storm配置:设置worker进程内存大小
Storm中真正干活的是各个worker,而worker由supervisor负责启动。在topology启动过程中我们会看到如下的启动日志:
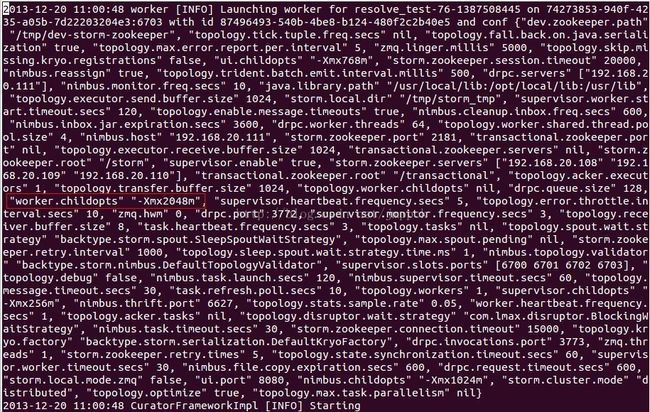
这就是启动一个worker进程,也就是一个JVM进程。
默认情况下,Storm启动worker进程时,JVM的最大内存是768M。
但我在使用过程中,由于会在Bolt中加载大量数据,768M内存无法满足需求,会导致内存溢出程序崩溃。
经过研究发现,可以通过在Strom的配置文件storm.yaml中设置worker的启动参数:
worker.childopts: "-Xmx2048m"目前好像Storm还没有配置文件的详细说明,比如可以配置哪些参数,怎么配置?
大家可以先参考Storm源代码中的Config.java.
package backtype.storm;
import backtype.storm.ConfigValidation;
import backtype.storm.serialization.IKryoDecorator;
import backtype.storm.serialization.IKryoFactory;
import com.esotericsoftware.kryo.Serializer;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Topology configs are specified as a plain old map. This class provides a
* convenient way to create a topology config map by providing setter methods for
* all the configs that can be set. It also makes it easier to do things like add
* serializations.
*
* This class also provides constants for all the configurations possible on
* a Storm cluster and Storm topology. Each constant is paired with a schema
* that defines the validity criterion of the corresponding field. Default
* values for these configs can be found in defaults.yaml.
*
* Note that you may put other configurations in any of the configs. Storm
* will ignore anything it doesn't recognize, but your topologies are free to make
* use of them by reading them in the prepare method of Bolts or the open method of
* Spouts.
*/
public class Config extends HashMap {
/**
* The transporter for communication among Storm tasks
*/
public static final String STORM_MESSAGING_TRANSPORT = "storm.messaging.transport";
public static final Object STORM_MESSAGING_TRANSPORT_SCHEMA = String.class;
/**
* Netty based messaging: The buffer size for send/recv buffer
*/
public static final String STORM_MESSAGING_NETTY_BUFFER_SIZE = "storm.messaging.netty.buffer_size";
public static final Object STORM_MESSAGING_NETTY_BUFFER_SIZE_SCHEMA = Number.class;
/**
* Netty based messaging: The max # of retries that a peer will perform when a remote is not accessible
*/
public static final String STORM_MESSAGING_NETTY_MAX_RETRIES = "storm.messaging.netty.max_retries";
public static final Object STORM_MESSAGING_NETTY_MAX_RETRIES_SCHEMA = Number.class;
/**
* Netty based messaging: The min # of milliseconds that a peer will wait.
*/
public static final String STORM_MESSAGING_NETTY_MIN_SLEEP_MS = "storm.messaging.netty.min_wait_ms";
public static final Object STORM_MESSAGING_NETTY_MIN_SLEEP_MS_SCHEMA = Number.class;
/**
* Netty based messaging: The max # of milliseconds that a peer will wait.
*/
public static final String STORM_MESSAGING_NETTY_MAX_SLEEP_MS = "storm.messaging.netty.max_wait_ms";
public static final Object STORM_MESSAGING_NETTY_MAX_SLEEP_MS_SCHEMA = Number.class;
/**
* Netty based messaging: The # of worker threads for the server.
*/
public static final String STORM_MESSAGING_NETTY_SERVER_WORKER_THREADS = "storm.messaging.netty.server_worker_threads";
public static final Object STORM_MESSAGING_NETTY_SERVER_WORKER_THREADS_SCHEMA = Number.class;
/**
* Netty based messaging: The # of worker threads for the client.
*/
public static final String STORM_MESSAGING_NETTY_CLIENT_WORKER_THREADS = "storm.messaging.netty.client_worker_threads";
public static final Object STORM_MESSAGING_NETTY_CLIENT_WORKER_THREADS_SCHEMA = Number.class;
/**
* A list of hosts of ZooKeeper servers used to manage the cluster.
*/
public static final String STORM_ZOOKEEPER_SERVERS = "storm.zookeeper.servers";
public static final Object STORM_ZOOKEEPER_SERVERS_SCHEMA = ConfigValidation.StringsValidator;
/**
* The port Storm will use to connect to each of the ZooKeeper servers.
*/
public static final String STORM_ZOOKEEPER_PORT = "storm.zookeeper.port";
public static final Object STORM_ZOOKEEPER_PORT_SCHEMA = Number.class;
/**
* A directory on the local filesystem used by Storm for any local
* filesystem usage it needs. The directory must exist and the Storm daemons must
* have permission to read/write from this location.
