Java 语言全文检索技术
Lucene
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
ElasticSearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题。
ElasticSearch 安装配置使用入门
下载地址 Window 系统下载 zip 版本,linux 系统下载 tar 版本

bin 存放 elasticSearch 运行命令
config 存放配置文件
lib 存放 elasticSearch 运行依赖 jar 包
modules 存放 elasticSearch 模块
plugins 存放插件
在bin目录下运行elasticSearch 访问 http://127.0.0.1:9200 将会看到下面的页面

ElasticSearch 插件安装 es head
在ElasticSearch bin目录下运行cmd,输入 plugin.bat install mobz/elasticsearch-head
访问 http://localhost:9200/_plugin/head/ 出现下面的页面
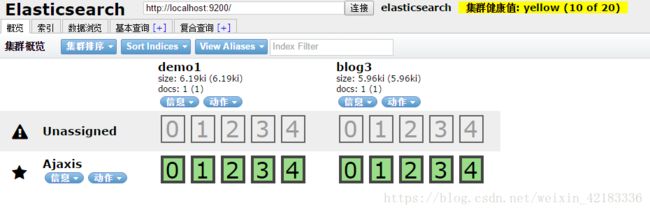
ElasticSearch 基础 数据架构的主要概念
索引对象: 存储数据的表结构 ,任何搜索数据,存放在索引对象上
映射: 数据如何存放到索引对象上,需要有一个映射配置, 数据类型、是否存储、是 否分词 …
文档: 一条数据记录, 存在索引对象上
文档类型: 一个索引对象 存放多种类型数据, 数据用文档类型进行标识 编程: 建立索引对象 --- 建立映射 --- 存储数据【文档】 --- 指定文档类型进行搜索数 据【文档】
图解

使用步骤
1、 需要新建 maven 项目
2、 基于 maven 的 pom 导入坐标依赖
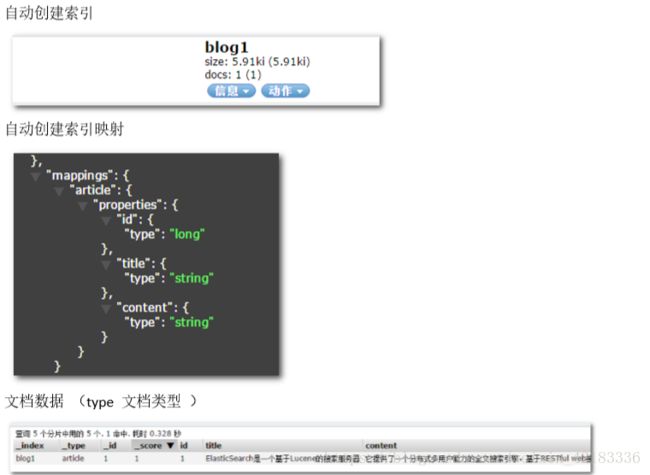
当直接在 ElasticSearch 建立文档对象时,如果索引不存在的,默认会自动创建,映射采用默 认方式
ElasticSearch 服务默认端口 9300 Web 管理平台端口 9200
3、 建立文档, 自动创建索引
// 直接在ElasticSearch中建立文档,自动创建索引
public void demo1() throws IOException {
// 创建连接搜索服务器对象
Client client = TransportClient
.builder()
.build()
.addTransportAddress(
new InetSocketTransportAddress(InetAddress
.getByName("127.0.0.1"), 9300));
// 描述json 数据
/*
* {id:xxx, title:xxx, content:xxx}
*/
XContentBuilder builder = XContentFactory
.jsonBuilder()
.startObject()
.field("id", 1)
.field("title", "ElasticSearch是一个基于Lucene的搜索服务器")
.field("content",
"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。")
.endObject();
// 建立文档对象
client.prepareIndex("blog1", "article", "1").setSource(builder).get();
// 关闭连接
client.close();
}
搜索文档数据
查询数据 主要依赖 QueryBuilder 对象 ,可以通过 QueryBuilders 获取
boolQuery() 布尔查询,可以用来组合多个查询条件
fuzzyQuery() 相似度查询
matchAllQuery() 查询所有数据
regexpQuery() 正则表达式查询
termQuery() 词条查询
wildcardQuery() 模糊查询
搜索创建的文档对象
// 搜索在elasticSearch中创建文档对象
public void demo2() throws IOException {
// 创建连接搜索服务器对象
Client client = TransportClient
.builder()
.build()
.addTransportAddress(
new InetSocketTransportAddress(InetAddress
.getByName("127.0.0.1"), 9300));
// 搜索数据
// get() === execute().actionGet()
SearchResponse searchResponse = client.prepareSearch("blog1")
.setTypes("article").setQuery(QueryBuilders.matchAllQuery())
.get();
printSearchResponse(searchResponse);
// 关闭连接
client.close();
}各种查询对象 Query 的使用
1、ElasticSearch 提供 QueryBuileders.queryStringQuery(搜索内容) 查询方法,对所有字段进 行分词查询
SearchResponse searchResponse = client.prepareSearch("blog1")
.setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("全面")).get();2、 只想查询 content 里包含全文 ,使用 wildcardQuery 磨合查询 *任意字符串 ?任意单个 字符
SearchResponse searchResponse = client.prepareSearch("blog1")
.setTypes("article")
.setQuery(QueryBuilders.wildcardQuery("content", "*全文*")).get();3、 查询 content 词条为“搜索” 内容,使用 TermQuery
SearchResponse searchResponse = client.prepareSearch("blog2")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("content", "搜索")).get();IK 分词器和 ElasticSearch 集成使用
下载地址
安装步骤
1、 下载开源项目
2、 打包 ik 分词器 mvn clean 清空 mvn package 打包
3、 进入 target/release 目录 将下列文件 ,拷贝到 %es%/plugins/analysis-ik

