王家林大咖清华新书预发布:《企业级AI技术内幕:深度学习框架开发+机器学习案例+Alluxio解密》之盘古人工智能框架多层次神经网络的实现
本文是王家林大咖清华大学新书《企业级AI技术内幕:深度学习框架开发+机器学习案例+Alluxio解密》第2.1章节的内容,清华大学出版社将于9月份出版新书。
目录
- 盘古人工智能框架引言
- 盘古人工智能框架
- 盘古人工智能框架代码实战
- 实现神经网络的节点结构
- 新书预发布
- 新书 前 言
盘古人工智能框架引言
2017年3月21日,王家林大咖在硅谷,利用三个月的时间,于2017年6月22日实现了盘古人工智能框架,在该框架中实现了基本的ANN(Artificial Neural Network)和CNN(Convolutional Neural Network),那时还没实现RNN(Recurrent neural Network),但是实现了另外两个特别重要的算法,一个是自动编码(AutoEncoders),还有一个是非监督学习玻尔兹曼机算法(Boltzmann_ Machines),二者都跟推荐系统相关。对于深度学习中的算法,神经网络算法是必须掌握的,CNN、RNN等都是基于神经网络算法延伸出来的,包括自动编码算法,也是基于神经网络的算法延伸出来的。自动编码算法、玻尔兹曼机算法在实际中可用于推荐系统,在Facebook、谷歌、亚马逊的各种应用场景都可以看见推荐系统的身影;深度学习在图片识别、声音识别中可能暂时不那么重要。从2017年6月开始,用了将近10个月的时间,作者在自己开发的人工智能框架中试验了上述算法,这是做人工智能研究的核心能力之一。
研究TensorFlow、PyTorch的时候发现,TensorFlow、PyTorch和作者开发的人工智能框架思路是一样的,但在实现上有所不同。作者开发的人工智能框架满足了基本的神经网络的需要,如果要像TensorFlow、PyTorch这么强大,需要迭代很多个版本。我们将从最基础的一个版本,通过几次版本的迭代,达到自研的人工智能框架内核和TensorFlow、PyTorch的内核一致的程度。
盘古人工智能框架
盘古人工智能框架实现了多层次神经网络,这里神经网络是指它的架构,如图所示,分为神经网络的输入层、隐藏层和输出层,相当于一个程序的输入、中间的处理和输出过程。

左侧是数据的输入,最右侧是数据的输出,中间是处理的过程,有线条连接输入层、隐藏层、输出层,这就是TensorFlow数据处理的过程。这种处理的思路和用Java语言写一个“Hello World”的程序是类似的,即使用一个main入口,接着是一行打印“Hello World”语句,在代码编写上没有任何区别,只不过神经网络把数据处理代码分成几个步骤,而且这几个步骤是循环迭代的。首先是数据输入,这是第一步,任何一个程序都有数据输入的过程;第二步进行初步的处理;第三步进一步的处理,然后得出一个中间结果(注意是中间结果),然后开始循环遍历中间处理的过程,每一次都会对上一次的处理进行一点改进。重复的次数越多,理论上效果就越好。在TensorFlow网站运行一下,可视化运行图右侧是输出的效果,代表训练的误差和测试的误差,可以看到有值的变化,多次运行后会达到值变化不太明显的状态。网页左上方有个时代(Epoch)项,时代是指所有的数据都处理了一遍,一遍就是一次时代,不断重复数据的处理过程,以最大化减少误差。误差越来越小,最后变化基本停止了,基本停止或者变化非常缓慢的时候,可以停止训练,进行优化。数据有流动,通过前向传播算法从左侧流动到右侧,然后通过反向传播算法从右侧流动到左侧,不断地循环迭代,关键在于每个步骤处理完以后,下一个步重复这个步骤的时候能改进上一个步骤的表现,这是人工智能的核心,也是和传统编程不同的地方。