*/
public static final String STORM_LOCAL_DIR = "storm.local.dir";
public static final Object STORM_LOCAL_DIR_SCHEMA = String.class;
/**
* A global task scheduler used to assign topologies's tasks to supervisors' wokers.
*
* If this is not set, a default system scheduler will be used.
*/
public static final String STORM_SCHEDULER = "storm.scheduler";
public static final Object STORM_SCHEDULER_SCHEMA = String.class;
/**
* The mode this Storm cluster is running in. Either "distributed" or "local".
*/
public static final String STORM_CLUSTER_MODE = "storm.cluster.mode";
public static final Object STORM_CLUSTER_MODE_SCHEMA = String.class;
/**
* The hostname the supervisors/workers should report to nimbus. If unset, Storm will
* get the hostname to report by calling InetAddress.getLocalHost().getCanonicalHostName().
*
* You should set this config when you dont have a DNS which supervisors/workers
* can utilize to find each other based on hostname got from calls to
* InetAddress.getLocalHost().getCanonicalHostName().
*/
public static final String STORM_LOCAL_HOSTNAME = "storm.local.hostname";
public static final Object STORM_LOCAL_HOSTNAME_SCHEMA = String.class;
/**
* The transport plug-in for Thrift client/server communication
*/
public static final String STORM_THRIFT_TRANSPORT_PLUGIN = "storm.thrift.transport";
public static final Object STORM_THRIFT_TRANSPORT_PLUGIN_SCHEMA = String.class;
/**
* The serializer class for ListDelegate (tuple payload).
* The default serializer will be ListDelegateSerializer
*/
public static final String TOPOLOGY_TUPLE_SERIALIZER = "topology.tuple.serializer";
public static final Object TOPOLOGY_TUPLE_SERIALIZER_SCHEMA = String.class;
/**
* Whether or not to use ZeroMQ for messaging in local mode. If this is set
* to false, then Storm will use a pure-Java messaging system. The purpose
* of this flag is to make it easy to run Storm in local mode by eliminating
* the need for native dependencies, which can be difficult to install.
*
* Defaults to false.
*/
public static final String STORM_LOCAL_MODE_ZMQ = "storm.local.mode.zmq";
public static final Object STORM_LOCAL_MODE_ZMQ_SCHEMA = Boolean.class;
/**
* The root location at which Storm stores data in ZooKeeper.
*/
public static final String STORM_ZOOKEEPER_ROOT = "storm.zookeeper.root";
public static final Object STORM_ZOOKEEPER_ROOT_SCHEMA = String.class;
/**
* The session timeout for clients to ZooKeeper.
*/
public static final String STORM_ZOOKEEPER_SESSION_TIMEOUT = "storm.zookeeper.session.timeout";
public static final Object STORM_ZOOKEEPER_SESSION_TIMEOUT_SCHEMA = Number.class;
/**
* The connection timeout for clients to ZooKeeper.
*/
public static final String STORM_ZOOKEEPER_CONNECTION_TIMEOUT = "storm.zookeeper.connection.timeout";
public static final Object STORM_ZOOKEEPER_CONNECTION_TIMEOUT_SCHEMA = Number.class;
/**
* The number of times to retry a Zookeeper operation.
*/
public static final String STORM_ZOOKEEPER_RETRY_TIMES="storm.zookeeper.retry.times";
public static final Object STORM_ZOOKEEPER_RETRY_TIMES_SCHEMA = Number.class;
/**
* The interval between retries of a Zookeeper operation.
*/
public static final String STORM_ZOOKEEPER_RETRY_INTERVAL="storm.zookeeper.retry.interval";
public static final Object STORM_ZOOKEEPER_RETRY_INTERVAL_SCHEMA = Number.class;
/**
* The ceiling of the interval between retries of a Zookeeper operation.
*/
public static final String STORM_ZOOKEEPER_RETRY_INTERVAL_CEILING="storm.zookeeper.retry.intervalceiling.millis";
public static final Object STORM_ZOOKEEPER_RETRY_INTERVAL_CEILING_SCHEMA = Number.class;
/**
* The Zookeeper authentication scheme to use, e.g. "digest". Defaults to no authentication.
*/
public static final String STORM_ZOOKEEPER_AUTH_SCHEME="storm.zookeeper.auth.scheme";
public static final Object STORM_ZOOKEEPER_AUTH_SCHEME_SCHEMA = String.class;
/**
* A string representing the payload for Zookeeper authentication. It gets serialized using UTF-8 encoding during authentication.
*/
public static final String STORM_ZOOKEEPER_AUTH_PAYLOAD="storm.zookeeper.auth.payload";
public static final Object STORM_ZOOKEEPER_AUTH_PAYLOAD_SCHEMA = String.class;
/**
* The id assigned to a running topology. The id is the storm name with a unique nonce appended.
*/
public static final String STORM_ID = "storm.id";
public static final Object STORM_ID_SCHEMA = String.class;
/**
* The host that the master server is running on.
*/
public static final String NIMBUS_HOST = "nimbus.host";
public static final Object NIMBUS_HOST_SCHEMA = String.class;
/**
* Which port the Thrift interface of Nimbus should run on. Clients should
* connect to this port to upload jars and submit topologies.
*/
public static final String NIMBUS_THRIFT_PORT = "nimbus.thrift.port";
public static final Object NIMBUS_THRIFT_PORT_SCHEMA = Number.class;
/**
* This parameter is used by the storm-deploy project to configure the
* jvm options for the nimbus daemon.
