在Ubantu上安装配置Hadoop3,Hadoop3编译运行java程序
Ubantu19安装配置Hadoop3
主要参考了这两篇博客:
https://blog.csdn.net/weixin_38883338/article/details/82928809
https://blog.csdn.net/kongxx/article/details/79350554
需要注意的是,Hadoop3配置xml文件与Hadoop2配置xml文件不太一样。
(对于我的系统):
Hadoop bin和sbin所在的文件夹:/usr/local/hadoop
将Hadoop添加到PATH中:
https://blog.csdn.net/qjk19940101/article/details/70666349
在运行hadoop相关命令时,'/'代表的是'hdfs://localhost:9000'
有一些.sh配置文件在/usr/local/hadoop/etc/hadoop里,比如hadoop-env.sh。
Hadoop编译、运行java文件
参考实验楼和https://zhidao.baidu.com/question/584362783924066045.html?fr=iks&word=hadoop3+%D4%CB%D0%D0java&ie=gbk.
前提是已经配置好java.
1. 启动Hadoop
start-all.sh2. 在hadoop目录下创建myclass和input文件
mkdir -p myclass input3. 进入input目录,建立例子文件上传到hdfs中
touch quangle.txt
vim quangle.txthadoop fs -mkdir /class4
hadoop fs -ls /cd /usr/local/hadoop/input
hadoop fs -copyFromLocal quangle.txt /class4/quangle.txt
hadoop fs -ls /class44. 配置本地环境
cd /usr/local/hadoop/etc/hadoop
sudo vim hadoop-env.sh
添加:
export HADOOP_CLASSPATH=/usr/local/hadoop/myclass5. 编写代码
cd /usr/local/hadoop/myclass/
vim FileSystemCat.java6. 编译代码
javac -classpath ../share/hadoop/common/hadoop-common-3.2.0.jar FileSystemCat.java
7. 打包class
jar -cvf FileSystemCat.jar -C . FileSystemCat.class此时该文件目录里面会有:
FileSystemCat.class FileSystemCat.jar FileSystemCat.java三个文件.
8. 运行java程序
hadoop jar FileSystemCat.jar FileSystemCat /class4/quangle.txt对于hadoop1,可以这样写:
./hadoop jar ../hadoop-examples-1.2.1.jar wordcount /home/hadoop/input /home/hadoop/output记录一下配置过程中遇到的问题
1. Hadoop 没办法启动resourcemanager和nodemanager,查看log发现java.lang.ClassNotFoundException: javax.activation.DataSource错误。
是jdk版本的问题,我之前安装的是jdk12,对javax api的调用有限制,应该改成jdk8。
重新下载一个就好,之前那个不用删,但是要改 .bashrc,etc/profile,以及hadoop/etc/里面那些ev.sh的JAVA_HOME,然后source重启,如果出现了灵异事件,那就把电脑重启一下,确保环境更新了。
2.
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/yarn/exceptions/YarnRuntimeException
将yarn - site.xml中的yarn.application.classpath配置项注释掉,就可以正常跑wordcount.
3. 每次启动都要重新格式化namenode
在网上找到了相应的解决方法http://blog.csdn.net/bychjzh/article/details/7830508
内容如下:
最近遇到了一个问题,执行start-all.sh的时候发现JPS一下namenode没有启动
每次开机都得重新格式化一下namenode才可以
其实问题就出在tmp文件,默认的tmp文件每次重新开机会被清空,与此同时namenode的格式化信息就会丢失
于是我们得重新配置一个tmp文件目录
首先在home目录下建立一个hadoop_tmp目录
sudo mkdir ~/hadoop_tmp
然后修改hadoop/conf目录里面的core-site.xml文件,加入以下节点:
注意:我的用户是chjzh所以目录是/home/chjzh/hadoop_tmp
OK了,重新格式化Namenode
hadoop namenode -format
然后启动hadoop
start-all.sh
执行下JPS命令就可以看到NameNode了
我依照上面的方法操作后,发现还是无法启动。