要想实现图所示从左到右的功能,其中又有循环,首先要有一个结构体或者对象去实现循环。这里所谓的结构体或者对象就是输入层、隐藏层、输出层,这个过程和人类学习的过程一样。人类的感知系统如图所示,人有各种感知系统,类似于人工智能的数据输入,人所感知的疼痛就类似于人工智能的激活函数,这将得出一个结果供下一步去处理。人工智能的认知过程和人的认知过程是一样的。

如图所示,神经元对外界感知并做出决定,很多时候需考虑不同因素,并且不同的因素的重要性优先级不同。权衡的因素从神经网络的角度讲是特征(Features),从数学的角度讲是维度(Dimension)。例如,预测一下读者会不会喜欢这本书。书有很多特征:出版的时间、价格、作者、出版社等,这些都是权衡的因素特征。CNN、RNN之所以强大,就在于其可以自动提取特征,而对于普通的机器学习来讲提取特征则是一个非常麻烦的过程。

如图所示,不同的特征有不同的权重,如x1、x2、x3、x4、x5…等权重,例如是否需要深厚的数学基础及编程语言基础是人工智能课程学习的一个权重,如果你选择了如需要这些基础就放弃,说明这个权重对你影响很大,所以权重系数很大,权重可能为0.9或者0.85;另外一个因素是上课时间,可能上课时间无所谓,权重可能就为0.1;课程中是否有足够的项目案例,这个特别重要,这个权重可能是0.99。特征是衡量的因素,权重是每个因素的重要性。要构建一个神经网络有几个点:输入层、输出层、中间的隐藏层,前面的层对于后面的层次都有特征及权重。
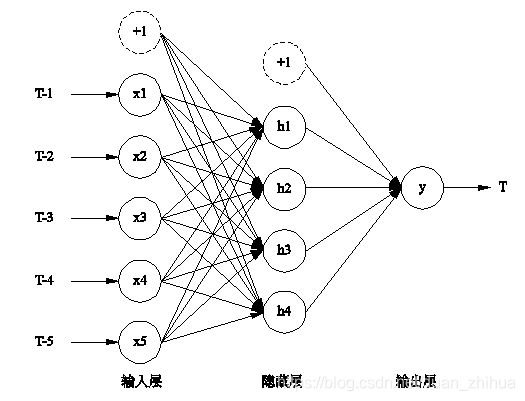
不同的权重可能还会加一个偏爱因子(Bias),例如,项目案例非常重要,则在项目案例权重0.99的基础上,可能会加一个偏爱因子。偏爱因子是额外的一个权重。
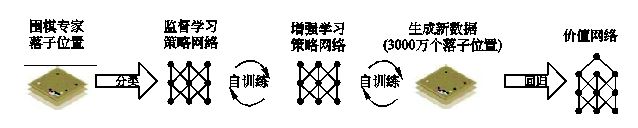
如图所示是阿尔法狗的训练过程,围棋专家给出落子位置数据,阿尔法狗通过监督学习的算法进行了一定程度的学习,也就是神经网络的深度学习;学到一定程度以后再进行增强学习。
盘古人工智能框架代码实战
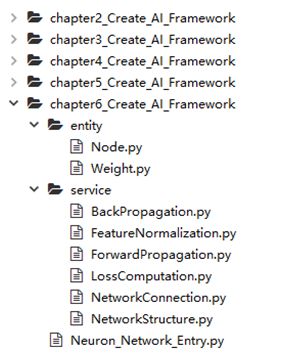
首先,我们看一下盘古人工智能框架版本的整体迭代结构图,整个盘古人工智能框架从第一个版本迭代到第五个版本,迭代版本分别为chapter2_Create_AI_Framework、chapter3_ Create_AI_Framework、chapter4_Create_AI_Framework、chapter5_Create_AI_Framework、chapter6_ Create_AI_Framework。最终的版本chapter6_Create_AI_Framework包括入口主程序Neuron_ Network_Entry.py;service目录里面包括BackPropagation.py、FeatureNormalization.py、ForwardPropagation.py、LossComputation.py、NetworkConnection.py、NetworkStructure.py 等模块;entity目录里面包括Node.py、Weight.py等Python模块,如图所示。
本文将实现盘古人工智能框架的神经元网络骨架,要实现的目录结构如图所示。
