saved checkpoint to "mxnet_-0003.params"
mxnet载入模型
使用mx.model.load_checkpoint()和mx.model.set_params载入模型
# mxnet_model2 = mx.mod.Module(symbol=out,label_names=["label"],context=mx.gpu())
sym, arg_params, aux_params = mx.model.load_checkpoint("mxnet_", 3)
mxnet_model2 = mx.mod.Module(symbol=sym,label_names=["label"],context=mx.gpu())
mxnet_model2.bind(data_shapes=train_iter.provide_data, label_shapes=train_iter.provide_label)
mxnet_model2.set_params(arg_params,aux_params)
mxnet_model2.score(val_iter,acc)
print(acc)
EvalMetric: {'accuracy': 0.97799999999999998}
gluon
gluon保存模型
使用gluon.Block.save_params()可以保存模型
gluon_model.save_params("gluon_model")
gluon载入模型
使用gluon.Block.load_params()可以载入模型参数
gluon_model2.load_params("gluon_model",ctx=mx.gpu())
def evaluate_accuracy():
acc = mx.metric.Accuracy()
for i, (data, label) in enumerate(gluon_test_data):
data = data.as_in_context(mx.gpu()).reshape((-1, 784))
label = label.as_in_context(mx.gpu())
output = gluon_model2(data)
predictions = mx.nd.argmax(output, axis=1)
acc.update(preds=predictions, labels=label)
return acc.get()[1]
evaluate_accuracy()
0.95079999999999998