手机自动化测试——爬取朋友圈
一般抓取手机app都是通过Fiddler或者Charles进行抓包,然后解析响应数据,但是微信加密比较恶心,所以换一个思路,通过获取手机控件信息,进而得到微信朋友圈数据。常用的python库为appium,但是它安装太复杂了,所以如果不是苹果手机,就不要难为自己了。因此这里使用python-uiautomator2操控手机,只支持安卓手机,具体准备工作可以参考博文:手机自动化测试(准备篇)
首先,导入第三方库:
import uiautomator2 as u2
import time
后面要用到xpath,对xpath不了解的可以参考:Xpath教程进行学习,由于uiautomator2对于xpath支持还并不算完善,因此这里我又写了一个类以较好的支持xpath,相当于对uiautomator2的补充
from lxml import etree
from PIL import Image
class dxpath():
def __init__(self,d):
self.d = d
def dxpath(self,arg):
#通过xpath获得etree.module,可以继续使用xpath定位,适用于从某一区域继续检索
xml_content = self.d.dump_hierarchy()
root = etree.fromstring(xml_content.encode('utf-8'))
return root.xpath(arg)
def dxpath_text(self,t,arg,One=True):
#t为dxpath迭代的对象
#for t in dxpath('')
args = '{}/@text'.format(arg)
text= []
for txt in t.xpath(args):
text.append(str(txt))
if One : return text[0]
else : return text
def center(self,arg,t=None):
bounds = '{}/@bounds'.format(arg)
try :
if t is not None: coord = str(t.xpath(bounds)[0])
else : coord = str(self.dxpath(bounds)[0])
lx, ly, rx, ry = map(int,re.findall(r"\d+", coord))
return lx, ly, rx, ry
except : raise Exception("未找到控件")
def click(self,arg,timeout=10,at_once = False,set_x=0,set_y=0,
picture=False,picture_name='crop',t=None):
#char代表识别的字符串,timeout为响应时间,at_once为只判别一次,repetition代表重复点击次数
#,set_x代表x坐标调整,picture是保存图像,picture_name为保存图片名, #t为dxpath迭代的对象
deadline = time.time() + timeout
while time.time() < deadline:
try :
lx, ly, rx, ry = self.center(arg,t)
x ,y =(lx + rx) // 2, (ly + ry) // 2
x=set_x+x ; y=set_y+y
self.d.click(x,y)
if picture:
catIm = Image.open('screenshot.jpg')
croppedIm = catIm.crop((lx+set_x, ly+set_y,
lx+set_x+rx, ly+set_y+ry))
croppedIm.save('%s.jpg'%picture_name)
return x,y
except :
if at_once : raise Exception("未找到控件")
else :time.sleep(0.1)
raise Exception("未找到控件")
构造储存数据的类
class Item(object):
name = None #更:网名
comment = None #更:数据内容
date =None #朋友圈日期
进行预备工作,将爬取的信息存入以下列表
data_value=set() #纪录已填入数据
items=[] #数据汇总
准备工作结束,下面正式开始连接手机,并打印相关信息
d = u2.connect_usb('c00c166c')
print(d.info)
实例自己的类
mi = dxpath(d)
启动微信,具体可以通过d.info查看当前进程
sess = d.session("com.tencent.mm") # start
启动微信后,需要进行控件定位,通过Appetizer进行查看,这个在准备篇里有讲。
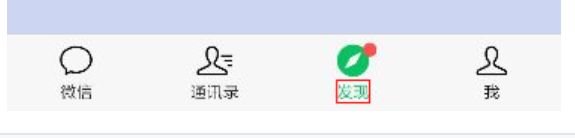
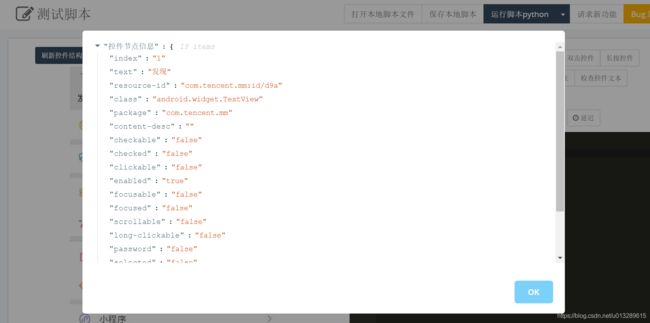
从图中可以发现,其text=“发现”,所以根据文本进行定位,但是直接点击“发现”按钮并没有反应,通过测试,需要点击发现上面的图标才可以,因此这里用到xpath

