前文说到容器网络对Linux虚拟化技术的依赖,这一篇章我们将一探究竟,看看Docker究竟是怎么做的。
通常,Linux容器的网络是被隔离在它自己的Network Namespace中,其中就包括:网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和iptables规则。
对于一个进程来说,这些要素,就构成了它发起和响应网络请求的基本环境。
管中窥豹
我们在执行docker run -d --name xxx之后,进入容器内部:
## docker ps 可查看所有docker
## 进入容器
docker exec -it 228ae947b20e /bin/bash并执行 ifconfig:
$ ifconfig
eth0 Link encap:Ethernet HWaddr 22:A4:C8:79:DD:1A
inet addr:192.168.65.28 Bcast:0.0.0.0 Mask:255.255.255.255
UP BROADCAST RUNNING MULTICAST MTU:1440 Metric:1
RX packets:2231528 errors:0 dropped:0 overruns:0 frame:0
TX packets:3340914 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:249385222 (237.8 MiB) TX bytes:590701793 (563.3 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)我们看到一张叫eth0的网卡,它正是一个Veth Pair设备在容器的这一端。我们再通过 route 查看该容器的路由表:
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 * 255.255.255.255 UH 0 0 0 eth0我们可以看到这个eth0是这个容器的默认路由设备。我们也可以通过第二条路由规则,看到所有对 169.254.1.1/16 网段的请求都会交由eth0来处理。而Veth Pair 设备的另一端,则在宿主机上,我们同样也可以通过查看宿主机的网络设备来查看它:
$ ifconfig
......
eth0: flags=4163 mtu 1500
inet 172.16.241.192 netmask 255.255.240.0 broadcast 172.16.255.255
ether 00:16:3e:0a:f3:75 txqueuelen 1000 (Ethernet)
RX packets 3168620550 bytes 727592674740 (677.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2937180637 bytes 8661914052727 (7.8 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
......
docker0: flags=4099 mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:16:58:92:43 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
......
vethd08be47: flags=4163 mtu 1500
ether 16:37:8d:fe:36:eb txqueuelen 0 (Ethernet)
RX packets 193 bytes 22658 (22.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 134 bytes 23655 (23.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
......
在宿主机上,容器对应的Veth Pair设备是一张虚拟网卡,我们再用brctl show命令查看网桥:
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242afb1a841 no vethd08be47可以清楚的看到Veth Pair的一端 vethd08be47 就插在 docker0 上。我现在执行docker run 启动两个容器,就会发现docker0上插入两个容器的 Veth Pair的一端。如果我们在一个容器内部互相ping另外一个容器的IP地址,是不是也能ping通?
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242afb1a841 no veth26cf2cc
veth8762ad2容器1:
$ docker exec -it f8014a4d34d0 /bin/bash
$ ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:03
inet addr:172.17.0.3 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:76 errors:0 dropped:0 overruns:0 frame:0
TX packets:106 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:16481 (16.0 KiB) TX bytes:14711 (14.3 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:48 errors:0 dropped:0 overruns:0 frame:0
TX packets:48 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2400 (2.3 KiB) TX bytes:2400 (2.3 KiB)
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 * 255.255.0.0 U 0 0 0 eth0容器2:
$ docker exec -it 9a6f38076c04 /bin/bash
$ ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
inet addr:172.17.0.2 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:133 errors:0 dropped:0 overruns:0 frame:0
TX packets:193 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:23423 (22.8 KiB) TX bytes:22624 (22.0 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:198 errors:0 dropped:0 overruns:0 frame:0
TX packets:198 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:9900 (9.6 KiB) TX bytes:9900 (9.6 KiB)
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 * 255.255.0.0 U 0 0 0 eth0从一个容器ping另外一个容器:
# -> 容器1内部 ping 容器2
$ ping 172.17.0.3
PING 172.17.0.3 (172.17.0.3): 56 data bytes
64 bytes from 172.17.0.3: seq=0 ttl=64 time=0.142 ms
64 bytes from 172.17.0.3: seq=1 ttl=64 time=0.096 ms
64 bytes from 172.17.0.3: seq=2 ttl=64 time=0.089 ms我们看到,在一个容器内部ping另外一个容器的ip,是可以ping通的。也就意味着,这两个容器是可以互相通信的。
容器通信
我们不妨结合前文时所说的,理解下为什么一个容器能访问另一个容器?先简单看如一幅图:
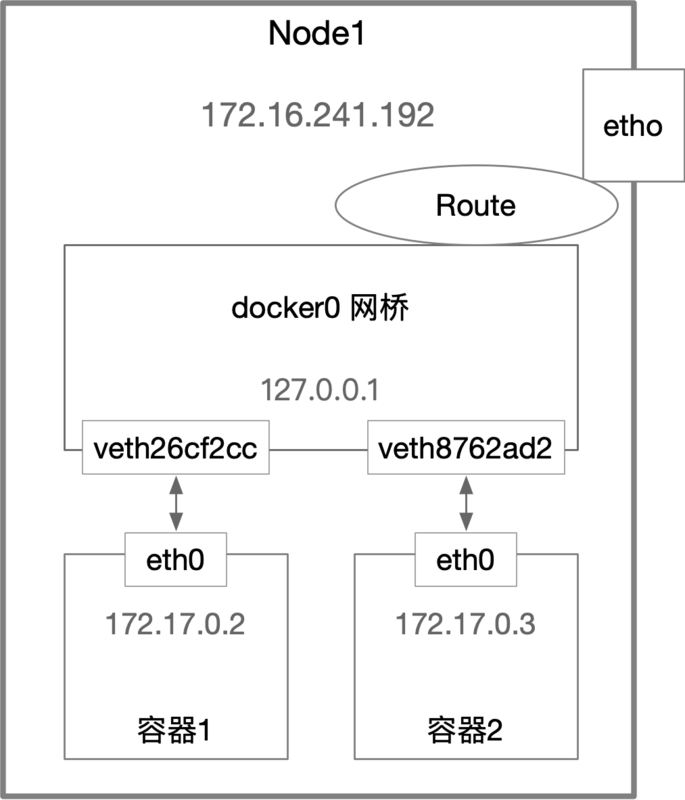
当在容器1里访问容器2的地址,这个时候目的IP地址会匹配到容器1的第二条路由规则,这条路由规则的Gateway是0.0.0.0,意味着这是一条直连规则,也就是说凡是匹配到这个路由规则的请求,会直接通过eth0网卡,通过二层网络发往目的主机。而要通过二层网络到达容器2,就需要127.17.0.3对应的MAC地址。
所以,容器1的网络协议栈就需要通过eth0网卡来发送一个ARP广播,通过IP找到MAC地址。所谓ARP(Address Resolution Protocol),就是通过三层IP地址找到二层的MAC地址的协议。这里说到的eth0,就是Veth Pair的一端,另一端则插在了宿主机的docker0网桥上。eth0这样的虚拟网卡插在docker0上,也就意味着eth0变成docker0网桥的“从设备”。从设备会降级成docker0设备的端口,而调用网络协议栈处理数据包的资格全部交给docker0网桥。
所以,在收到ARP请求之后,docker0就会扮演二层交换机的角色,把ARP广播发给其它插在docker0网桥的虚拟网卡上,这样,127.17.0.3就会收到这个广播,并把其MAC地址返回给容器1。有了这个MAC地址,容器1的eth0的网卡就可以把数据包发送出去。这个数据包会经过Veth Pair在宿主机的另一端veth26cf2cc,直接交给docker0。
docker0转发的过程,就是继续扮演二层交换机,docker0根据数据包的目标MAC地址,在CAM表查到对应的端口为veth8762ad2,然后把数据包发往这个端口。而这个端口,就是容器2的Veth Pair在宿主机的另一端,这样,数据包就进入了容器2的Network Namespace,最终容器2将响应(Ping)返回给容器1。在真实的数据传递中,Linux内核Netfilter/Iptables也会参与其中,这里不再赘述。
CAM就是交换机通过MAC地址学习维护端口和MAC地址的对应表。
这里介绍的容器间的通信方式就是docker中最常见的bridge模式,当然此外还有host模式、container模式、none模式等,对其它模式有兴趣的可以去阅读相关资料。
跨主通信
好了,这里不禁问个问题,到目前为止只是单主机内部的容器间通信,那跨主机网络呢?在Docker默认配置下,一台宿主机的docker0网桥是无法和其它宿主机连通的,它们之间没有任何关联,所以这些网桥上的容器,自然就没办法多主机之间互相通信。但是无论怎么变化,道理都是一样的,如果我们创建一个公共的网桥,是不是集群中所有容器都可以通过这个公共网桥去连接?
当然在正常的情况下,节点与节点的通信往往可以通过NAT的方式,但是,这个在互联网发展的今天,在容器化环境下未必适用。例如在向注册中心注册实例的时候,肯定会携带IP,在正常物理机内的应用当然没有问题,但是容器化环境却未必,容器内的IP很可能就是上文所说的172.17.0.2,多个节点都会存在这个IP,大概率这个IP是冲突的。
如果我们想避免这个问题,就会携带宿主机的IP和映射的端口去注册。但是这又带来一个问题,即容器内的应用去意识到这是一个容器,而非物理机,当在容器内,应用需要去拿容器所在的物理机的IP,当在容器外,应用需要去拿当前物理机的IP。显然,这并不是一个很好的设计,这需要应用去配合配置。所以,基于此,我们肯定要寻找其他的容器网络解决方案。
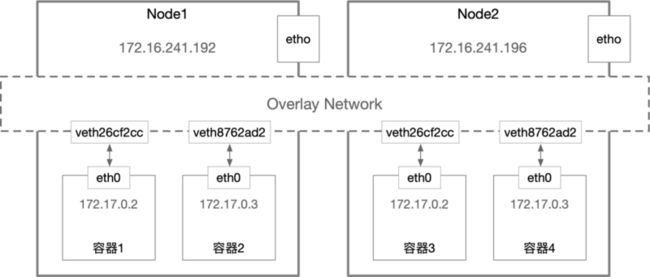
在上图这种容器网络中,我们需要在我们已有的主机网络上,通过软件构建一个覆盖在多个主机之上,且能把所有容器连通的虚拟网络。这种就是Overlay Network(覆盖网络)。关于这些具体的网络解决方案,例如Flannel、Calico等,我会在后续篇幅继续陈述。
福利:豆花同学为大家精心整理了一份关于linux和python的学习资料大合集!有需要的小伙伴们,关注豆花个人公众号:python头条!回复关键词“资料合集”即可免费领取!
