【leetcode】127.单词接龙 (广度优先遍历+双向广度优先遍历,java实现)
127. 单词接龙
难度中等400收藏分享切换为英文关注反馈
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回 0。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
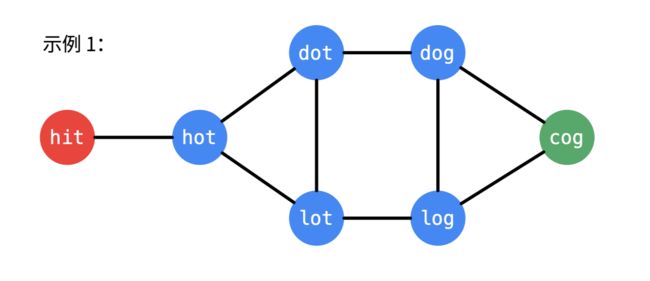
示例 1:
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出: 5
解释: 一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog",
返回它的长度 5。
示例 2:
输入:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
输出: 0
解释: endWord "cog" 不在字典中,所以无法进行转换。
分析
一句话题解
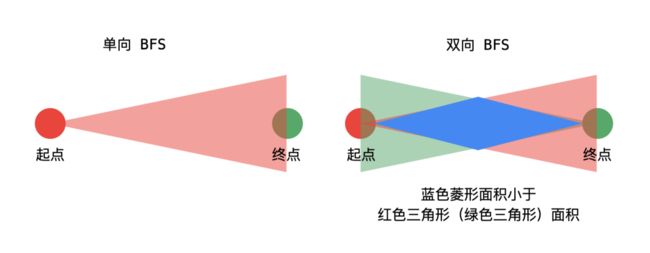
- 无向图中两个顶点之间的最短路径的长度,可以通过广度优先遍历得到;
- 为什么 BFS 得到的路径最短?可以把起点和终点所在的路径拉直来看,两点之间线段最短;
- 已知目标顶点的情况下,可以分别从起点和目标顶点(终点)执行广度优先遍历,直到遍历的部分有交集,这是双向广度优先遍历的思想。
分析题意:
- 「转换」意即:两个单词对应位置只有一个字符不同,例如 “hit” 与 “hot”,这种转换是可以逆向的,因此,根据题目给出的单词列表,可以构建出一个无向(无权)图;
- 如果一开始就构建图,每一个单词都需要和除它以外的另外的单词进行比较,复杂度是 O ( N w o r d L e n ) O(N \rm{wordLen}) O(NwordLen),这里 N 是单词列表的长度;
- 为此,我们在遍历一开始,把所有的单词列表放进一个哈希表中,然后在遍历的时候构建图,每一次得到在单词列表里可以转换的单词,复杂度是 O ( 26 × w o r d L e n ) O(26 \times \rm{wordLen}) O(26×wordLen),借助哈希表,找到邻居与 NN 无关;
- 使用 BFS 进行遍历,需要的辅助数据结构是:
- 队列;
visited集合。说明:可以直接在wordSet(由wordList放进集合中得到)里做删除。但更好的做法是新开一个哈希表,遍历过的字符串放进哈希表里。这种做法具有普遍意义。绝大多数在线测评系统和应用场景都不会在意空间开销。
方法一:广度优先遍历
参考代码 1:
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.Set;
public class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
Set<String> wordSet = new HashSet<>(wordList);
if (wordSet.size() == 0 || !wordSet.contains(endWord)) {
return 0;
}
wordSet.remove(beginWord);
// 图的广度优先遍历,必须使用的队列和表示是否访问过的 visited (数组,哈希表)
Queue<String> queue = new LinkedList<>();
queue.offer(beginWord);
Set<String> visited = new HashSet<>();
visited.add(beginWord);
int wordLen = beginWord.length();
// 包含起点,因此初始化的时候步数为 1
int step = 1;
while (!queue.isEmpty()) {
int currentSize = queue.size();
for (int i = 0; i < currentSize; i++) {
// 依次遍历当前队列中的单词
String word = queue.poll();
char[] charArray = word.toCharArray();
// 修改每一个字符
for (int j = 0; j < wordLen; j++) {
// 一轮以后应该重置,否则结果不正确
char originChar = charArray[j];
for (char k = 'a'; k <= 'z'; k++) {
if (k == originChar) {
continue;
}
charArray[j] = k;
String nextWord = String.valueOf(charArray);
if (wordSet.contains(nextWord)) {
if (nextWord.equals(endWord)) {
return step + 1;
}
if (!visited.contains(nextWord)) {
queue.add(nextWord);
// 注意:添加到队列以后,必须马上标记为已经访问
visited.add(nextWord);
}
}
}
// 恢复
charArray[j] = originChar;
}
}
step++;
}
return 0;
}
public static void main(String[] args) {
String beginWord = "hit";
