语音辨识的模型
语音辨识的模型
声明:本文章只用于个人总结,视频链接为https://www.bilibili.com/video/BV1nE411K7Tm?p=3。
根据不同的观点,现提出如下五个模型:
- Listen,Attend,and Spell (LAS) seq-to-seq
- Connectionist Temporal Classification (CTC)
- RNN Transducer (RNN-T)
- Neural Transducer
- Monotonic Chunkwise Attention (MoChA)
本文将讲述LAS模型。
1 LAS模型介绍
LAS分为三个部分,即Listen,Attend,and Spell。
2 Listen部分(encoder)
先来看看Listen部分。输入是一段acoustic features{x1,x2,…, xt},输出是另一段向量high-level representations{h1,h2,…,ht}。在这个阶段可以将语音里面杂音去掉,只抽出跟语音辨识相关的音序。

关于encoder部分可以用RNN、CNN等方法来实现,如下图所示。


CNN和RNN哪一种比较好呢?一般在文献中常见的方式是将二者结合起来使用,即前几层用CNN后几层用RNN。
由于声音讯号的acoustic feature中的向量数量太多,在做语音识别的时候,还需要对输入进行Down Sampling。常用的有Pyramid RNN、Pooling over time等方法。

3 Attend部分
首先要有个向量 z0(向量z理解的不是很清楚,视频中讲的是hidden state),然后再用 z0与encoder的输出通过match function进行运算,最后得到 z0 和encoder输出的相似度α。其具体的过程如下图所示。

其中常用的match function有Dot-product Attention、Additive Attention等方法。下图1是Dot-product Attention,图2是Additive Attention。

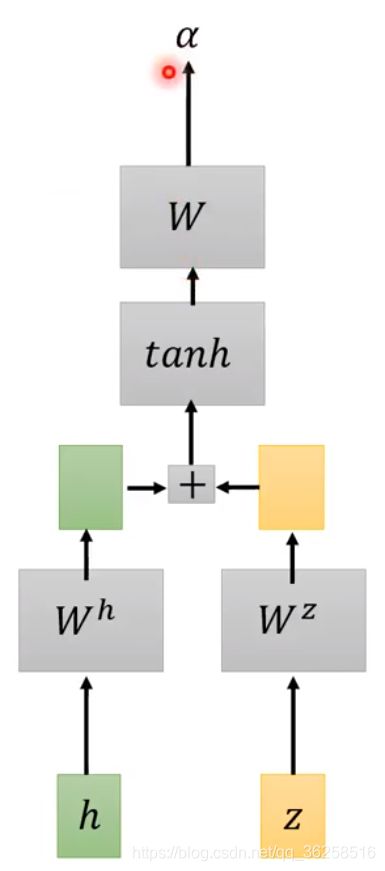
在得到各个h对应的相似度α之后,会继续做softmax从到得到处理后的α,之后再用这些得到的α跟之前经过encoder生成的h进行运算,从而得到向量c0,c0在文献上常常成为Context Vector,其是decoder的输入。得到c0之后,就可以进行到LAS的第三个阶段Spell。

4 Spell部分(decoder)
经过前两部分得到的向量c0,就可以进行Spell部分,此部分实现decoder的功能。c0当做decoder的输入,经过运算得到Distribution over all tokens,其表现形式为一个向量,向量的维度是V,表示各种期望的概率,再找到最大值作为识别结果。

此处仅仅只得到了一个结果,再往后进行就需把z1带入Attention部分进行运算得到c1,以此类推……在此过程中,前一个hidden state得到的输出结果会作为后一个hidden state的输入。

在做decoder的时候会做一个Beam Search的操作,这个过程是在树上找到几率最大的路径。下图是一个例子。

在上图中,红色是贪心算法得到的结果,但其不是最优解,绿色才是最优解。由此可见,在树上做贪心不是一个很好的方法。这里我们可以用BFS算法+优先队列的思想,但考虑到节点过多可能导致爆栈或者计算量过大,这里可以自定义保留每一层最优的B(Beam size)种情况,其余的情况可以剪枝。如下图所示。

5 Training部分
在完成前面的步骤后,就可以进行Training了。如下图所示。
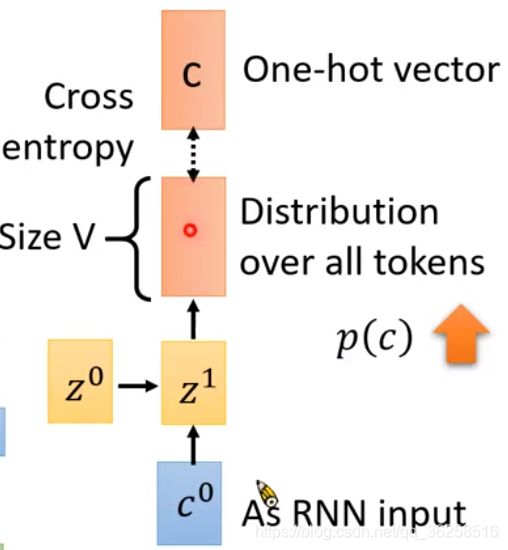
在训练过程中,我们给出已知的正确结果,在向量中表示成One-hot vector,接下来再算输出的Distribution与One-hot vector进行比较,我们需要让训练的结果越接近正确结果越好,即此处的*p( c )*越大越好。对于后面的过程以此类推……

在spell中,前一个产生的输出会对后一个的输出产生影响,但在training中略有不同。如上图所示。与spell不同的是,training的过程中,在产生输出之前会给出正确答案;并且前一个产生的结果不重要,只需要把前一个正确的结果传进去。此过程称为Teacher forcing。用Teacher forcing有个好处,在训练的过程中,假如前一个输出是错的,其作为下一个的输入可能会对下一个输出产生一定的影响,从而浪费很多训练的时间;而每次把正确的结果给下一次的输入,可以减少这种不必要的消耗。
6 others
在spell的过程中,不仅可以将attend产生*ct*的作为下一个输入,还可以作为当前的输入使用,两种方法可以一起使用。具体见下图。

7 Lititation of LAS
- LAS outputs the first token after listening the whole input.
- Users expect online speech recognition.
LAS不能完成在线识别,即不能逐字产生结果。