通过xpath定位发现控件,再选取他的兄弟标签,并进行点击
mi.click('//*[@text="发现"]/preceding-sibling::node')
继续通过Appetizer进行查看,点击朋友圈控件,并等待信息载入
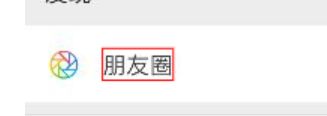

mi.click('//*[@text="朋友圈"]')
d(resourceId="com.tencent.mm:id/en0").exists()
time.sleep(2)
思路是首先获取每个信息的整体控件,再进行遍历,以防止网名和内容的匹配错误,获得一页信息后,再进行滑动,获取下一页信息,直到满足给定的条件。


通过resource-id进行定位,继续查看网名,内容,以及时间控件信息。


while len(data_value)<10: #这里只爬取10个信息
for t in mi.dxpath('//*[@resource-id="com.tencent.mm:id/emw"]'):
try:
comment = mi.dxpath_text(t,'.//*[@resource-id="com.tencent.mm:id/en0"]')
name = mi.dxpath_text(t,'.//*[@resource-id="com.tencent.mm:id/b6e"]')
date = mi.dxpath_text(t,'.//*[@resource-id="com.tencent.mm:id/ehz"]')
if comment not in data_value and not mi.dxpath_exist(t,'.//*[@resource-id="com.tencent.mm:id/egc"]'):#不能是广告
print("抓取到{}朋友圈数据:\n{}\n时间为:{}".format
(name,comment,date))
item = Item()
item.name = name
item.comment = comment
item.date = date
items.append(item)
data_value.add(comment)
print('*'*25+str(len(data_value)))
except:pass
# 滑动
d.swipe(300, 800, 300, 300, 0.1)
下面给出完整代码:
import uiautomator2 as u2
import time
from lxml import etree
from PIL import Image
class dxpath():
def __init__(self,d):
self.d = d
def dxpath(self,arg):
#通过xpath获得etree.module,可以继续使用xpath定位,适用于从某一区域继续检索
xml_content = self.d.dump_hierarchy()
root = etree.fromstring(xml_content.encode('utf-8'))
return root.xpath(arg)
def dxpath_text(self,t,arg,One=True):
#t为dxpath迭代的对象
#for t in dxpath('')
args = '{}/@text'.format(arg)
text= []
for txt in t.xpath(args):
text.append(str(txt))
if One : return text[0]
else : return text
def center(self,arg,t=None):
bounds = '{}/@bounds'.format(arg)
try :
if t is not None: coord = str(t.xpath(bounds)[0])
else : coord = str(self.dxpath(bounds)[0])
lx, ly, rx, ry = map(int,re.findall(r"\d+", coord))
return lx, ly, rx, ry
except : raise Exception("未找到控件")
def click(self,arg,timeout=10,at_once = False,set_x=0,set_y=0,
picture=False,picture_name='crop',t=None):
#char代表识别的字符串,timeout为响应时间,at_once为只判别一次,repetition代表重复点击次数
#,set_x代表x坐标调整,picture是保存图像,picture_name为保存图片名, #t为dxpath迭代的对象
deadline = time.time() + timeout
while time.time() < deadline:
try :
lx, ly, rx, ry = self.center(arg,t)
x ,y =(lx + rx) // 2, (ly + ry) // 2
x=set_x+x ; y=set_y+y
self.d.click(x,y)
if picture:
catIm = Image.open('screenshot.jpg')
croppedIm = catIm.crop((lx+set_x, ly+set_y,
lx+set_x+rx, ly+set_y+ry))
croppedIm.save('%s.jpg'%picture_name)
return x,y
except :
if at_once : raise Exception("未找到控件")
else :time.sleep(0.1)
raise Exception("未找到控件")
class Item(object):
name = None #更:网名
comment = None #更:数据内容
date =None #朋友圈日期
data_value=set() #纪录已填入数据
items=[] #数据汇总
#正式开始
d = u2.connect_usb('c00c166c')
print(d.info)
mi=dxpath(d)
sess = d.session("com.tencent.mm") # start
mi.click('//*[@text="发现"]/preceding-sibling::node')
mi.click('//*[@text="朋友圈"]')
d(resourceId="com.tencent.mm:id/en0").exists()
time.sleep(2)
while len(data_value)<10:
for t in mi.dxpath('//*[@resource-id="com.tencent.mm:id/emw"]'):
try:
comment = mi.dxpath_text(t,'.//*[@resource-id="com.tencent.mm:id/en0"]')
name = mi.dxpath_text(t,'.//*[@resource-id="com.tencent.mm:id/b6e"]')
date = mi.dxpath_text(t,'.//*[@resource-id="com.tencent.mm:id/ehz"]')
if comment not in data_value and not mi.dxpath_exist(t,'.//*[@resource-id="com.tencent.mm:id/egc"]'):#不能是广告
print("抓取到{}朋友圈数据:\n{}\n时间为:{}".format
(name,comment,date))
item = Item()
item.name = name
item.comment = comment
item.date = date
items.append(item)
data_value.add(comment)
print('*'*25+str(len(data_value)))
except:pass
# 滑动
d.swipe(300, 800, 300, 300, 0.1)