Linux设备驱动开发基础
1.驱动概述和开发环境搭建
1.1驱动设备的作用
对设备驱动最通俗的解释就是“驱动硬件设备行动”。驱动与底层硬件直接打交道,按照硬件设备的具体工作方式,读写设备的寄存器,完成设备的轮训、中断处理、DMA通信,进行物理内存向虚拟内存的映射等,最终让通信设备能收发数据,让显示设备能显示文字和画面,让存储设备能记录文件和数据。
由此可见,设备驱动充当了硬件和应用软件之间的纽带,他使得应用软件只需要调用系统软件的应用编程接口(API)就可让硬件去完成要求的工作。在系统中没有操作系统的情况下,工程师可以根据硬件设备的特点自行定义接口,如串口定义SerialSend()、SerialRecv(),对LED定义LightOn()、LightOff(),对Flash定义FlashWrite()、FlashRead()等。而在有操作系统的情况下,驱动的架构则由相应的操作系统定义,驱动工程师必须按照相应的架构设计设计驱动,这样,驱动才能良好地整合操作系统的内核。
1.2无操作系统时的设备驱动
并不是任何一个计算机系统都一定要运行操作系统,在许多情况下,操作系统都不必存在,对于功能比较单一、控制并不复杂的系统,并不需要多任务调度、文件系统、内存管理等复杂功能,用单任务架构完全可以良好地支持他们工作。一个无限循环中夹杂设备中断的检测或者对设备的轮训是这种系统中软件的典型架构。
在这样的系统中,虽然不存在操作系统,但是设备驱动则无论如何都必须存在,一般情况下,每一种设备驱动都会定义为一个软件模块,包含.h文件和.c文件,前者定义该设备驱动的数据结构并声明外部函数,后者进行驱动的具体实现。
其他模块想要使用这个设备的时候,只需要包含设备驱动的头文件。然后调用其中的外部接口函数。
驱动如软硬件的关系如下图:
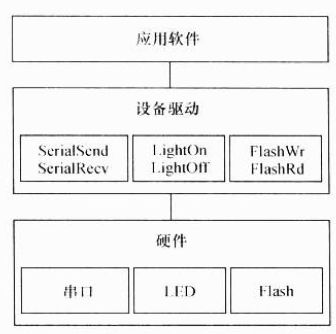
在没有操作系统的情况下,设备驱动的接口被直接提交给了应用软件工程师,应用软件工程师没有跨越任何层次就直接访问了设备驱动的接口。驱动包含的接口函数也与硬件的功能直接吻合,没有任何附加功能。
1.3有操作系统时的设备驱动
首先,无操作系统时设备驱动的硬件操作工作仍然是必不可少的,没有这一部分,驱动不可能与硬件打交道。
其次,我们还需要将驱动融入内核。为了实现这种融合,必须在所有设备的驱动中设计面向操作系统内核的接口,这样的接口由操作系统规定,对一类设备而言结构一致,独立于具体的设备。
由此可见,当系统中存在操作系统时,驱动变成了连接硬件和内核的桥梁。操作系统的存在势必要求设备驱动俯加更多的代码和功能,把单一的“驱动硬件设备行动”变成了操作系统与硬件交互的模块,他对外呈现为操作系统的API。不再给应用软件工程师直接提供接口。
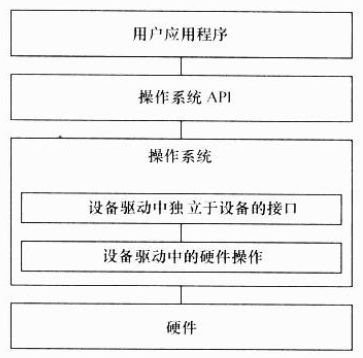
简而言之,操作系统通过给驱动制造麻烦来达到给上层应用提供便利的目的。当驱动都按照操作系统给出的独立于设备的接口而言,那么,应用程序将可使用统一的系统调用接口来访问各种设备。当应用程序通过write()、read()等函数读写文件就可以访问字符设备和块设备,而不论设备的具体类型和工作方式。
1.4 Linux设备驱动
1.4.1设备的分类和特点
计算机系统的硬件主要有CPU、存储器和外设组成。
驱动针对的对象是存储器和外设(包括CPU内部集成的存储器和外设),而不是针对CPU核。Linux将存储器和外设分为3个基础大类:字符设备、块设备、网络设备。
字符设备指那些必须以串行顺序依次进行访问的设备,如触摸屏、磁盘驱动器、鼠标等。
块设备可以任意顺序进行访问,以块为单位进行操作,如硬盘、软驱等。
网络设备面向数据包的接收和发送而设计,它并不对应于文件系统的节点。内核与网络设备的通信与内核和字符设备、网络设备的通信方式完全不同。
字符设备不经过系统的快速缓冲,而块设备经过系统的快速缓冲,但是,字符设备和块设备并没有明显的界限,如对于Flash设备,符合块设备的特点,但是我们仍然把他作为一个字符设备来访问。
字符设备和块设备的驱动设计呈现很大的差异,但是对于用户而言,他们都使用系统的接口操作open()、close()、read()、write()等进行访问。
另外一种设备分类方法中所称的IC驱动、USB驱动、PCI驱动、LCD驱动等本身可归纳入3个基础大类,但是对于这些复杂的设备,Linux也定义了独特的驱动体系结构。
1.4.2 Linux设备驱动与整个软硬件系统的关系
除了网络设备外,字符设备与块设备都被映射到Linux文件系统的文件和目录,通过文件系统的系统接口open()、write()、read()、close()等即可访问字符设备和块设备。所有的字符设备和块设备都被统一地呈现给用户。块设备比字符设备复杂,在它上面会首先建立一个磁盘/Flash文件系统,如FAT、EXT3、YAFFS2、JFFS2、UBIFS等。FAT、EXT3、YAFFS2、JFFS2、UBIFS定义了文件和目录存储介质上的组织。