*/
public static final String NIMBUS_CHILDOPTS = "nimbus.childopts";
public static final Object NIMBUS_CHILDOPTS_SCHEMA = String.class;
/**
* How long without heartbeating a task can go before nimbus will consider the
* task dead and reassign it to another location.
*/
public static final String NIMBUS_TASK_TIMEOUT_SECS = "nimbus.task.timeout.secs";
public static final Object NIMBUS_TASK_TIMEOUT_SECS_SCHEMA = Number.class;
/**
* How often nimbus should wake up to check heartbeats and do reassignments. Note
* that if a machine ever goes down Nimbus will immediately wake up and take action.
* This parameter is for checking for failures when there's no explicit event like that
* occuring.
*/
public static final String NIMBUS_MONITOR_FREQ_SECS = "nimbus.monitor.freq.secs";
public static final Object NIMBUS_MONITOR_FREQ_SECS_SCHEMA = Number.class;
/**
* How often nimbus should wake the cleanup thread to clean the inbox.
* @see NIMBUS_INBOX_JAR_EXPIRATION_SECS
*/
public static final String NIMBUS_CLEANUP_INBOX_FREQ_SECS = "nimbus.cleanup.inbox.freq.secs";
public static final Object NIMBUS_CLEANUP_INBOX_FREQ_SECS_SCHEMA = Number.class;
/**
* The length of time a jar file lives in the inbox before being deleted by the cleanup thread.
*
* Probably keep this value greater than or equal to NIMBUS_CLEANUP_INBOX_JAR_EXPIRATION_SECS.
* Note that the time it takes to delete an inbox jar file is going to be somewhat more than
* NIMBUS_CLEANUP_INBOX_JAR_EXPIRATION_SECS (depending on how often NIMBUS_CLEANUP_FREQ_SECS
* is set to).
* @see NIMBUS_CLEANUP_FREQ_SECS
*/
public static final String NIMBUS_INBOX_JAR_EXPIRATION_SECS = "nimbus.inbox.jar.expiration.secs";
public static final Object NIMBUS_INBOX_JAR_EXPIRATION_SECS_SCHEMA = Number.class;
/**
* How long before a supervisor can go without heartbeating before nimbus considers it dead
* and stops assigning new work to it.
*/
public static final String NIMBUS_SUPERVISOR_TIMEOUT_SECS = "nimbus.supervisor.timeout.secs";
public static final Object NIMBUS_SUPERVISOR_TIMEOUT_SECS_SCHEMA = Number.class;
/**
* A special timeout used when a task is initially launched. During launch, this is the timeout
* used until the first heartbeat, overriding nimbus.task.timeout.secs.
*
* A separate timeout exists for launch because there can be quite a bit of overhead
* to launching new JVM's and configuring them.
*/
public static final String NIMBUS_TASK_LAUNCH_SECS = "nimbus.task.launch.secs";
public static final Object NIMBUS_TASK_LAUNCH_SECS_SCHEMA = Number.class;
/**
* Whether or not nimbus should reassign tasks if it detects that a task goes down.
* Defaults to true, and it's not recommended to change this value.
*/
public static final String NIMBUS_REASSIGN = "nimbus.reassign";
public static final Object NIMBUS_REASSIGN_SCHEMA = Boolean.class;
/**
* During upload/download with the master, how long an upload or download connection is idle
* before nimbus considers it dead and drops the connection.
*/
public static final String NIMBUS_FILE_COPY_EXPIRATION_SECS = "nimbus.file.copy.expiration.secs";
public static final Object NIMBUS_FILE_COPY_EXPIRATION_SECS_SCHEMA = Number.class;
/**
* A custom class that implements ITopologyValidator that is run whenever a
* topology is submitted. Can be used to provide business-specific logic for
* whether topologies are allowed to run or not.
*/
public static final String NIMBUS_TOPOLOGY_VALIDATOR = "nimbus.topology.validator";
public static final Object NIMBUS_TOPOLOGY_VALIDATOR_SCHEMA = String.class;
/**
* Class name for authorization plugin for Nimbus
*/
public static final String NIMBUS_AUTHORIZER = "nimbus.authorizer";
public static final Object NIMBUS_AUTHORIZER_SCHEMA = String.class;
/**
* Storm UI binds to this port.
*/
public static final String UI_PORT = "ui.port";
public static final Object UI_PORT_SCHEMA = Number.class;
/**
* HTTP UI port for log viewer
*/
public static final String LOGVIEWER_PORT = "logviewer.port";
public static final Object LOGVIEWER_PORT_SCHEMA = Number.class;
/**
* Childopts for log viewer java process.
*/
public static final String LOGVIEWER_CHILDOPTS = "logviewer.childopts";
public static final Object LOGVIEWER_CHILDOPTS_SCHEMA = String.class;
/**
* Appender name used by log viewer to determine log directory.
*/
public static final String LOGVIEWER_APPENDER_NAME = "logviewer.appender.name";
public static final Object LOGVIEWER_APPENDER_NAME_SCHEMA = String.class;
/**
* Childopts for Storm UI Java process.
*/
public static final String UI_CHILDOPTS = "ui.childopts";
public static final Object UI_CHILDOPTS_SCHEMA = String.class;
/**
* List of DRPC servers so that the DRPCSpout knows who to talk to.