读者可以自行安装Anaconda的开发环境(https://www.anaconda.com/download/)。进入Anaconda的控制台,启动Spyder,Anaconda Spyder是一个机器学习的集成开发环境,如图所示。

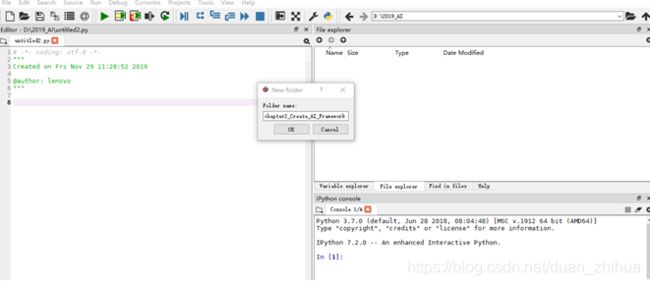
进入 Spyder 的 File explorer 窗口,创建自定义的神经网络项目目录 chapter2_Create_ AI_Framework,如图所示。
选择chapter2_Create_AI_Framework目录,单击齿轮图标,然后单击Set console working directory,设置其为工作目录,如图所示。这一步很重要,因为后续的所有代码都将放在这个目录中,该工作目录包括了上下文信息。

实现盘古人工智能框架的多层次神经网络,需要以下四个步骤:
(1)实现神经网络的节点结构。
(2)实现神经网络层之间节点的连接。
(3)初始化神经网络的权重。
(4)实现多个隐藏层。
我们要实现的人工智能框架和TensorFlow的类似,可以调整神经元的数量。第1步我们要实现神经网络的节点结构。从Java开发者的角度讲,节点结构就是JavaBean。
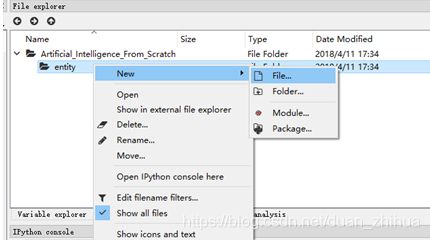
我们先在chapter2_Create_AI_Framework工作目录中建立一个子目录entity,entity的含义是实体,如图所示。

在entity子目录下创建一个节点文件Node.py,如图所示。
接下来通过代码来实现多层次神经网络功能。
实现神经网络的节点结构
下面通过代码实现神经网络的节点结构。
chapter2_Create_AI_Framework版本的Node.py的源代码如下:
1. # -*- coding: utf-8 -*-
2. class Node:
3. #第一步:设置、获得神经元在全局所处的层
4. #设置神经元在整个神经网络中唯一的层
5. def set_level(self, level):
6. self._level = level
7.
8. #获得神经元在整个神经网络中唯一的层
9. def get_level(self):
10. return self._level
11.
12. #第二步:设置、获得神经元全局唯一的ID
13.
14. #设置神经元在整个神经网络中唯一的ID
15. def set_index(self, index):
16. self._index = index
17.
18. #获得神经元在整个神经网络中唯一的ID
19. def get_index(self):
20. return self._index
21.
22. #第三步:设置、获得神经元的名字
23. #设置神经元在整个神经网络中的名称
24. def set_label(self, label):
25. self._label = label
26.
27. #获得神经元在整个神经网络中的名字
28. def get_label(self):
29. return self._label
30.
31. #第四步:判断当前的神经元是否是偏爱因子
32. #设置神经元在整个神经网络中是否是一个偏爱因子
33. def set_is_bias_unit(self, is_bias_unit):
34. self._is_bias_unit = is_bias_unit
35.