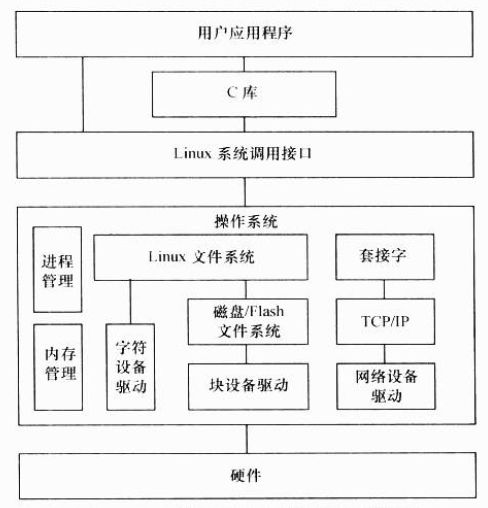
应用程序可以使用Linux的系统调用接口变成,但也可使用C库函数,出于代码可一致性的目的,后者更值得推荐。C库函数本身也通过系统调用接口而实现,如C库函数fopen()、fwrite()、fread()、fclose()分别会调用操作系统的API open()、write()、read()、close()。
1.4.3 Linux设备驱动的重点、难点
编写Linux设备驱动要求工程师非常好的硬件基础,懂得SRAM、Flash、SDRAM、磁盘的读写方式,UART、IC、USB等设备的接口以及轮训、中断、DMA的原理,PCI总线的工作方式以及CPU的内存管理单元(MMU、)等。
编写Linux设备驱动要求工程师有非常好的C语言基础,能灵活地运用C语言的结构体、指针、函数指针及内存动态申请和释放等。
编写Linux设备驱动要求工程师有一定的Linux内核基础,虽然并不要求工程师对内核各个部分有深入的研究,但至少要明白驱动与内核的接口。尤其是对于块设备、网络设别、Flash设别、串口设备等复杂设备,内核定义的驱动体系架构本身就非常复杂。
编写Linux设备驱动要求工程师有非常好的多任务并发控制和同步的基础,因为在驱动中会大量使用自旋锁、互斥、信号量、等待队列等并发与同步机制。
1.5 Linux设备驱动开发环境搭建
1.5.1 PC上的Linux环境
安装虚拟机,然后在虚拟机上安装Linux系统。
1.5.2 LDD6410开发板
1.5.3 工具链安装
(1)下载交叉编译包,例如http://dll6410.googlecode.com/files/cross-4.2.2-eabi.tar.bz2,并解压到user/local/arm目录下。
(2)设置环境变量
编辑/etc/profile文件,在文件末尾添加:PATH=“$PATH:/usr/local/arm/4.2.2-ebi/usr/bin” export PATH 设置环境变量。使环境变量生效 source /etc/profile命令。
也可以通过修改home目录的.bashrc来将/usr/local/arm/4.2.2-eabi/usr/bin添加到PATH:export PATH=/usr/local/arm/4.2.2-eabi/usr/bin/:$PATH
(3)测试环境变量是否设置成功
在终端输入:echo $PATH,如果输出的路径包含添加的内容,说明环境变量设置成功。
(4)测试交叉编译工具链
在终端输入“arm-linux-gcc-v”查看交叉编译工具链是否安装成功。调试工具包含了strace、gdbserver和arm-linux-gdb,其中strace、gdbserver用于目标板文件系统,arm-linux-gdb运行于主机端,对目标板上的内核、内核模块应用程序进行调试。
将arm-linux-gdb放入主机上arm-linux-gcc所在的目录/usr/local/arm/4.2.2-ebi/usr/bin/。
而strace、gdbserver则可根据需要放入目标机根文件系统的/usr/sbin目录
1.5.4 主机端nfs和tftp服务安装
LDD6410可使用tftp或nfs文件系统与主机通过网口交互交互。
主机端安装tftp服务的方法:sudo apt-get install tftpd-hpa
开启tftp服务的方法:sudo /etc/init.d/tftpdhpa start Starting HPA's tftpd:in.tftpd
对于Ubuntu或Debian用户而言,在主机端可通过如下方法安装nfs服务:
apt-get install nfs-kernel-server
sudo mkdir /home/nfs
sudo chmod 777 /home/nfs
运行“sudo vim /etc/exports”或“sudo gedit /etc/exports”,修改该文件内容为: /home/nfs *(sync, rw)
运行exportfs rv开启NFS服务:/etc/init.d/nfs-kernel-server restart
1.5.5 源代码阅读和编辑
windows上用Source Insight阅读和编译源代码。
Linux上阅读和编译Linux源码的常用方式是vim+cscope或者vim+ctags,vim是一个文本编译器,而cscops和ctags则可建立代码索引。
1.6 设备驱动Hello World:LED驱动