*/
public static final String DRPC_SERVERS = "drpc.servers";
public static final Object DRPC_SERVERS_SCHEMA = ConfigValidation.StringsValidator;
/**
* This port is used by Storm DRPC for receiving DPRC requests from clients.
*/
public static final String DRPC_PORT = "drpc.port";
public static final Object DRPC_PORT_SCHEMA = Number.class;
/**
* DRPC thrift server worker threads
*/
public static final String DRPC_WORKER_THREADS = "drpc.worker.threads";
public static final Object DRPC_WORKER_THREADS_SCHEMA = Number.class;
/**
* DRPC thrift server queue size
*/
public static final String DRPC_QUEUE_SIZE = "drpc.queue.size";
public static final Object DRPC_QUEUE_SIZE_SCHEMA = Number.class;
/**
* This port on Storm DRPC is used by DRPC topologies to receive function invocations and send results back.
*/
public static final String DRPC_INVOCATIONS_PORT = "drpc.invocations.port";
public static final Object DRPC_INVOCATIONS_PORT_SCHEMA = Number.class;
/**
* The timeout on DRPC requests within the DRPC server. Defaults to 10 minutes. Note that requests can also
* timeout based on the socket timeout on the DRPC client, and separately based on the topology message
* timeout for the topology implementing the DRPC function.
*/
public static final String DRPC_REQUEST_TIMEOUT_SECS = "drpc.request.timeout.secs";
public static final Object DRPC_REQUEST_TIMEOUT_SECS_SCHEMA = Number.class;
/**
* Childopts for Storm DRPC Java process.
*/
public static final String DRPC_CHILDOPTS = "drpc.childopts";
public static final Object DRPC_CHILDOPTS_SCHEMA = String.class;
/**
* the metadata configed on the supervisor
*/
public static final String SUPERVISOR_SCHEDULER_META = "supervisor.scheduler.meta";
public static final Object SUPERVISOR_SCHEDULER_META_SCHEMA = Map.class;
/**
* A list of ports that can run workers on this supervisor. Each worker uses one port, and
* the supervisor will only run one worker per port. Use this configuration to tune
* how many workers run on each machine.
*/
public static final String SUPERVISOR_SLOTS_PORTS = "supervisor.slots.ports";
public static final Object SUPERVISOR_SLOTS_PORTS_SCHEMA = ConfigValidation.NumbersValidator;
/**
* This parameter is used by the storm-deploy project to configure the
* jvm options for the supervisor daemon.
*/
public static final String SUPERVISOR_CHILDOPTS = "supervisor.childopts";
public static final Object SUPERVISOR_CHILDOPTS_SCHEMA = String.class;
/**
* How long a worker can go without heartbeating before the supervisor tries to
* restart the worker process.
*/
public static final String SUPERVISOR_WORKER_TIMEOUT_SECS = "supervisor.worker.timeout.secs";
public static final Object SUPERVISOR_WORKER_TIMEOUT_SECS_SCHEMA = Number.class;
/**
* How long a worker can go without heartbeating during the initial launch before
* the supervisor tries to restart the worker process. This value override
* supervisor.worker.timeout.secs during launch because there is additional
* overhead to starting and configuring the JVM on launch.
*/
public static final String SUPERVISOR_WORKER_START_TIMEOUT_SECS = "supervisor.worker.start.timeout.secs";
public static final Object SUPERVISOR_WORKER_START_TIMEOUT_SECS_SCHEMA = Number.class;
/**
* Whether or not the supervisor should launch workers assigned to it. Defaults
* to true -- and you should probably never change this value. This configuration
* is used in the Storm unit tests.
*/
public static final String SUPERVISOR_ENABLE = "supervisor.enable";
public static final Object SUPERVISOR_ENABLE_SCHEMA = Boolean.class;
/**
* how often the supervisor sends a heartbeat to the master.
*/
public static final String SUPERVISOR_HEARTBEAT_FREQUENCY_SECS = "supervisor.heartbeat.frequency.secs";
public static final Object SUPERVISOR_HEARTBEAT_FREQUENCY_SECS_SCHEMA = Number.class;
/**
* How often the supervisor checks the worker heartbeats to see if any of them
* need to be restarted.
*/
public static final String SUPERVISOR_MONITOR_FREQUENCY_SECS = "supervisor.monitor.frequency.secs";
public static final Object SUPERVISOR_MONITOR_FREQUENCY_SECS_SCHEMA = Number.class;
/**
* The jvm opts provided to workers launched by this supervisor. All "%ID%" substrings are replaced
* with an identifier for this worker.
*/
public static final String WORKER_CHILDOPTS = "worker.childopts";
public static final Object WORKER_CHILDOPTS_SCHEMA = String.class;
/**
* How often this worker should heartbeat to the supervisor.
*/
public static final String WORKER_HEARTBEAT_FREQUENCY_SECS = "worker.heartbeat.frequency.secs";
public static final Object WORKER_HEARTBEAT_FREQUENCY_SECS_SCHEMA = Number.class;
/**
* How often a task should heartbeat its status to the master.
*/
public static final String TASK_HEARTBEAT_FREQUENCY_SECS = "task.heartbeat.frequency.secs";
public static final Object TASK_HEARTBEAT_FREQUENCY_SECS_SCHEMA = Number.class;
/**
* How often a task should sync its connections with other tasks (if a task is
* reassigned, the other tasks sending messages to it need to refresh their connections).
* In general though, when a reassignment happens other tasks will be notified
* almost immediately. This configuration is here just in case that notification doesn't
* come through.
