【卷积神经网络结构专题】一文详解AlexNet(附代码实现)
关注上方“深度学习技术前沿”,选择“星标公众号”,
资源干货,第一时间送达!

【导读】本文是卷积神经网络结构系列专题第二篇文章,前面我们已经介绍了第一个真正意义上的卷积神经网络,那就是由发明者Lecun发明的LeNet,详细解读见:【卷积神经网络结构专题】一文详解LeNet(附代码实现)
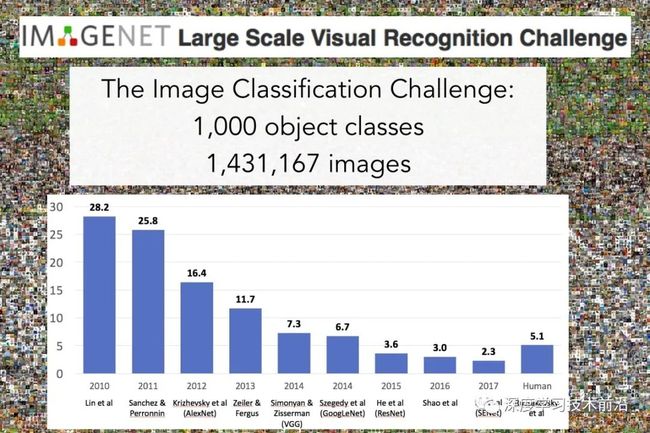
但是在LeNet发明后的几十年时间,深度学习仍然处于低潮期,很少人去做研究。直到2012年AlexNet在ImageNet竞赛中以超过第二名10.9个百分点的绝对优势一举夺冠开始,深度学习和卷积神经网络一举成名。自此,深度学习的相关研究越来越多,一直火到了今天。下面这张图是历年来ImageNet的冠军方案所提出来的网络结构,本卷积神经网络结构专题也将沿着这张图来对网络架构依次解读。
AlexNet论文

论文地址:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
代码地址:https://github.com/rasbt/deeplearning-models

AlexNet网络结构

如上图所示,AlexNet网络架构的参数统计如下:
卷积层:5层
全连接层:3层
池化层:3层
深度:8层
参数个数:60M
神经元个数:650k
分类数目:1000类
网络基本架构为:conv1 (96) -> pool1 -> conv2 (256) -> pool2 -> conv3 (384) -> conv4 (384) -> conv5 (256) -> pool5 -> fc6 (4096) -> fc7 (4096) -> fc8 (1000) -> softmax。AlexNet有着和LeNet-5相似网络结构,但更深、有更多参数。conv1使用11×11的滤波器、步长为4使空间大小迅速减小(227×227 -> 55×55)。
网络结构参数详细介绍:
从上图还可以看到网络有两个分支,这是由于当时的显卡容量问题,AlexNet 的60M个参数无法全部放在一张显卡上操作,所以采用了两张显卡分开操作的形式,其中在C3,R1,R2,R3层上出现交互,所谓的交互就是通道的合并,是一种串接操作。为了增强模型的泛化能力,避免过拟合的发生,论文使用了随机裁剪的方法将原始的 的图像随机裁剪,得到尺寸为 的图像,输入到网络训练。

AlexNet网络结构流程图
注意:数据输入时,图片大小为[224,224,3],第一个卷积层conv1的卷积核尺寸为 ,滑动步长为 ,卷积核数目为96。卷积后得到的输出矩阵维度为[96,55,55],值得注意的是如果直接按照卷积的定义来计算的话,那么输出特征的长宽应该是 ,这个值并不是 ,因此这里的值是将原图做了padding之后再进行卷积得到的,具体来说就是将原图padding到 ,这样再计算就是 了。所以这一层的输出特征图维度就是[96,55,55]。
网络结构中每一层的具体操作:

AlexNet 中60M参数介绍:
AlexNet只有8层,但是它需要学习的参数有60000000个,相比如他的层数,这是一个很可怕的数字了,我们来计算下这些参数都是怎么来的:
C1:96×11×11×3(卷积核个数/宽/高/厚度) 34848个
C2:256×5×5×48(卷积核个数/宽/高/厚度) 307200个
C3:384×3×3×256(卷积核个数/宽/高/厚度) 884736个
C4:384×3×3×192(卷积核个数/宽/高/厚度) 663552个
C5:256×3×3×192(卷积核个数/宽/高/厚度) 442368个
R1:4096×6×6×256(卷积核个数/宽/高/厚度) 37748736个
R2:4096×4096 16777216个
R3:4096×1000 4096000个
在R1中卷积核尺寸是6×6×256而不是13×13×256是因为经过了最大池化。可以看到,全连接层(尤其是第一层)参数数量占了绝大部分。
AlexNet的创新点
1.使用了ReLU激活函数
AlexNet之前神经网络一般使用tanh或者sigmoid作为激活函数,sigmoid激活函数的表达式为: tanh激活函数的表达式为:![]() ,这些激活函数在计算梯度的时候都比较慢,而AlexNet提出的
,这些激活函数在计算梯度的时候都比较慢,而AlexNet提出的ReLU表达式为: 。实验结果表明,要将深度网络训练至training error rate达到25%的话,ReLU只需5个epochs的迭代,但tanh单元需要35个epochs的迭代,用ReLU比tanh快6倍。
2.使用了随机失活(dropout)。
Dropout属于正则化技术中的一种,dropout的作用是增加网络的泛化能力,可以用在卷积层和全连接层。但是在卷积层一般不用dropout, dropout是用来防止过拟合的过多参数才会容易过拟合,卷积层参数本来就没有全连接层参数多,因此,dropout一般常用在全连接层。该方法通过让全连接层的神经元(该模型在前两个全连接层引入Dropout)以一定的概率失去活性(比如0.5)失活的神经元不再参与前向和反向传播,相当于约有一半的神经元不再起作用。
3.局部响应归一化(Local Response Normalization)
AlexNet中认为ReLU激活函数的值域没有一个固定的区间(sigmoid激活函数值域为(0,1)),所以需要对ReLU得到的结果进行归一化,这一点有点像之后的BN,都是改变中间特征图权重分布加速收敛。即论文提出的Local Response Normalization。
LPR作用原理:建立局部竞争机制,使局部较大值得到较大的响应,至于局部的范围是多大,可以通过超参数n进行选择相邻的核,定义想要的局部大小。这种归一化操作实现了某种形式的横向抑制。局部响应归一化的计算公式如下:

参数解释如下:
i:代表下标,即要计算的像素值的下标,从0开始开始算起。j:代表平方累加索引,即从j~i的像素值平方求和。x,y:代表像素中的位置,公式中用不到。a:代表特征图里面i对应的像素值。N:每个特征图最内层向量的列数。k:超参数,由网络层中的blas指定。alpha:超参数,由网络层中的alpha指定。n/2:超参数,由网络层中的deepth_radius指定。beta:超参数,由网络层中的belta指定。
4. 使用了很多数据增强技术
1. 第一种数据增强的方法是将原图片大小为256*256中随机的提取224*224的图片,以及他们水平方向的映像。
2. 第二种数据增强的方法就是在图像中每个像素的R、G、B值上分别加上一个数,用到的方法为PCA。数学表达式如下:

p是主成分,lamda是特征值,alpha是N(0,0.1)高斯分布中采样得到的随机值。此方案名义上得到自然图像的重要特性,也就是说,目标是不随着光照强度和颜色而改变的。
3. AlexNet训练采用的是SGD,每批图像大小为128,动力为0.9(SGD+momentum(0.9), weight decay)

基于Pytorch的AlexNet代码实现
class AlexNet(nn.Module):
def __init__(self, num_classes):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), 256 * 6 * 6)
logits = self.classifier(x)
probas = F.softmax(logits, dim=1)
return logits, probas参考链接:
https://blog.csdn.net/chaipp0607/article/details/72847422
https://zhuanlan.zhihu.com/p/31727402
https://mp.weixin.qq.com/s/4nTRYbIZOLcMdqYpRpui6A
https://blog.csdn.net/qq_38807688/article/details/84206655
推荐阅读:
惊!!!CV界的BERT要来了?准确率提高近25%!
干货|最全面的卷积神经网络入门教程
【最新综述】轻量级神经网络架构综述
论文大盘点|卷积神经网络必读的100篇经典论文,包含检测/识别/分类/分割多个领域
【汇总】一大波CVPR2020开源项目重磅来袭!

欢迎添加群助手微信,进计算机视觉微信交流群探讨CV相关内容!

???? 长按识别添加,邀请您进群!
原创不易,在看鼓励!比心哟!