1.6.1 无操作系统时的LED驱动
在嵌入式系统的设计中,LED一般直接由CPU的GPIO(通用可编程I/O口)控制。GPIO一般由两种寄存器控制,即一组控制寄存器和一组数据寄存器。控制寄存器可设置GPIO口的工作方式为输入或输出。当引脚被设置为输出时,向数据寄存器的对应位写入1或0会分别在引脚上产生高电平和低电平;当引脚设置为输入时,读取数据寄存器的对应位可获得引脚上的电平为高或低。
1.6.2 Linux下的LED驱动
在Linux下,可以使用字符设备驱动的框架来编写对应的LED设备驱动,接口函数遵循Linux编程的命名规范,这些函数将被LED设备驱动中独立于设备的针对内核的接口进行调用。
2.驱动设计的硬件基础
2.1 处理器
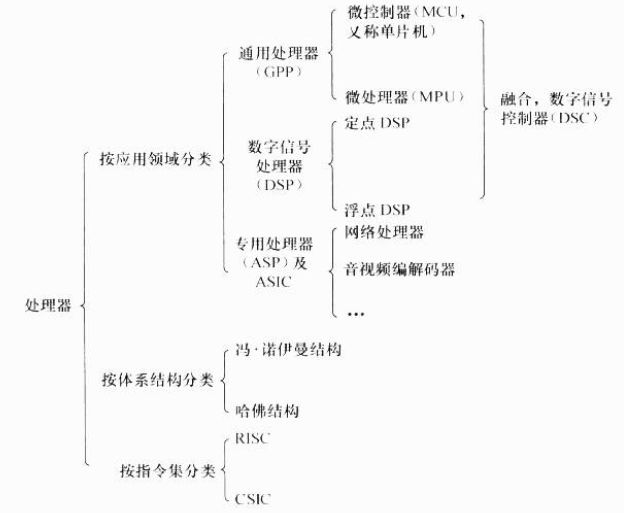
2.1.1 通用处理器
通用处理器(GPP)并不针对特定的应用领域进行体系结构和指令集的优化,他们具有一般化的通用体系结构和指令集,以求支持复杂的运算并易于添加新开发的功能。一般而言,在嵌入式控制器(MCU)和微处理器(MPU)中会包含一个通用处理器核。
MPU通常代表一个CPU(中央处理器),而MCU则强调把中央处理器、存储器和外围电路集成在一个芯片中。
2.1.2 数字信号处理器
数字信号处理器(DSP)针对通信、图像、语音和视频处理等领域的算法而设计。它包含独立的硬件乘法器。DSP的乘法指令一般在单周期内完成,且优化了卷积、数字滤波、FFT(快速傅里叶变换)、相关、矩阵运算等算法中的大量重复乘法。
DSP一般采用改进的哈佛架构,它具有独立的地址总线和数据总线,两条总线由程序存储器和数据存储器分时共用。
DSP分为两类,一类是定点DSP,一类是浮点DSP。浮点DSP的浮点运算用硬件来实现,可以在单周期内完成,因而其浮点运算处理速度高于定点DSP。而定点DSP只能用定点运算模拟浮点运算。
处理器分类:
2.2 存储器
存储器主要可分类为只读储存器(ROM)、闪存(Flash)、随机存取存储器(RAM)、光、磁介质存储器。
ROM还可分为不可编程ROM、可编程ROM(PROM)、可檫除可编程ROM(EPROM)和不可檫除可编程ROM(EEPROM),EEPROM完全可以用软件来插写,已经非常方便了。
存储器分类:

2.3 接口与总线
2.3.1 串口
2.3.2 IC
2.3.3 USB
USB提供了4种传输方式以适应各种设备的需要,具体说明如下:
控制(Control)传输方式:是双向传输,数据量通常较小,主要用来进行查询、配置和给USB设备发送通用的命令。
同步(Synchronization)传输方式:提供了确定的宽带和间隔时间,它被用于时间严格并具有较强容错性的流数据传输,或者用于要求恒定的数据传送率的即时应用。例如进行语音业务传输时,使用同步传输方式是很好的选择。
中断(Interrupt)传输方式:是单向的,对于USB主机而言,只有输入。中断传输方式主要用于定时查询设备是否中断数据要传送,该传输方式应用在少量的、分散的、不可预测的数据传输场合,键盘、游戏杆和鼠标属于这一类型。
批量(Buld)传输方式:批量传输方式应用在没有宽带和间隔时间要求的批量数据的传送和接收,他要求保证传输。打印机和扫描仪属于这类型。
2.3.4 以太网接口
以太网接口由MAC(以太网媒体接入控制器)和PHY(物理接口接口收发器)组成。
2.3.5 ISA
2.3.6 PCI和cPCI
3.linux内核及内核编程
3.1 Linux内核的发展与演变
Linux操作系统时UNIX操作系统的一种克隆系统。
3.2 Linux 2.6内核的特点
Linux 2.6相对于Linux 2.4有相当大的改进,主要体现在如下几个方面:
新的调度器:Linux内核使用了新的进程调度算法,它在高负载的情况下执行得极其出色,并且当有很多处理器时也可以很好地扩展。
内核抢占:一个内核任务可以被抢占,从而提高系统的实时性,这样做最主要的优势在于,可以极大地增强系统的用户交互性,用户将会觉得鼠标单击和击键的事件得到了更快速的相应。
改进的线程模型:Linux中线程操作速度得以提高,可以处理任意数目的线程,最大可以到20亿。
虚拟内存的变化:从虚拟内存的角度看来,新内核融合了r-map(反向映射)技术,显著改善虚拟内存在一定程度负载下的性能。
文件系统:增加了对日志文件系统功能的支持,在文件系统上的关键变化还包括扩展属性及Posix标准访问控制的支持。et2/et3作为大多数Linux系统缺省安装的文件系统,增加了对扩展属性的支持,可以给指定的文件在文件系统中嵌入元数据。
音频:新的Linux音频体系结构ALSA(Advanced Linux Sound Architecture)取代了缺陷很多的旧的OSS(Open Sound System)。新的声音体系结构支持USB音频和MIDI设备,并支持全双工重放等功能。
