int转byte数组以及相关原理
零、前言
本文由int转byte数组这样的题目代码引发的思考,其中涉及到多个让我混淆的地方。
直接上代码
public byte[] toBytes(int number){
byte[] bytes = new byte[4];
bytes[3] = (byte)number;
bytes[2] = (byte) ((number >> 8) & 0xFF);
bytes[1] = (byte) ((number >> 16) & 0xFF);
bytes[0] = (byte) ((number >> 24) & 0xFF);
return bytes;
}
如果对这段代码了然于胸,原理思路清洗,就可以不用阅读本文了。如果对这段代码的原理不是那么清晰,那么很可能是某个基础知识模糊遗忘了。
我们知道int强转成short,甚至char。但byte数组给人的感觉就是二进制的东西,好像和那些基本类型“不在一个维度上”,甚至想象不出转换出来是个什么效果,能打印出来吗。。。之所以会有这些疑问,因为我们对byte的一些基本概念混淆了,或许是从来没真正的理解透过。
一、先思考几个基础问题
问题一:byte是java基本类型吗,如果是,那它属于哪一类基本类型
问题二:byte是计算机中最小的单位吗,char呢? 能清晰的想出来java里8种基本类型的字节长度以及取值长度吗
问题三:我们知道java四个整数类型可以相互强转,比如,int转byte是怎么做的
问题四:如何理解程序中的& 0xFF是否必要,可否去掉
问题五:把int切成四个byte,放在byte[]里,顺序怎么摆放
问题六:我们应该学过“原码”、“反码”,“补码”,那么java的基础数值类型在计算机里是用的补码吗
以上这些问题先不要看答案,自己是否能很清晰的回答出来。
问题一答案
byte是java基本类型,而且是整数型(它不止可以用来表示二进制数据,还能表示数字哦)。
工作中我们会经常用byte数组,基本都是在涉及IO流传输数据相关代码中使用。也许就是用的场景太单一顺手了,byte给我们的感觉就是二级制的数据流,渐渐的就忽略了 这个类型居然和int之类 是一类东西,它的大小范围是-128~127,是不是好像在哪听过这个范围。是short吗,答案是否定的。这个范围还出现在Integer使用地址比较相等的时候,因为Integer会把-128-127范围内的数字放入常量池,我们可以直接使用==来比较是否相等。
问题二答案
byte 名字节,大该是因为他的英文名字听起来好像叫“比特”,和bit很像,然后又经常被用在数据流中,给人感觉就好像这是一个不可分割的最小单位。但实际上byte占8位,即 1byte = 8 bit。所以不是计算机中最小单位。
也许你在用数据库的时候,使用过bit这个数据类型,它只有true和false两个值(也就是1和0),这个单位我们可以称之为“位”,也就是我们所谓的最小单位。但不要和byte搞混了,他们之间差了8倍。 char就更大了,java中占两个字节,c语言中占一个字节。
8种基本类型字节数以及取值范围
| 类型 | 字节大小 | 取值范围 |
|---|---|---|
| byte | 1 | -(2^7) ~ (2^7) - 1 |
| short | 2 | -(2^15) ~ (2^15) - 1 |
| int | 4 | -(2^31) ~ (2^31) - 1 |
| long | 8 | -(2^63) ~ (2^63) - 1 |
| char | 2 | - |
| boolean | 4或1 | true,false |
| float | 4 | 6位有效数字 |
| double | 8 | 15位有效数字 |
在这张表里,你可能会对boolean这个类型产生疑问。对于本题答案,你甚至会想byte和boolean是不是有什么关联(你可能隐约感觉两者都是用来表示0和1的)。 当然这是完全错的,即使是bit和boolean也没什么联系,boolean在java中也不是只占1位。因为java中并没有规定boolean的表示方法,实际中boolean占了4字节(和int一样大),boolean[]中bolean元素则占1字节,所以上面表格里写4或1。
问题三答案
首先注意这里是说int强转成byte,而不是本文所说的int转byte[]。通过前一个问题我们知道int占32位,而byte占8位。比如int a10 = 261对应的二进制就是100000101【左边剩下的23个0就省略了】,想转成byte也很简单,就是直接截取最右边8位即可:00000101【十进制的5】,也就是261强转byte后等于5。