String endWord = "cog";
List<String> wordList = new ArrayList<>();
String[] wordListArray = new String[]{"hot", "dot", "dog", "lot", "log", "cog"};
Collections.addAll(wordList, wordListArray);
Solution solution = new Solution();
int res = solution.ladderLength(beginWord, endWord, wordList);
System.out.println(res);
}
}
方法二:双向广度优先遍历
- 已知目标顶点的情况下,可以分别从起点和目标顶点(终点)执行广度优先遍历,直到遍历的部分有交集。这种方式搜索的单词数量会更小一些;
- 更合理的做法是,每次从单词数量小的集合开始扩散;
- 这里
beginVisited和endVisited交替使用,等价于单向 BFS 里使用队列,每次扩散都要加到总的visited里。
参考代码 2:
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
Set<String> wordSet = new HashSet<>(wordList);
if (wordSet.size() == 0 || !wordSet.contains(endWord)) {
return 0;
}
// 标准写法,总的 visited 数组
Set<String> visited = new HashSet<>();
// 分别用左边和右边扩散的哈希表代替单向 BFS 里的队列
Set<String> beginVisited = new HashSet<>();
beginVisited.add(beginWord);
Set<String> endVisited = new HashSet<>();
endVisited.add(endWord);
int len = beginWord.length();
int step = 1;
while (!beginVisited.isEmpty() && !endVisited.isEmpty()) {
// 打开以方便调试
// System.out.println("beginVisited => " + beginVisited);
// System.out.println(" endVisited => " + endVisited + "\n");
// 优先选择小的哈希表进行扩散,考虑到的情况更少
if (beginVisited.size() > endVisited.size()) {
Set<String> temp = beginVisited;
beginVisited = endVisited;
endVisited = temp;
}
// 逻辑到这里,保证 beginVisited 是相对较小的集合
// nextLevelVisited 在扩散完成以后,会成为新的 beginVisited
Set<String> nextLevelVisited = new HashSet<>();
for (String word : beginVisited) {
char[] charArray = word.toCharArray();
for (int i = 0; i < len; i++) {
char originChar = charArray[i];
for (char c = 'a'; c <= 'z'; c++) {
if (originChar == c) {
continue;
}
charArray[i] = c;
String nextWord = String.valueOf(charArray);
if (wordSet.contains(nextWord)) {
if (endVisited.contains(nextWord)) {
return step + 1;
}
if (!visited.contains(nextWord)) {
nextLevelVisited.add(nextWord);
visited.add(nextWord);
}
}
}
// 恢复,下次再用
charArray[i] = originChar;
}
}
// 这一行代表表示从 begin 这一侧向外扩散了一层
beginVisited = nextLevelVisited;
step++;
}
return 0;
}
public static void main(String[] args) {
List<String> wordList = new ArrayList<>();
String[] words = {"hot", "dot", "dog", "lot", "log", "cog"};
Collections.addAll(wordList, words);
Solution solution = new Solution();
String beginWord = "hit";
String endWord = "cog";
int ladderLength = solution.ladderLength(beginWord, endWord, wordList);
System.out.println(String.format("从 %s 到 %s 的最短转换序列的长度:%d。", beginWord, endWord, ladderLength));
}
}