总线:SCSI/IDE子系统经过大幅度的重写,解决和改善了以前的一些问题。可以直接通过IDE驱动程序来支持IDE CD/RW设备,而不必像以前一样要使用一个特别的SCSI模拟驱动程序。
电源管理:支持ACPI(高级电源配置管理界面),用于调增CPU在不同的负载下工作于不同的时钟频率以降低功耗。
联网和IPSec:内核中加入了对IPSec的支持,删除了原来内核内置的HTTP服务器khttpd,加入了对新的NFSv4(网络文件系统)客户机/服务器的支持,并改进了对IPv6的支持。
用户界面层:内核重写了帧缓冲/控制台层,人机界面层还加入了对近乎所有接口设备的支持(从触摸屏到盲人用的设备和各种各样的鼠标)。
在设备驱动程序方面,也有较大的改动,主要表现在内核API中增加了不少新功能(例如内存池)、sysfs文件系统、内核模块从.o变为.ko、驱动模块编译方式、模块使用计数、模块加载和卸载函数的定义等方面。
3.3 Linux内核的组成
3.3.1 Linux内核源代码目录结构
arch:包含和硬件体系结构相关的代码,每种平台占一个相应的目录,如i386、arm、powerpc、mips等。
block:块设备驱动程序I/O调度。
crypto:常用加密和散列算法(如AES、SHA等),还有一些压缩和CRC校验算法。
Documentation:内核各部分的通用解释和注释。
drivers:设备驱动程序,每个不同的驱动占用一个子目录,如char、block、met、mtd、i2c等。
fs:支持的各种文件系统,如EXT、FAT、NTFS、JFFS2等。
include:头文件,与系统相关的头文件被放置在include/linux子目录下。
init:内核初始化代码。
ipc:进程间通信的代码。
kernel:内核的最核心部分,包括进程调度、定时器等,而平台相关的一部分代码放在arch/*/kernel目录下。
lib:库文件代码。
mm:内存管理代码,和平台相关的一部分代码放在arch/*/mm目录下。
net:网络相关代码,实现了各种常见的网络协议。
scripts:用于配置内核的脚本文件。
security:主要是一个SELinux的模块。
sound:ALSA、OSS音频设备的驱动核心代码和常用设备驱动。
usr:实现了用于打包和压缩的cpio等。
3.3.2 Linux内核的组成部分
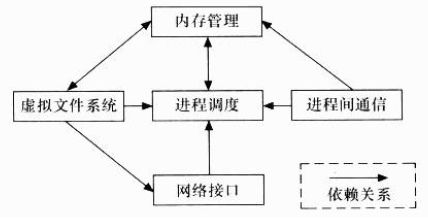
Linux内核主要由进程调度(SCHED)、内存管理(MM)、虚拟文件系统(VFS)、网络接口(NET)和进程间通信(IPC)5个子系统组成。
(1)进程调度
进程调度控制系统中的多个进程对CPU的访问,使得多个进程能在CPU中“微观串行,宏观并行”地执行。进程调度处于系统的中心位置,内核中其他的子系统都依赖他,因为每个子系统都需要挂起或恢复进程。
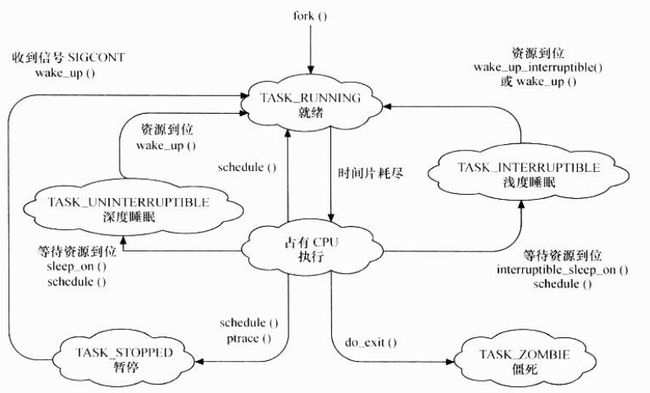
当请求的资源不能得到满足时,驱动一般会调度其他进程执行,并使本进程进入睡眠状态,直到它请求的资源被释放,才会被唤醒而进入就绪态。睡眠分成可被打断的睡眠和不可被打断的睡眠,两者的区别在于被打断的睡眠在收到信号的时候会醒。
设备驱动中,如果需要几个并发执行得任务,可以启动内核线程,启动内核线程的函数为:pid_t kernek_thread(int (*fn)(void *), void *arg, unsigned long flags);
(2)内存管理
内存管理的主要作用是控制多个进程安全地共享主内存区域。当CPU提供内存管理单元(MMU’)时,Linux内存管理完成为每个进程进行虚拟内存到物理内存的转换。
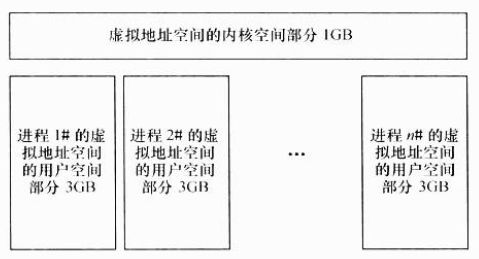
一般而言,Linux的每个进程享有4GB的内存空间,0~3GB属于用户空间,3~4GB属于内核空间,内核空间对常规内存、I/O设备内存以及高端内存存在不同的处理方式。
(3)虚拟文件系统

Linux虚拟文件系统(VFS)隐藏各种硬件的具体细节,为所有的设备提供了统一的接口。而且,它独立于各个具体的文件系统,是对各种文件系统的一个抽象,它使用超级块super bolck存放文件系统相关信息,使用索引节点inode存放文件的物理信息,使用目录项dentry存放文件的逻辑信息。
(4)网络接口
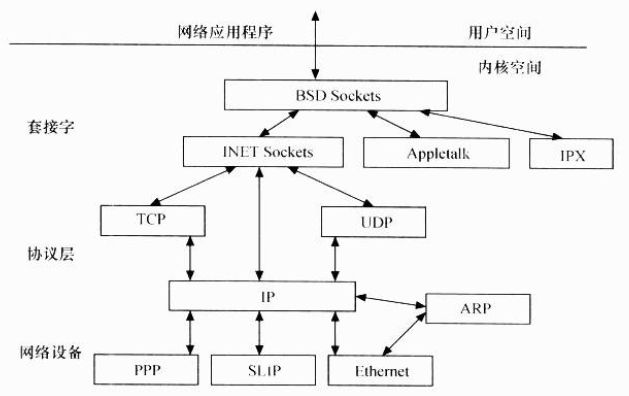
网络接口提供了对各种网络标准的存取和各种网络硬件的支持。在Linux中网络接口可分为网络协议和网络驱动程序,网络协议部分负责实现每一种可能的网络传输协议,网络设备驱动程序负责与硬件设备同行,每一种可能的硬件设备都有相应的设备驱动程序。