36. #获得神经元在整个神经网络中是否是一个偏爱因子
37. def get_is_bias_unit(self):
38. return self._is_bias_unit
- 第3~10行代码:设置和访问神经元在全局所处的层(Layer)。如图所示,神经网络分了很多层,需进行设置,如输入层、隐藏层、输出层等,各层都有顺序。将输入层作为整个神经网络的第0层,如果设置2个隐藏层(2个隐藏层分别包括4个、2个神经元),那么第1个隐藏层作为整个神经网络的第1层,第2个隐藏层作为整个神经网络的第2层,输出层作为整个神经网络的第3层。
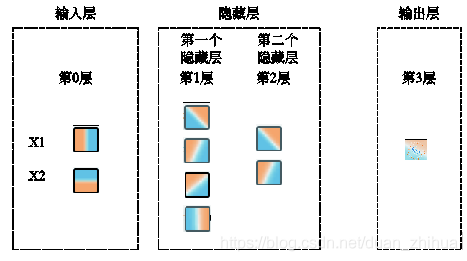
- 第12~20行代码:设置和访问神经元全局唯一的ID,完成身份的设置。图2-13中输入层的X1、X2等输入节点有自己的ID,第一层隐藏层的神经元(4个节点)有自己的ID,第二层隐藏层神经元(2个节点)有自己的ID,输出层的节点也有自己的ID。
- 第22~29行代码:设置和访问神经元的名称。神经元除了节点的ID和网络层次以外,还需设置一个节点名称。ID是一个数字,就像是节点的身份证号,label就是节点的名称。
- 第31~38行代码:判断当前的神经元是否是一个偏爱因子,这是神经元除了节点的ID、网络层次、名称以外,还需考虑的内容。因为我们是面向对象的实现,在神经网络中有一个偏爱因子对象,偏爱因子也是一个实体,我们在判断神经元的时候,在最开始的时候有必要判断是偏爱因子还是具体的特征,所以一个很重要的步骤,就是要判断一下元素是神经元本身还是偏爱因子。
- 第33行在set_is_bias_unit方法中传入一个参数is_bias_unit,is_bias_unit是一个布尔值,判断是不是偏爱因子,如图所示。

这样最简单的神经网络的神经元节点就构建起来了。注意:这里的节点有两种类型,一种是神经元,一种是偏爱因子。
下一步的工作是创建神经网络的结构,从面向对象编程的角度,创建神经网络结构的工作放在service中,我们创建一个service的文件夹,在service的文件夹中创建一个业务类NetworkStructure.py,在NetworkStructure.py中实现神经网络的结构逻辑。
chapter2_Create_AI_Framework版本的NetworkStructure.py(v1)的源代码如下:
1. # -*- coding: utf-8 -*-
2.
3. #导入要使用的Node类
4. from entity.Node import Node
5. class NetworkStructure:
6.
7. #创建整个神经网络的所有节点
8. def create_nodes(num_of_features, hidden_layers):
9. nodes = []
10. nodeIndex = 0 #神经元的ID
11.
12. #输入层
13. #偏爱因子节点
14.
15. node = Node()
16.
17. node.set_index(nodeIndex)
18. node.set_label("+1")
19. node.set_is_bias_unit(True)
20. nodes.append(node)
21. nodeIndex = nodeIndex + 1
22.
23. print(node.get_label(), "\t", end = '')
24.
25. print("")
26.
27. #隐藏层
28. for i in range(len(hidden_layers)):
29. print("Hidden layer creation: ", end = ' ')
30.
31. #偏爱因子节点
32. node = Node()
33.
34. node.set_index(nodeIndex)
35. node.set_label("+1")
36. node.set_is_bias_unit(True)
37. nodes.append(node)
38. nodeIndex = nodeIndex + 1
39.