*/
public static final String TASK_REFRESH_POLL_SECS = "task.refresh.poll.secs";
public static final Object TASK_REFRESH_POLL_SECS_SCHEMA = Number.class;
/**
* True if Storm should timeout messages or not. Defaults to true. This is meant to be used
* in unit tests to prevent tuples from being accidentally timed out during the test.
*/
public static final String TOPOLOGY_ENABLE_MESSAGE_TIMEOUTS = "topology.enable.message.timeouts";
public static final Object TOPOLOGY_ENABLE_MESSAGE_TIMEOUTS_SCHEMA = Boolean.class;
/**
* When set to true, Storm will log every message that's emitted.
*/
public static final String TOPOLOGY_DEBUG = "topology.debug";
public static final Object TOPOLOGY_DEBUG_SCHEMA = Boolean.class;
/**
* Whether or not the master should optimize topologies by running multiple
* tasks in a single thread where appropriate.
*/
public static final String TOPOLOGY_OPTIMIZE = "topology.optimize";
public static final Object TOPOLOGY_OPTIMIZE_SCHEMA = Boolean.class;
/**
* How many processes should be spawned around the cluster to execute this
* topology. Each process will execute some number of tasks as threads within
* them. This parameter should be used in conjunction with the parallelism hints
* on each component in the topology to tune the performance of a topology.
*/
public static final String TOPOLOGY_WORKERS = "topology.workers";
public static final Object TOPOLOGY_WORKERS_SCHEMA = Number.class;
/**
* How many instances to create for a spout/bolt. A task runs on a thread with zero or more
* other tasks for the same spout/bolt. The number of tasks for a spout/bolt is always
* the same throughout the lifetime of a topology, but the number of executors (threads) for
* a spout/bolt can change over time. This allows a topology to scale to more or less resources
* without redeploying the topology or violating the constraints of Storm (such as a fields grouping
* guaranteeing that the same value goes to the same task).
*/
public static final String TOPOLOGY_TASKS = "topology.tasks";
public static final Object TOPOLOGY_TASKS_SCHEMA = Number.class;
/**
* How many executors to spawn for ackers.
*
* If this is set to 0, then Storm will immediately ack tuples as soon
* as they come off the spout, effectively disabling reliability.
*/
public static final String TOPOLOGY_ACKER_EXECUTORS = "topology.acker.executors";
public static final Object TOPOLOGY_ACKER_EXECUTORS_SCHEMA = Number.class;
/**
* The maximum amount of time given to the topology to fully process a message
* emitted by a spout. If the message is not acked within this time frame, Storm
* will fail the message on the spout. Some spouts implementations will then replay
* the message at a later time.
*/
public static final String TOPOLOGY_MESSAGE_TIMEOUT_SECS = "topology.message.timeout.secs";
public static final Object TOPOLOGY_MESSAGE_TIMEOUT_SECS_SCHEMA = Number.class;
/**
* A list of serialization registrations for Kryo ( http://code.google.com/p/kryo/ ),
* the underlying serialization framework for Storm. A serialization can either
* be the name of a class (in which case Kryo will automatically create a serializer for the class
* that saves all the object's fields), or an implementation of com.esotericsoftware.kryo.Serializer.
*
* See Kryo's documentation for more information about writing custom serializers.
*/
public static final String TOPOLOGY_KRYO_REGISTER = "topology.kryo.register";
public static final Object TOPOLOGY_KRYO_REGISTER_SCHEMA = ConfigValidation.StringsValidator;
/**
* A list of classes that customize storm's kryo instance during start-up.
* Each listed class name must implement IKryoDecorator. During start-up the
* listed class is instantiated with 0 arguments, then its 'decorate' method
* is called with storm's kryo instance as the only argument.
*/
public static final String TOPOLOGY_KRYO_DECORATORS = "topology.kryo.decorators";
public static final Object TOPOLOGY_KRYO_DECORATORS_SCHEMA = ConfigValidation.StringsValidator;
/**
* Class that specifies how to create a Kryo instance for serialization. Storm will then apply
* topology.kryo.register and topology.kryo.decorators on top of this. The default implementation
* implements topology.fall.back.on.java.serialization and turns references off.
*/
public static final String TOPOLOGY_KRYO_FACTORY = "topology.kryo.factory";
public static final Object TOPOLOGY_KRYO_FACTORY_SCHEMA = String.class;
/**
* Whether or not Storm should skip the loading of kryo registrations for which it
* does not know the class or have the serializer implementation. Otherwise, the task will
* fail to load and will throw an error at runtime. The use case of this is if you want to
* declare your serializations on the storm.yaml files on the cluster rather than every single
* time you submit a topology. Different applications may use different serializations and so
* a single application may not have the code for the other serializers used by other apps.
* By setting this config to true, Storm will ignore that it doesn't have those other serializations
* rather than throw an error.
*/
public static final String TOPOLOGY_SKIP_MISSING_KRYO_REGISTRATIONS= "topology.skip.missing.kryo.registrations";
public static final Object TOPOLOGY_SKIP_MISSING_KRYO_REGISTRATIONS_SCHEMA = Boolean.class;
/*
* A list of classes implementing IMetricsConsumer (See storm.yaml.example for exact config format).
* Each listed class will be routed all the metrics data generated by the storm metrics API.
* Each listed class maps 1:1 to a system bolt named __metrics_ClassName#N, and it's parallelism is configurable.