(5)进程通信
进程通信支持提供进程之间的通信,Linux支持进程间的多种通信机制,包含信号量、共享内存、管道等,这些机制可协助多个进程、多个资源的互斥访问、进程间的同步和消息传递。
Linux内核的5个组成部分之间的依赖关系如下:
进程调度与内存管理之间的关系:这两个子系统互相依赖。在多道程序环境下,程序要运行必须为之创建进程,而创建进程的第一件事情就是将程序和数据装入内存。
进程间通信与内存管理的关系:进程间通信子系统要依赖内存管理支持共享内存通信机制,这种机制允许两个进程除了拥有自己的私有空间,还可以存取共同的内存区域。
虚拟文件系统与网络接口之间的关系:虚拟文件系统利用网络接口支持支持网络文件系统(NFS),也利用内存管理支持RAMDISK设备。
内存管理与虚拟文件系统之间的关系:内存管理利用虚拟文件系统支持交换,交换进程(swapd)定期由调度程序调度,这也是内存管理依赖于进程调度的唯一原因。当一个进程存取的内存映射被换出时,内存管理向文件系统发出请求,同时,挂起当前正在运行的进程。
除了这些依赖关系外,内核中的所有子系统还要依赖于一些共同的资源。这些资源包括所有子系统都用到的例程,如分配和释放内存空间的函数、打印警告或错误信息的函数及系统提供的调试例程等。
3.3.3 Linux内核空间与用户空间
现代CPU内部往往实现了不同的操作模式(级别),不同的模式有不同的功能,高层程序往往不能访问低级功能,而必须以某种方式切换到低级模式。
ARM处理器分为7种工作模式:
用户模式(usr):大多数的应用程序运行在用户模式下,当处理器运行在用户模式下时,某些被保护的系统资源是不能被访问的。
快速中断模式(fiq):用于高速数据传输或通道处理。
外部中断模式(irq):用于通用的中断处理。
管理模式(svc):操作系统使用的保护模式。
数据访问终止模式(abt):当数据或指令预取终止时进入该模式,可用于虚拟存储及存储保护。
系统模式(sys):运行具有特权的操作系统任务。
未定义指令中止模式(und):当未定义的指令执行时进入该模式,可以用于支持硬件协处理器的软件仿真。
ARM Linux的系统调用实现原理是采用swi软中断从用户态usr模式陷入内核态svc模式。
X86处理器包含4个不同的特权级,称为Ring0~Ring3。Ring0下可以执行特权级指令,对任何I/O设备都有访问权等,而Ring3则被限制很多操作。
Linux系统中,内核可进行任何操作,而应用程序则被禁止对硬件的直接访问和对内存的未授权访问。
内核空间和用户空间这两个名词被用来区分程序执行的这两种不同状态,他们使用不同的地址空间。Linux只能通过系统调用和硬件中断完成从用户空间到内核空间的控制转移。
3.4 Linux内核的编译及加载
3.4.1 Linux内核的编译
Linux驱动工程师需要牢固地掌握Linux内核的编译方法以为嵌入式系统构建可运行的Linux操作系统映像。
配置内核的方法:
#make config(基于文本的最为传统的配置界面,不推荐使用)
#make menuconfig(基于文本菜单的配置界面,最值得推荐,不依赖与QT或GTK+,且非常直观)
#make xconfig(要求QT被安装)
#make gconfig(要求GTK+被安装)
编译内核和模块的方法:
make zImage
make modules
执行完上述命令后,在源代码的跟目录下会得到未压缩的内核映像vmlinux和内核符号表文件System.map,在arch/arm/boot/目录会得到压缩的内核映像zImage,在内核个对应目录得到选中的内核模块。
Linux2.6内核的配置系统由以下3个部分组成:
Makefile:分布在Linux内核源码中的Makefile,定义Linux内核的编译规则。
配置文件(Kconfig):给用户提供配置选择的功能。
配置工具:包括配置命令解释器(对配置脚本中使用的配置命令进行解释)和配置用户界面(提供基于字符界面和图形界面)。这些配置工具都是使用脚本语言,如Tcl/TK、Perl等编写。
使用make config、make menuconfig等命令后,会生成一个.config配置文件,记录那些部分被编译入内核、那些部分被编译为内核模块。
3.4.2 Kconfig和Makefile
在Linux内核中增加程序需要完成以下3项工作:
将编写的源代码拷入Linux内核源代码的相应目录。
在目录的Kconfig文件中增加关于新源代码对应项目的编译配置选项。
在目录的Makefile文件中增加对新源代码的编译条目。
3.4.3 Linux内核的引导