40. print(node.get_label(), "\t", end = '')
41.
42. #创建该层的神经元
43. for j in range(hidden_layers[i]):
44. #创建该层内部的神经元
45. node = Node()
46.
47. node.set_index(nodeIndex)
48. node.set_label("+1")
49. node.set_is_bias_unit(False)
50. nodes.append(node)
51. nodeIndex = nodeIndex + 1
52.
53. print(node.get_label(), "\t", end = '')
54.
55.
56. print("")
57.
58. #输出层
59. node = Node()
60.
61. node.set_index(nodeIndex)
62. node.set_label("Output")
63. node.set_is_bias_unit(False)
64. nodes.append(node)
65. nodeIndex = nodeIndex + 1
66. print("Output layer: ", node.get_label())
67.
68. return nodes
-
第8行代码:构建create_nodes方法。要创建神经网络首先要创建神经网络的节点,神经网络中有很多的节点,怎么判断有多少个节点?最简单的方法是先去掉隐藏层,实现输入层、输出层,之后再加上隐藏层。而输入层有多少个元素取决于有多少个特征,所以在create_nodes方法中传入的第一个参数是num_of_features,第二个参数是hidden_layers,hidden_layers可能是0个隐藏层,也可能是100个隐藏层。注意,create_nodes方法这里没有使用self参数。
第10行代码:定义nodeIndex,每个节点有自己的节点ID,神经元的ID默认从0开始,神经元的ID是全局的。 -
第12行~25行代码:构建输入层的节点。注意,因为目前还不知道输入层的数据是怎样的,因此输入层的神经元节点代码暂不好编写,从我们能够入手的角度出发,从输入层到下一层有偏爱因子,所以先创建偏爱因子,偏爱因子是一个节点。如图所示。

-
第15行代码:构建偏爱因子的节点实例。
-
第17行代码:通过set_index方法是设置偏爱因子节点的index,偏爱因子是输入层的第0个节点。
-
第18行代码:将偏爱因子节点的名称设置为“+1”。
-
第19行代码:设置偏爱因子节点的set_is_bias_unit为True,即设置为偏爱因子节点。
-
第20行代码:在创建偏爱因子节点以后,将其加入到所有节点的数组集中。
-
第21行代码:创建偏爱因子节点以后,将节点的索引号nodeIndex加1。
-
第 27~56 行代码:构建隐藏层的节点。隐藏层中既有神经元节点本身,也有偏爱因子节点,首先要看隐藏层里面有多少层,对应每一层去创建不同的节点。创建隐藏层使用2个循环,外层循环遍历神经网络有多少层,每层创建一个偏爱因子节点;内层循环构建每个隐藏层的每一个神经元节点本身。
-
第28~40行代码:外层循环构建每个隐藏层的偏爱因子节点,如图2-16所示。第35行代码设置隐藏层偏爱因子的节点名称为“+1”。第36行代码设置偏爱因子节点的set_is_bias_unit为True。
-

-
第42~53行代码:内层循环构建每个隐藏层的神经元节点本身。如图2-17所示。
-

-
第43行代码:for循环是一个内层循环,每一个隐藏层的神经元节点有多少个取决于传进来的这一层的隐藏层hidden_layers[i]有多少元个素,然后在内层循环里面创建该隐藏层内部的神经元。
-
第48行代码:设置神经元节点名称。将神经元节点的名称设置为“+1”。
-
第49行代码:设置神经元节点的set_is_bias_unit为False。因为创建的是神经元节点本身,而不是偏爱因子节点。
构建出神经网络的隐藏层,将每个隐藏层的神经元节点创建出来,每个隐藏层的偏爱因子也创建出来了。
-
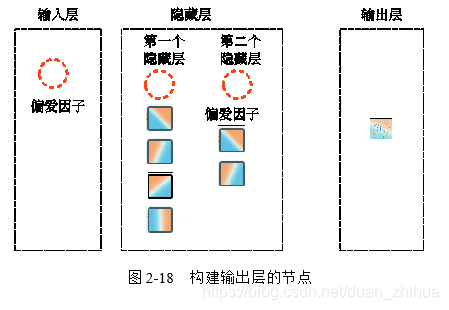
第58~66行代码:构建输出层的节点,如图2-18所示。
-
第62行代码:设置输出层节点的名称,将神经元节点命名为Output。
-