最后才明白,是新建的目录没有修改权限,图点简单,就直接给了777权限,然后就都好了。
室友推荐了一篇更加详细的配置hadoop 的文章,图文并茂。
http://blog.csdn.net/hitwengqi/article/details/8008203
(core-site.xml 和 hdfs-site.xml的配置参考了这篇博客)
Hadoop小项目——倒排索引
步骤:
1. 启动hadoop
start-all.sh
jps
2. 在hdfs中创建input和output目录
hadoop fs -mkdir /cn
cd /usr/local/hadoop/input
touch file0.txt
# vim
touch file1.txt
# vim
touch file2.txt
# vim
hadoop fs -copyFromLocal file0.txt /cn/file0.txt
hadoop fs -copyFromLocal file1.txt /cn/file1.txt
hadoop fs -copyFromLocal file2.txt /cn/file2.txt
hadoop fs -mkdir /cn_output
3. 编辑java源文件
cd /usr/local/hadoop/myclass
vim InvertedIndexMapper.java
vim InvertedIndexCombiner.java
vim IntertedIndexReducer.java
vim InvertedIndexRunner.java
4. 整合、下载必须的编译java文件所需要的jar,并(为了方便)写成shell文件
编译java程序时会报错:找不到 org.apache.common.lang符号,所以我在官网上下载了lang的binary版的tar.gz,然后解压缩,发现里面有一个commons-lang-2.6.jar的文件,然后我把它拷贝在了/usr/local/hadoop/share/hadoop/common里。
# now we are in /usr/local/hadoop/myclass
touch cn_run.sh
vim cn_run.sh
chmod +x cn_run.shcn_run.sh里面的内容:
javac -classpath ../share/hadoop/common/hadoop-common-3.2.0.jar:../share/hadoop/common/commons-lang-2.6.jar:../share/hadoop/mapreduce/hadoop-mapreduce-client-common-3.2.0.jar:../share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.2.0.jar InvertedIndexRunner.java
5. 先编译、打包除了InvertedIndexRunner之外的三个java程序(因为Runner的编译需要依赖于几个class)
jar -cvf InvertedIndexMapper.jar -C . InvertedIndexMapper.class
jar -cvf InvertedIndexCombiner.jar -C . InvertedIndexCombiner.class
jar -cvf InvertedIndexReducer.jar -C . InvertedIndexReducer.class 6. 编译、打包InvertedIndexRunner.java
vim cn_run.shcn_run.sh里面的内容:
javac -classpath ../share/hadoop/common/hadoop-common-3.2.0.jar:../share/hadoop/common/commons-lang-2.6.jar:../share/hadoop/mapreduce/hadoop-mapreduce-client-common-3.2.0.jar:../share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.2.0.jar:/usr/local/hadoop/myclass/InvertedIndexMapper.jar:/usr/local/hadoop/myclass/InvertedIndexCombiner.jar:/usr/local/hadoop/myclass/InvertedIndexReducer.jar InvertedIndexRunner.java
jar -cvf InvertedIndexRunner.jar -C . InvertedIndexRunner.class
7. 运行
hadoop jar InvertedIndexRunner.jar InvertedIndexRunner /cn /cn_output
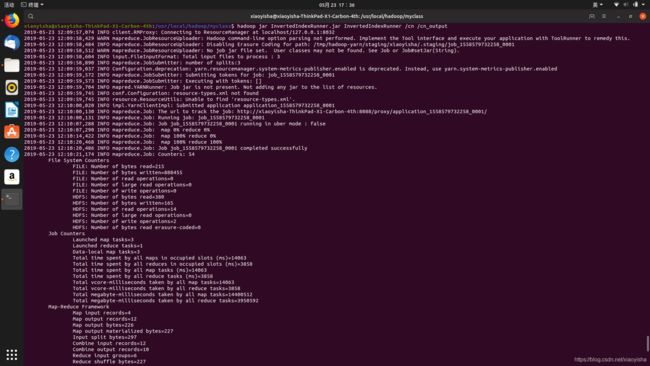
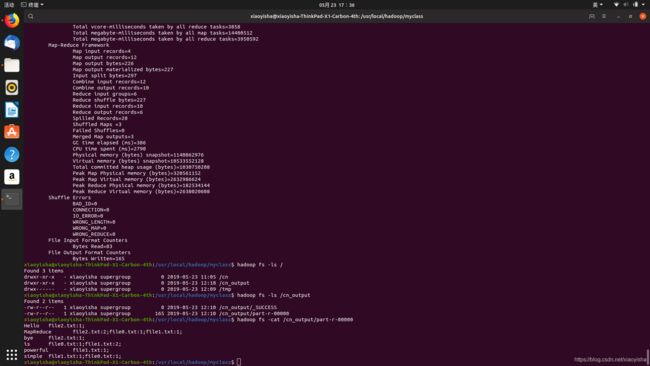
大功告成啦!
可以通过 localhost:50070查看hdfs状态,通过localhost:8088查看yarn管理状态。
用wireshark抓取本地数据包:
在wireshark图形化面板中选择 捕获-选项-loopback,然后点开始。
1. 心跳数据包
start-all.sh
2. hdfs
hadoop fs -ls /