引导Linux系统的过程包括很多阶段,这里将以引导X86 PC为例来进行讲解。引导X86 PC上的LInux的过程和引导嵌入式系统上的Linux的过程基本类似。不过在X86 PC上有一个从BISO(基本输入/输出系统)转移到Bootloader的过程,而嵌入式系统往往复位后就直接运行Bootloader。
下图为X86 PC从上电/复位到运行Linux用户空间初始进程的流程。

在进入与Linux相关代码之间会经历如下阶段:
(1)当系统上电或复位时,CPU会将PC指针赋值为一个特定的地址0xFFFF0并执行该地址处的指令。在PC机上,该地址位于BIOS中,它保存在主板的ROM或Flash中。
(2)BIOS运行时按照CMOS的设置定义的启动设备顺序来搜索处于活动状态并且可以引导的设备。若从硬盘启动,BIOS会将硬盘MBR(主引导记录)中的内容加载到RAM。MBR是个512字节大小的扇区,位于磁盘上的第一个扇区中(0道0柱面1扇区)。当MBR被加载到RAM中之后,BIOS就会将控制权交给MBR。
(3)主引导加载程序查找并加载次引导加载程序,它在分区表中查找活动分区,当找到一个活动分区时,扫描分区表中的其他分区,以确保它们都不是活动的。当这个过程验证完成后,就将活动分区的引导记录从这个设备中读入RAM中并执行它。
(4)次引导加载程序加载Linux内核和可选的初始RAM磁盘,将控制权交给Linux内核源代码。
(5)运行被加载的内核,并启动用户空间应用程序。
嵌入式系统中Linux的引导过程与之类似,但一般更加简洁。不论具体以怎样的方式实现,只要具备如下特征就可以称其为Bootloader。
可以在系统上电或复位的时候以某种方式执行,这些方式包括被BIOS引导执行、直接在NOR Flash中执行、NAND Flash中的代码被MCU自动拷入内部或外部RAM执行等。
能将U盘、磁盘、光盘、NOR/NAND Flash、ROM、SD卡等存储介质,甚或网口、串口中的操作系统加载到RAM并把控制权交给操作系统源代码执行。
完成上述功能的Bootloader的实现方式非常多样化,甚至本身也可以是一个简化版的操作系统。著名的Linux Bootloader包括应用于PC的LILO和GRUB,应用嵌入式系统的U-Boot、RedBoot等。
相比较于LILO,GRUB本身能理解EXT2、EXT3文件系统,因此可在文件系统中加载Linux,而LILO只能识别“裸扇区”。
U-Boot的定位为“Universal Bootloader”,其功能比较强大,涵盖了包括PowerPC、ARM、MIPS和X86在内的绝大部分处理器架构,提供网卡,串口、Flash等外设驱动,提供必要的网络协议(BOOTP、DHCP、TFTP),能识别多种文件系统(cramfs、fat、jffs2和registerfs等),并附带了调试、脚本、引导等工具,应用十分广泛。
Redboot是Redhat公司随eCos发布的Bootloader开源项目,除了包含U-Boot类似的强大功能外,它还包含GDB stub(插桩),因此能通过串口或网口与GDB进行通信,调试GCC产生的任何程序(包括内核)。
我们有必要对上述流程的第5个阶段进行更详细的分析,它完成启动内核并运行用户空间的init进程。
当内核映像被加载到RAM之后,Bootloader的控制权被释放,内核阶段就开发了。内核映像并不是完全可直接执行的目标代码,而是一个压缩过的zimage(小内核)或bzimage(打内核)。
但是,并非zimage和bzimage映像中的一切都被压缩了,否则Bootloader把控制权交给这个内核映像他就“傻”了,实际山,映像中包含违背压缩的部分,这部分中包含解压缩程序,解压缩程序会解压映像中的被压缩的部分,zImage和bzImage都是用gzip压缩的,它们不仅是一个压缩文件,而且在这两个文件的开头部分内嵌有gzip解压缩代码。

如上图所示,当bzImage(用于i386映像)被调用时,它从/arch/i386/boot/head.S的start汇编例程开始执行。这个程序执行一些基本的硬件设置,并调用/arch/i386/boot/compressed/head.S中的startup_32例程。startup_32程序设置一些基本的运行环境(如堆栈)后,清除BSS段,调用/arch/i386/boot/compressed/misc.c中decompress_kernel() C函数解压内核。内核被解压到内存中之后,会调用/arch/i386/kernel/head.S文件中的startup_32例程,这个新的startup_32例程(称为清除程序和进程0)会初始化页表,并启动内存分页机制,接着为任何可选的浮点单元(FPU)检测CPU的类型,并将其存储起来供以后使用。这些都做完之后,/init/main.c中的start_kernel()函数被调用,进入与体系结构无关的Linux内核部分。