第63行代码:设置输出层节点的set_is_bias_unit为False,因为输出层的节点显然不是偏爱因子。
-
第68行代码:返回create_nodes方法构建的所有节点的结果。在create_nodes方法中创建整个神经网络的所有节点,创建一个数组节点存放所有的节点,从输入层、输出层、隐藏层三个角度来考虑,实现输入层、隐藏层、输出层不同层次的节点创建,create_nodes方法最后返回所有节点的结果。
这样就初步创建了神经网络节点。NetworkStructure.py(v1)代码中创建了输入层的偏爱因子节点、隐藏层所有的偏爱因子节点、隐藏层的所有神经元节点、输出层的节点。注意,这里还没有创建输入层的节点,后续我们将进行迭代完善,加上这部分代码。
做完这一步,下面需通过一个应用程序看一下构建节点的情况,创建一个Neuron_Network_ Entry.py 文件构建一个入口,将在Neuron_Network_Entry.py文件调用构建神经网络Network¬Structure.py的方法。
chapter2_Create_AI_Framework的Neuron_Network_Entry.py(v1)的源代码如下:
1. # -*- coding: utf-8 -*-
2. from service.NetworkStructure import NetworkStructure
3. from service.NetworkConnection import NetworkConnection
4. #from entity.Node import Node
5. #Exclusive OR: 只有第一个元素和第二个元素不同的时候,结果才是1,否则为0
6. instances = [[0,0,0],
7. [0,1,1],
8. [1,0,1],
9. [1,1,0]]
10.
11. num_of_features = len(instances[0]) - 1 #在这里只有第一列和第二列是特征,第三
#列是根据某种关系得出的结果
12.
13. hidden_layers = [4,2] #这里硬代码为2个隐藏层,第一个隐藏层有4个神经元,第二个
#隐藏层有2个神经元
14. #hidden_layers = [8,4,2]
15. nodes = NetworkStructure.create_nodes(num_of_features,hidden_layers)
16. ......
- 第6~9行代码:构建输入数据。为了方便读者学习,这里使用二维数组硬编码,二维数组的第一行成员是[0,0,0],第二个成员是[0,1,1],第三个成员是[1,0,1],第四个成员是[1,1,0]。二维数组有4行3列,观察发现,二维数组的四行成员,它的第一列、第二列数字如果不同,第三列为1;第一列、第二列数字如果相同,第三列为0,其实就是逻辑运算中的异或操作(Exclusive OR),机器学习可以通过这个规律预测数据是0还是1,这里的数据只有2列,当然也可以是200列,可从数据中关联出某种关系,基于这种关系推断出结果是0还是1。第1列和第2列是2个特征,第3列是结果。
- 第11行代码:设置输入特征数。输入数据中有多少个输入特征?这里是除了结果列的其他列的列数。实例instances的第0行的长度是3,但是它的特征是2个,第一列和第二列是特征,第三列是根据某种关系(数学公式或者某种运算法则)得出的结果。
第13行代码:设置隐藏层每一层的神经元节点数,[4,2]表示第一层隐藏层的神经元有4个节点,第二层隐藏层神经元有2个节点。
第15行代码:调用NetworkStructure的create_nodes方法,传入的第一个参数为输入特征数,传入的第二个参数为隐藏层每一层的神经元节点数列表。Python带self与不带self在调用时的区别为:没有加self是静态方法,可以直接调用;如果加上self,必须先创建一个实例,然后调用。
(1)带self,要创建一个实例来调用方法。例如:
class Node:
def set_index(self,index):
self._index = index
......
node = Node()
node.set_index(nodeIndex)
(2)不带self,直接调用这个方法。例如:
class NetworkStructure:
def create_nodes(num_of_features,hidden_nodes):
......