*/
public static final String TOPOLOGY_METRICS_CONSUMER_REGISTER = "topology.metrics.consumer.register";
public static final Object TOPOLOGY_METRICS_CONSUMER_REGISTER_SCHEMA = ConfigValidation.MapsValidator;
/**
* The maximum parallelism allowed for a component in this topology. This configuration is
* typically used in testing to limit the number of threads spawned in local mode.
*/
public static final String TOPOLOGY_MAX_TASK_PARALLELISM="topology.max.task.parallelism";
public static final Object TOPOLOGY_MAX_TASK_PARALLELISM_SCHEMA = Number.class;
/**
* The maximum number of tuples that can be pending on a spout task at any given time.
* This config applies to individual tasks, not to spouts or topologies as a whole.
*
* A pending tuple is one that has been emitted from a spout but has not been acked or failed yet.
* Note that this config parameter has no effect for unreliable spouts that don't tag
* their tuples with a message id.
*/
public static final String TOPOLOGY_MAX_SPOUT_PENDING="topology.max.spout.pending";
public static final Object TOPOLOGY_MAX_SPOUT_PENDING_SCHEMA = Number.class;
/**
* A class that implements a strategy for what to do when a spout needs to wait. Waiting is
* triggered in one of two conditions:
*
* 1. nextTuple emits no tuples
* 2. The spout has hit maxSpoutPending and can't emit any more tuples
*/
public static final String TOPOLOGY_SPOUT_WAIT_STRATEGY="topology.spout.wait.strategy";
public static final Object TOPOLOGY_SPOUT_WAIT_STRATEGY_SCHEMA = String.class;
/**
* The amount of milliseconds the SleepEmptyEmitStrategy should sleep for.
*/
public static final String TOPOLOGY_SLEEP_SPOUT_WAIT_STRATEGY_TIME_MS="topology.sleep.spout.wait.strategy.time.ms";
public static final Object TOPOLOGY_SLEEP_SPOUT_WAIT_STRATEGY_TIME_MS_SCHEMA = Number.class;
/**
* The maximum amount of time a component gives a source of state to synchronize before it requests
* synchronization again.
*/
public static final String TOPOLOGY_STATE_SYNCHRONIZATION_TIMEOUT_SECS="topology.state.synchronization.timeout.secs";
public static final Object TOPOLOGY_STATE_SYNCHRONIZATION_TIMEOUT_SECS_SCHEMA = Number.class;
/**
* The percentage of tuples to sample to produce stats for a task.
*/
public static final String TOPOLOGY_STATS_SAMPLE_RATE="topology.stats.sample.rate";
public static final Object TOPOLOGY_STATS_SAMPLE_RATE_SCHEMA = Number.class;
/**
* The time period that builtin metrics data in bucketed into.
*/
public static final String TOPOLOGY_BUILTIN_METRICS_BUCKET_SIZE_SECS="topology.builtin.metrics.bucket.size.secs";
public static final Object TOPOLOGY_BUILTIN_METRICS_BUCKET_SIZE_SECS_SCHEMA = Number.class;
/**
* Whether or not to use Java serialization in a topology.
*/
public static final String TOPOLOGY_FALL_BACK_ON_JAVA_SERIALIZATION="topology.fall.back.on.java.serialization";
public static final Object TOPOLOGY_FALL_BACK_ON_JAVA_SERIALIZATION_SCHEMA = Boolean.class;
/**
* Topology-specific options for the worker child process. This is used in addition to WORKER_CHILDOPTS.
*/
public static final String TOPOLOGY_WORKER_CHILDOPTS="topology.worker.childopts";
public static final Object TOPOLOGY_WORKER_CHILDOPTS_SCHEMA = String.class;
/**
* This config is available for TransactionalSpouts, and contains the id ( a String) for
* the transactional topology. This id is used to store the state of the transactional
* topology in Zookeeper.
*/
public static final String TOPOLOGY_TRANSACTIONAL_ID="topology.transactional.id";
public static final Object TOPOLOGY_TRANSACTIONAL_ID_SCHEMA = String.class;
/**
* A list of task hooks that are automatically added to every spout and bolt in the topology. An example
* of when you'd do this is to add a hook that integrates with your internal
* monitoring system. These hooks are instantiated using the zero-arg constructor.
*/
public static final String TOPOLOGY_AUTO_TASK_HOOKS="topology.auto.task.hooks";
public static final Object TOPOLOGY_AUTO_TASK_HOOKS_SCHEMA = ConfigValidation.StringsValidator;
/**
* The size of the Disruptor receive queue for each executor. Must be a power of 2.
*/
public static final String TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE="topology.executor.receive.buffer.size";
public static final Object TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE_SCHEMA = ConfigValidation.PowerOf2Validator;
/**
* The maximum number of messages to batch from the thread receiving off the network to the
* executor queues. Must be a power of 2.
*/
public static final String TOPOLOGY_RECEIVER_BUFFER_SIZE="topology.receiver.buffer.size";
public static final Object TOPOLOGY_RECEIVER_BUFFER_SIZE_SCHEMA = ConfigValidation.PowerOf2Validator;
/**
* The size of the Disruptor send queue for each executor. Must be a power of 2.
*/
public static final String TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE="topology.executor.send.buffer.size";
public static final Object TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE_SCHEMA = ConfigValidation.PowerOf2Validator;
/**
* The size of the Disruptor transfer queue for each worker.