start_kernel()会调用一系列初始化函数来设置中断,执行进一步的内存配置。之后,/arch/i386/kernel/process.c中kernel_thread()被调用以启动第一个核心线程,该线程执行init()函数,而原执行序列会调用cpu_idile()等待调度。
作为核心线程的init()函数完成外设及其驱动程序的加载和初始化,挂接根文件系统。init()打开/dev/console设备,重定向stdin、stdout和stderr到控制台。之后,它搜索文件系统中的init程序(也可以由“init=“命令行参数指定init程序),并使用execve()系统调用执行init程序,搜索init程序的顺序为:/sbin/init、/etc/init、/bin/init和/bin/sh。在嵌入式系统中,多数情况下,可以给内核传入一个简单的shell脚本来启动必须的嵌入式应用程序。
至此,漫长的Linux内核引导和启动过程就此结束,而init()对应的这个由start_kernel创建的第一个线程也进入用户模式。
3.5 Linux下的C编程特点
3.5.1 Linux编码分格
Linux程序的命令习惯和Windows程序的命名习惯及著名的匈牙利命名法有很大的不同。
在Windows程序中习惯以如下方式命名宏、变量和函数:
#define PI 3.1415926 /*用大写字母代表宏*/
int minValue, maxValue; /*变量:第一个单词全写,其中其后的单词第一个字母大写*/
void SendData(void) /*函数:所有单词第一个字母都大写定义*/
在Linux程序习惯如下方式命名宏、变量、函数:
#define PI 3.1415926
int min_value, max_value;
void send_data(void)
Linux的代码缩进使用”TAB“(8个字符)。
Linux的代码括号”{"和”}“的使用原则如下:
对于结构体、if/for/while/switch语句,”{“不另起一行。
如果if、for循环后只有一行,不要加”{“和"}"。
if和else混用的情况下,else语句不另起一行。
对于函数,”{“另起一行。
在switch/case语句方面,Linux建议switch和case对其。
内核下的Documentation/CodingStyle描述了Linux内核对编码风格的要求,内核下的scripts/checkpatch.p1提供了1个检查代码风格的脚本。
3.5.2 GUN C与ANSI C
Linux上可用的C编译器是GUN C编译器,它建立在自由软件基金会的编程许可证的基础上,因此可以自由发布,GUN C对标准C进行一系列扩展,以增强标准C的功能。
1.零长度和变量长度数组
GUN C允许使用零长度数组,在定义变长对象的头结构时,这个特性非常有用。例如:
struct var_data{
int len;
char data[0];
};
char data[0]仅仅意味着程序中通过var_data结构体实例的data[index]成员可以访问len之后的第index个地址,它并没有为data[]数组分配内存,因此sizeof(struct var_data)=sizeof(int)。
GUN C中也可以使用1个变量定义数组,例如可以定义”double x[n]“。
2.case范围
GUN C支持case x...y这样的语法,区间[x,y]的数都会满足这个case的条件。
3.语句表达式
GUN C把包含在括号中的复合语句看做事一个表达式,称为语句表达式,它可以出现在任何允许表达式的地方。我们可以在语句表达式中使用原本只能在符合语句中使用的循环、局部变量等。例如:
#define min_t(type, x, y) ({type _x=(x); type _y=(y); _x<_y?_x:_y})
因为重新定义了_x和_y这两个局部变量,所以以上述方式定义的宏将不会有副作用。在标准C中,对应的如下宏则会产生副作用:
#define min(x,y) ((x)<(y)?(x)?(y))
4.typeof关键字
typeof(x)语句可以获得x的类型,因此,我们可以借助typeof重新定义min这个宏:
#define min(x, y) ({const typeof(x) _x=(x); const typeof(y) _y=(y); (void) (&_x==&_y); _x<_y?_x:_y})
5.可变参数宏
标准C就支持可变参数函数,意味着函数的参数是不固定的,例如printf()函数的原型为:
int printf(const char *format [, argument]...);