#可以直接调用:
nodes = NetworkStructure.create_nodes(num_of_features,hidden_nodes)
在Spyder中使用快捷键Ctrl + A全选Neuron_Network_Entry.py的代码,然后使用快捷键Shift + Enter运行代码,在Spyder的界面中会显示相应的结果。
在hidden_layers = [4,2]的情况下,Neuron_Network_Entry.py的运行结果如下。简单的创建神经元网络节点的代码运行成功。这里创建了2个隐藏层,第1个隐藏层有4个元素,第2个隐藏层有2个元素。运行结果第一行中的第一个“+1”表示输入层的偏爱因子节点的名字,“Hidden layer creation:”字符串之后的第一个“+1”表示第一个隐藏层的偏爱因子节点的名字,其后的4个“+1”分别表示第一个隐藏层的4个神经元,其中第4个“+1”显示时落到了第二行;运行结果第二行中的“Hidden layer creation:”字符串之后的第一个“+1”表示第二个隐藏层的偏爱节点的名字,其后的2个“+1”分别表示第二个隐藏层的2个神经元。在运行结果的第三行打印输出层的节点名字Output。
+1 Hidden layer creation: +1 +1 +1 +1
+1 Hidden layer creation: +1 +1 +1
Output layer: Output
在hidden_layers = [4]的情况下,只有1个隐藏层,第1个隐藏层有4个神经元的情况下,Neuron_Network_Entry.py的运行结果如下。第一行中的第一个“+1”表示输入层的偏爱因子节点的名字,“Hidden layer creation:”字符串之后的第一个“+1”表示第一个隐藏层的偏爱因子节点的名字,其后的4个“+1”分别表示第一个隐藏层的4个神经元,其中第4个“+1”显示时落到了第二行;在运行结果的第二行打印输出层的节点名字Output。
+1 Hidden layer creation: +1 +1 +1 +1
+1 Output layer: Output
为了更清晰地显示运行结果,接下来进行输出结果的格式化。将 chapter2_Create_AI_ Framework版本的NetworkStructure.py的程序另存为NetworkStructure.py(v1)并修改相关行的代码:
(1)调整NetworkStructure.py(v1)代码中第35行的节点名字,将偏爱因子节点的名字从“+1”修改为i+1。
(2)调整NetworkStructure.py(v1)代码中第48行的节点名字,我们要访问具体的神经元节点本身,要在神经元节点名称中凸显这个节点在什么位置,具体获取神经元节点处于哪一层,及处在这一层中的第几个元素,通过N[i][j]的方式命名。
......
node.set_label(i+1)
......
node.set_label("N[" + str(i+1) + "][" + str(j + 1) + "]")
......