问题四答案
十六进制0xFF 也就是二进制的11111111, &运算的作用就是把两个二进制右边对齐,然后逐个&运算,只有两者都是1时结果才是1,
等效于截取右边8位二进制数。通过问题三,可知int强转byte就是简单截取右边8位,没有必要再& 0xFF。 所以上面的代码可以这么写
public byte[] toBytes(int number){
byte[] bytes = new byte[4];
bytes[3] = (byte)number;
bytes[2] = (byte) (number >> 8);
bytes[1] = (byte) (number >> 16);
bytes[0] = (byte) (number >> 24);
return bytes;
}
问题五答案
通过理解这段代码我们知道,int的32位二进制,最终被截断成4段,然后把这4段以byte的形式放入byte数组。如下所示
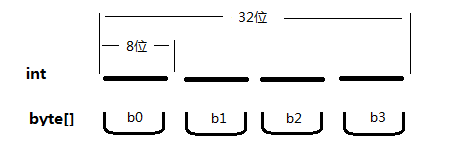
也许会有疑问,为什么不是这样
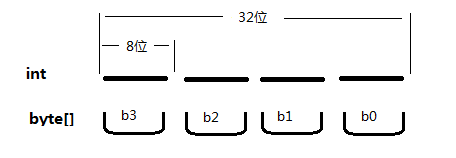
因为在二进制截取、排序的过程中 不要带入“意义”。也就是说,在排这些二进制段的时候不要想着这段二进制原本是什么意思(比如这里就不要想着这32位二进制是一个int数字),可以简单认为,这就是一串毫无意义字符串。而这串字符串就是从左往右读的,左边是开始,右边是结束。
另一个更准确的理解方式是:通过一个实际的例子画出图就能很容易看出
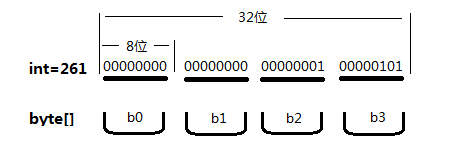
如果把00000101放在b0中,那么这个byte[]无论正着读还是反着读,二进制数字都是乱的。
问题六答案
首先给出答案:是的。 如果这个问题这么问:计算机中是使用原码还是补码表示数字,基本大家都会答:补码。这个问题之所以这么问,就是看概念是否清晰准确。如果关于补码的概念模糊的话,甚至可能会觉得补码应用于计算机内的所有信息,整数是不是用的补码反而不确定了。 下面就复习一下关于补码的知识:
上面说了,byte的取值范围是-128~127,这个范围我们应该不陌生,但为什么呢,为什么不是“两头对称”的呢,这就是补码造成的。
在问题三答案,我们明白了int是如何转成byte的,例子大家应该也都能看明白。现在换一个例子int a = -216,二进制为1111111111111111111111111111111111111111111111111111111011111011,同样截取后8位,结果是11111011,表示十进制的-5。如果对这个计算过程以及结果有点意外,说明对补码认识不足。下面就以byte类型(8位二进制)为例,讲解一下补码 首先说一下概念及结论:
- java中的数字都是有符号的,即有正有负
- 有符号数字表示的二进制中左边第一位是符号位,0表示正数,1表示负数
- 原码:8位有符号的二级制的原始表达方式
- 反码:原码符号位不变,其他位取反(就是0变1,1变0)
- 补码:反码+1
- 计算机中的数字使用补码表示
- 使用规则: 正数的原码和补码一样(也就不存在反码),负数的反码根据上面的规则计算,即反码+1
为什么产生反码
- 原码中的 0000000【+0】 1000000【-0】
有正0和负0,这两个本来一样的数却有两个不同的表示方式 - 原码的符号位不方便计算,而补码却能巧妙的把符号位带着一起做加法运算(这个就不细讲)。
根据上面的规则,byte的256个数字对应关系如下
| 二进制表示 | 00000000 | 0000001 | … | 01111111 |
|---|---|---|---|---|
| 无符号十进制数字 | 0 | 1 | … | 127 |
| 补码十进制数字 | 0 | 1 | … | 127 |
续
| 10000000 | 1000001 | … | 11111111 |
|---|---|---|---|
| 128 | 129 | … | 255 |
| -128 | -127 | … | -1 |
函数图如下
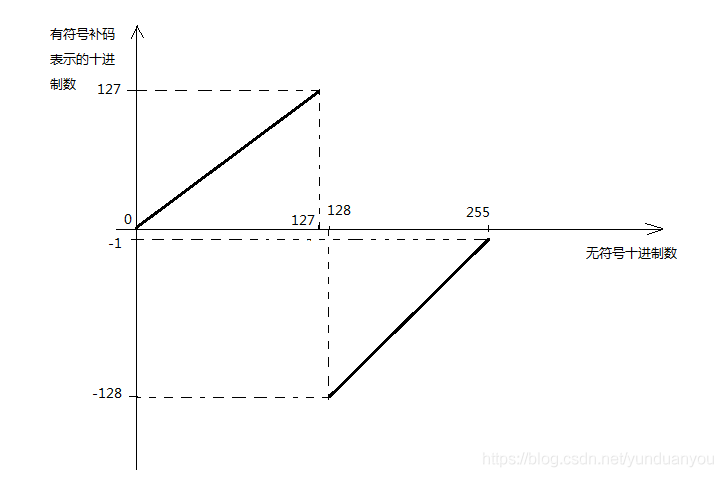
通过表格以及函数图,很明显看出byte的表示范围是-128 ~ 127【y轴。虽然画的是连续直线,其实是离散点】
二、总结
本程序简单讲就是:把32位的int像“切甘蔗”一样平均切成4段byte,从左至右依次放入byte[]。 前提是要理解byte、int等基本类型的本质,以及补码的作用及使用方式。懂了这些原理,不仅仅可以解决int转byte数组,反过来转换也是比较容易理解的。