*/
public static final String TOPOLOGY_TRANSFER_BUFFER_SIZE="topology.transfer.buffer.size";
public static final Object TOPOLOGY_TRANSFER_BUFFER_SIZE_SCHEMA = Number.class;
/**
* How often a tick tuple from the "__system" component and "__tick" stream should be sent
* to tasks. Meant to be used as a component-specific configuration.
*/
public static final String TOPOLOGY_TICK_TUPLE_FREQ_SECS="topology.tick.tuple.freq.secs";
public static final Object TOPOLOGY_TICK_TUPLE_FREQ_SECS_SCHEMA = Number.class;
/**
* Configure the wait strategy used for internal queuing. Can be used to tradeoff latency
* vs. throughput
*/
public static final String TOPOLOGY_DISRUPTOR_WAIT_STRATEGY="topology.disruptor.wait.strategy";
public static final Object TOPOLOGY_DISRUPTOR_WAIT_STRATEGY_SCHEMA = String.class;
/**
* The size of the shared thread pool for worker tasks to make use of. The thread pool can be accessed
* via the TopologyContext.
*/
public static final String TOPOLOGY_WORKER_SHARED_THREAD_POOL_SIZE="topology.worker.shared.thread.pool.size";
public static final Object TOPOLOGY_WORKER_SHARED_THREAD_POOL_SIZE_SCHEMA = Number.class;
/**
* The interval in seconds to use for determining whether to throttle error reported to Zookeeper. For example,
* an interval of 10 seconds with topology.max.error.report.per.interval set to 5 will only allow 5 errors to be
* reported to Zookeeper per task for every 10 second interval of time.
*/
public static final String TOPOLOGY_ERROR_THROTTLE_INTERVAL_SECS="topology.error.throttle.interval.secs";
public static final Object TOPOLOGY_ERROR_THROTTLE_INTERVAL_SECS_SCHEMA = Number.class;
/**
* See doc for TOPOLOGY_ERROR_THROTTLE_INTERVAL_SECS
*/
public static final String TOPOLOGY_MAX_ERROR_REPORT_PER_INTERVAL="topology.max.error.report.per.interval";
public static final Object TOPOLOGY_MAX_ERROR_REPORT_PER_INTERVAL_SCHEMA = Number.class;
/**
* How often a batch can be emitted in a Trident topology.
*/
public static final String TOPOLOGY_TRIDENT_BATCH_EMIT_INTERVAL_MILLIS="topology.trident.batch.emit.interval.millis";
public static final Object TOPOLOGY_TRIDENT_BATCH_EMIT_INTERVAL_MILLIS_SCHEMA = Number.class;
/**
* Name of the topology. This config is automatically set by Storm when the topology is submitted.
*/
public static final String TOPOLOGY_NAME="topology.name";
public static final Object TOPOLOGY_NAME_SCHEMA = String.class;
/**
* Max pending tuples in one ShellBolt
*/
public static final String TOPOLOGY_SHELLBOLT_MAX_PENDING="topology.shellbolt.max.pending";
public static final Object TOPOLOGY_SHELLBOLT_MAX_PENDING_SCHEMA = Number.class;
/**
* The root directory in ZooKeeper for metadata about TransactionalSpouts.
*/
public static final String TRANSACTIONAL_ZOOKEEPER_ROOT="transactional.zookeeper.root";
public static final Object TRANSACTIONAL_ZOOKEEPER_ROOT_SCHEMA = String.class;
/**
* The list of zookeeper servers in which to keep the transactional state. If null (which is default),
* will use storm.zookeeper.servers
*/
public static final String TRANSACTIONAL_ZOOKEEPER_SERVERS="transactional.zookeeper.servers";
public static final Object TRANSACTIONAL_ZOOKEEPER_SERVERS_SCHEMA = ConfigValidation.StringsValidator;
/**
* The port to use to connect to the transactional zookeeper servers. If null (which is default),
* will use storm.zookeeper.port
*/
public static final String TRANSACTIONAL_ZOOKEEPER_PORT="transactional.zookeeper.port";
public static final Object TRANSACTIONAL_ZOOKEEPER_PORT_SCHEMA = Number.class;
/**
* The number of threads that should be used by the zeromq context in each worker process.
*/
public static final String ZMQ_THREADS = "zmq.threads";
public static final Object ZMQ_THREADS_SCHEMA = Number.class;
/**
* How long a connection should retry sending messages to a target host when
* the connection is closed. This is an advanced configuration and can almost
* certainly be ignored.
*/
public static final String ZMQ_LINGER_MILLIS = "zmq.linger.millis";
public static final Object ZMQ_LINGER_MILLIS_SCHEMA = Number.class;
/**
* The high water for the ZeroMQ push sockets used for networking. Use this config to prevent buffer explosion
* on the networking layer.
*/
public static final String ZMQ_HWM = "zmq.hwm";
public static final Object ZMQ_HWM_SCHEMA = Number.class;
/**
* This value is passed to spawned JVMs (e.g., Nimbus, Supervisor, and Workers)
* for the java.library.path value. java.library.path tells the JVM where
* to look for native libraries. It is necessary to set this config correctly since
* Storm uses the ZeroMQ and JZMQ native libs.
*/
public static final String JAVA_LIBRARY_PATH = "java.library.path";
public static final Object JAVA_LIBRARY_PATH_SCHEMA = String.class;
/**
* The path to use as the zookeeper dir when running a zookeeper server via
* "storm dev-zookeeper". This zookeeper instance is only intended for development;
* it is not a production grade zookeeper setup.