而在GUN C中,宏也可以接受可变数目的参数,例如:
#define pr_debug(fmt, arg...) printk(fmt, ##arg)
使用”##“的原因是处理arg不代表任何参数的情况,这时候,前面的逗号就变得多余了。使用”##“之后,GUN C预处理器会丢弃前面的逗号。
6.标号元素
标准C要求数组或结构体的初始化值必须以固定的顺序出现,在GUN C中,通过制定索引或结构体成员名,允许初始化值以任意顺序出现。
指定数组索引的方法是在初始化值前添加”[INDEX]=“,当然也可以用”[FIRST...LAST]=“的形式指定一个范围。
7.当前函数名
GUN C预定义了两个标志符保存当前函数的名字,__FUNCTION__保存函数的源码中的名字,__PRETTY_FUNCTION__保存带语言特色的名字。在C函数中,着这两个名字是相同的。C99已经支持__func__宏,因此建议在Linux编程中不再使用__FUNCTION__,而转而使用__func__。
8.特殊属性声明
GUN C运行声明函数、变量和类型的特殊属性,以便进行手工的代码优化和定制代码检查的方法,要制定一个声明的属性,只需要在声明后添加__attribute__((ATTRIBUTE))。其中ATTRIBUTE为属性说明,如果存在多个属性,则以逗号分隔。GUN C支持noreturn、format、section、aligned、packed等十多个属性。
noreturn属性作用于函数,表示该函数从不返回。这让编译器优化代码,并消除不必要的警告信息。
format属性也用于函数,表示该函数使用printf、scanf或strftime风格的参数,指定format属性可以让编译器根据格式串检查参数类型。
unused属性作用于函数和变量,表示该函数或变量可能不会被用到,这个属性可以避免编译器产生警告信息。
aligned属性用于变量、结构体或联合体,制定变量、结构体或联合体的对界方式,以字节为单位。
packed属性作用于变量和类型,用语变量或结构体成员时表示使用最小可能的对界,用于枚举、结构体或联合体类型时表示该类型使用最小的内存。
编译器对结构体成员及变量对界的目的是为了更快地访问结构体成员及变量占据的内存。
9.内建函数
GUN C提供了大量的内建函数,其中大部分是标准C库函数的GNU C编译器内建版本。不属于库函数的其他内建函数的命名通常以__builtin开始。如下所示。
内建函数__builtin_return_address(LEVEL)返回当前函数或其调用者的返回地址,参数LEVEL指定调用栈的级数,如0表示当前函数的返回地址,1表示当前函数的调用者的返回地址。
内建函数__builtin_constant_p(EXP)用于判断一个值是否为编译时常数,如果参数EXP的值是常数,函数返回1,否则返回0。
内建函数__builtin_expect(EXP, C)用于编译器提供分支预测信息,其返回值是整数表达式EXP的值,C的值必须是编译时常数。
在使用gcc编译C程序的时候,如果使用”-ansi -pedantic“编译选项,则会告诉编译器不使用GNU扩展语法。
3.5.3 do{}while(0)
在Linux内核中,经常看到do{}while(0)这样的语句,许多人开始都会疑惑,认为do{}while(0)毫无意义,因为它只会执行一次,加不加do{}while(0)效果是完全一样的,其实do{}while(0)用法主要用于宏定义中。
这里用一个简单点的宏来演示:
#define SAFE_FREE(p) do{free(p); p=NULL;}while(0)
假设这里去掉do{}while(0):
#define SAFE_FREE(p) free(p); p=NULL;
展开的代码中存在两个问题:
因为if分支后又两个语句,导致else分支没有对应的if,编译失败。
假设没有else分支,则SAFE_FREE中的第二个语句无论if测试是否通过,都会执行。的确,将SAFE_FREE的定义加上{}就可以解决上述问题了。但是,在C程序中,每个语句后面加分号是一种约定俗成的习惯,这样,else分支就又没有对应的if了,编译将无法通过。假设用了do{}while(0),就没有问题了,不会再出现编译问题。do{}while(0)的使用完全是为了保证宏定义的使用者能无编译错误地使用宏,它不对其使用者做任何假设。
3.5.4 goto
用不用goto一直是一个著名的争议话题,Linux内核源代码中对goto的应用非常广泛,但是一般只限于错误处理中。
这种goto用语处理处理的用法实在是简单而高效,只需保证在错误处理时,注销、资源释放等于正常的注册、资源申请顺序相反。