格式化输出以后的运行结果如下。在hidden_layers = [4,2]时,运行结果第一行中的第一个“+1”表示输入层的偏爱因子的节点名字;第二行“Hidden layer creation:”后的1是第1层隐藏层的偏爱因子的名字,之后是第一个隐藏层的4个神经元节点的名字;第三行“Hidden layer creation:”后的2是第2层隐藏层的偏爱因子的名字,之后是第2个隐藏层的2个神经元节点的名字。第四行打印输出层的节点名字Output。
+1
Hidden layer creation: 1 N[1][1] N[1][2] N[1][3]
N[1][4] Hidden layer creation: 2 N[2][1] N[2][2]
Output layer: Output
新书预发布

本书以自己开发盘古人工智能框架为基石,以人工智能实战案例为核心,透彻剖析分布式内存管理系统Alluxio,分为盘古人工智能框架开发专题篇、机器学习案例实战篇、分布式内存管理系统Alluxio解密篇,分别对人工智能自研框架、机器学习案例及Alluxio进行透彻解析。
盘古人工智能框架开发专题篇,通过图文并茂、深入浅出的讲解,带领读者一行一行地编写代码,自己动手实现人工智能深度学习框架中的多个算法,包括多层次神经网络、前向传播算法、反向传播算法、损失度的计算及可视化,自适应学习和特征归一化优化等。
机器学习案例实战篇,选取机器学习中最具代表的经典案例,透彻讲解机器学习数据预处理、简单线性回归、多元线性回归、多项式回归、支持向量回归、决策树回归、随机森林回归等回归算法,逻辑回归、k近邻算法、支持向量机、朴素贝叶斯、决策树分类、随机森林分类等分类算法,k-均值聚类、层次聚类等聚类算法,以及关联分析算法,并分别对回归模型、分类模型进行性能评估。
分布式内存管理系统Alluxio解密篇,详细讲解Alluxio架构、部署、底层存储及计算应用、基本用法、运行维护等内容。
本书适合机器学习、人工智能及大数据学习者和从业人员使用。对于有分布式计算框架应用经验的人员,本书也可作为Spark+AI+Alluxio高手修炼的参考书。同时,本书也适合高等院校作为大数据教材使用。
新书 前 言
2016年3月,阿尔法狗击败了我们这个星球上最出色的围棋选手,其特殊之处在于阿尔法狗下围棋时使用了一种设计人员没有想到的策略,这是人工智能里程碑式的胜利。
2017年7月,国务院正式发布《新一代人工智能发展规划》,明确把人工智能发展作为国家战略。人工智能是21世纪的三大尖端技术(基因工程、纳米工程、人工智能)之一。国务院发布人工智能分三步走的规划中指出:到2030年,中国的人工智能理论、技术与应用总体达到世界领先水平,成为世界主要人工智能创新中心,智能经济、智能社会取得明显成效,为跻身创新型国家前列和经济强国奠定重要基础。
如何驾驭人工智能时代的技术?如何掌握人工智能各种具体的实战技术?如何使用统一内存技术驾驭任意类型的数据?本书基于实践尝试给予这些问题答案。
- 盘古人工智能框架开发专题篇,包含1~16章,以图文并茂的形式,带领读者一行一行地编写代码来实现当今主流深度学习框架的核心技术,通过实践解密PyTorch和TensorFlow等最流行技术背后的设计和实现,并讲解深度学习框架在电信运营方面的应用案例。
- 机器学习案例实战篇,包含17~35章,选取机器学习开发中最具代表性的经典学习案例,透彻讲解机器学习数据预处理,简单线性回归、多元线性回归、多项式回归、支持向量回归、决策树回归、随机森林回归等回归算法,逻辑回归、k近邻算法、支持向量机、朴素贝叶斯、决策树分类、随机森林分类等分类算法,k-均值聚类、层次聚类等聚类算法,以及关联分析算法,并分别对回归模型、分类模型进行性能评估。
- 分布式内存管理系统Alluxio解密篇,包含36~40章,详细讲解Alluxio架构、部署、底层存储及计算应用、基本用法、运行维护等内容。
基于美国最流行的Heuristic learning(启发式学习)理念,本书所有的内容都是按照具体的问题场景、核心原理、解决方案的顺序组织而成,所有的内容均以动手实践的方式一步步驱动学习者流畅地完成,带来无痛苦的学习体验。
读者在阅读本书的过程中,如发现任何问题或有任何疑问,可以加入本书的阅读群(QQ:418110145)讨论,会有专人答疑。同时,该群也会提供本书所用案例源代码及本书的配套学习视频。笔者的新浪微博是http://weibo.com/ilovepains/,欢迎大家在微博上与我交流。
由于时间仓促,书中难免存在不妥之处,请读者谅解,并提出宝贵意见。
王家林
2019年中秋之夜于美国硅谷