*/
public static final String DEV_ZOOKEEPER_PATH = "dev.zookeeper.path";
public static final Object DEV_ZOOKEEPER_PATH_SCHEMA = String.class;
/**
* A map from topology name to the number of machines that should be dedicated for that topology. Set storm.scheduler
* to backtype.storm.scheduler.IsolationScheduler to make use of the isolation scheduler.
*/
public static final String ISOLATION_SCHEDULER_MACHINES = "isolation.scheduler.machines";
public static final Object ISOLATION_SCHEDULER_MACHINES_SCHEMA = Map.class;
public static void setDebug(Map conf, boolean isOn) {
conf.put(Config.TOPOLOGY_DEBUG, isOn);
}
public void setDebug(boolean isOn) {
setDebug(this, isOn);
}
@Deprecated
public void setOptimize(boolean isOn) {
put(Config.TOPOLOGY_OPTIMIZE, isOn);
}
public static void setNumWorkers(Map conf, int workers) {
conf.put(Config.TOPOLOGY_WORKERS, workers);
}
public void setNumWorkers(int workers) {
setNumWorkers(this, workers);
}
public static void setNumAckers(Map conf, int numExecutors) {
conf.put(Config.TOPOLOGY_ACKER_EXECUTORS, numExecutors);
}
public void setNumAckers(int numExecutors) {
setNumAckers(this, numExecutors);
}
public static void setMessageTimeoutSecs(Map conf, int secs) {
conf.put(Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS, secs);
}
public void setMessageTimeoutSecs(int secs) {
setMessageTimeoutSecs(this, secs);
}
public static void registerSerialization(Map conf, Class klass) {
getRegisteredSerializations(conf).add(klass.getName());
}
public void registerSerialization(Class klass) {
registerSerialization(this, klass);
}
public static void registerSerialization(Map conf, Class klass, Class serializerClass) {
Map register = new HashMap();
register.put(klass.getName(), serializerClass.getName());
getRegisteredSerializations(conf).add(register);
}
public void registerSerialization(Class klass, Class serializerClass) {
registerSerialization(this, klass, serializerClass);
}
public void registerMetricsConsumer(Class klass, Object argument, long parallelismHint) {
HashMap m = new HashMap();
m.put("class", klass.getCanonicalName());
m.put("parallelism.hint", parallelismHint);
m.put("argument", argument);
List l = (List)this.get(TOPOLOGY_METRICS_CONSUMER_REGISTER);
if(l == null) { l = new ArrayList(); }
l.add(m);
this.put(TOPOLOGY_METRICS_CONSUMER_REGISTER, l);
}
public void registerMetricsConsumer(Class klass, long parallelismHint) {
registerMetricsConsumer(klass, null, parallelismHint);
}
public void registerMetricsConsumer(Class klass) {
registerMetricsConsumer(klass, null, 1L);
}
public static void registerDecorator(Map conf, Class klass) {
getRegisteredDecorators(conf).add(klass.getName());
}
public void registerDecorator(Class klass) {
registerDecorator(this, klass);
}
public static void setKryoFactory(Map conf, Class klass) {
conf.put(Config.TOPOLOGY_KRYO_FACTORY, klass.getName());
}
public void setKryoFactory(Class klass) {
setKryoFactory(this, klass);
}
public static void setSkipMissingKryoRegistrations(Map conf, boolean skip) {
conf.put(Config.TOPOLOGY_SKIP_MISSING_KRYO_REGISTRATIONS, skip);
}
public void setSkipMissingKryoRegistrations(boolean skip) {
setSkipMissingKryoRegistrations(this, skip);
}
public static void setMaxTaskParallelism(Map conf, int max) {
conf.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, max);
}
public void setMaxTaskParallelism(int max) {
setMaxTaskParallelism(this, max);
}
public static void setMaxSpoutPending(Map conf, int max) {
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, max);
}
public void setMaxSpoutPending(int max) {
setMaxSpoutPending(this, max);
}
public static void setStatsSampleRate(Map conf, double rate) {
conf.put(Config.TOPOLOGY_STATS_SAMPLE_RATE, rate);
}
public void setStatsSampleRate(double rate) {
setStatsSampleRate(this, rate);
}
public static void setFallBackOnJavaSerialization(Map conf, boolean fallback) {
conf.put(Config.TOPOLOGY_FALL_BACK_ON_JAVA_SERIALIZATION, fallback);
}
public void setFallBackOnJavaSerialization(boolean fallback) {
setFallBackOnJavaSerialization(this, fallback);
}
private static List getRegisteredSerializations(Map conf) {
List ret;
if(!conf.containsKey(Config.TOPOLOGY_KRYO_REGISTER)) {
ret = new ArrayList();
} else {
ret = new ArrayList((List) conf.get(Config.TOPOLOGY_KRYO_REGISTER));
}
conf.put(Config.TOPOLOGY_KRYO_REGISTER, ret);
return ret;
}
private static List getRegisteredDecorators(Map conf) {
List ret;
if(!conf.containsKey(Config.TOPOLOGY_KRYO_DECORATORS)) {
ret = new ArrayList();
} else {
ret = new ArrayList((List) conf.get(Config.TOPOLOGY_KRYO_DECORATORS));
}
conf.put(Config.TOPOLOGY_KRYO_DECORATORS, ret);
return ret;
}
}
代码比较多,稍后有时间再整理一下。