4、 进入 target/release/config 目录 将所有配置文件,复制 %es%/config 下
5、 配置 elasticsearch.yml
![]()
6、 重启 es
7、 访问 http://localhost:9200/_analyze?analyzer=ik&pretty=true&text=我是中国人
可以看到数据分词成功

文档相关操作
建立文档
1、 直接在 XContentBuilder 中构建 json 数据,建立文档
2、 对一个已经存在对象,转换为 json ,建立文档
修改文档
方式一: 使用 prepareUpdate、prepareIndex 都可以
方式二: 直接使用 update
删除文档
方式一: prepareDelete
方式二:直接使用 delete
Spring Data ElasticSearch 入门案例
1、 创建 maven 工程
2、 基于 maven 导入坐标 Spring data elasticsearch 对 elasticsearch api 简化封装
3、 在 src/main/resources 下建立 applicationContext.xml 和 log4j.properties 引入 spring data elasticsearch 名称空间
4、 创建 domain、dao、service 包
5、 编写 DAO 自动操作 elasticsearch 继承 ElasticsearchRepository 接口
public interface ArticleRepository extends
ElasticsearchRepository {
} 6、 编写 Service
@Autowired
private ArticleRepository articleRepository;
public void save(Article article) {
articleRepository.save(article);
}8、 索引和映射如何创建 --- 基于 spring data elasticsearch 注解 在使用 spring data elasticsearch 开发, 需要将索引和映射信息 配置实体类上面
@Document 文档对象 (索引信息、文档类型 )
@Id 文档主键 唯一标识
@Field 每个文档的字段配置(类型、是否分词、是否存储、分词器 )
@Document(indexName = "blog3", type = "article")
public class Article {
@Id
@Field(index = FieldIndex.not_analyzed, store = true, type = FieldType.Integer)
private Integer id;
@Field(index = FieldIndex.analyzed, analyzer = "ik", store = true, searchAnalyzer = "ik", type = FieldType.String)
private String title;
@Field(index = FieldIndex.analyzed, analyzer = "ik", store = true, searchAnalyzer = "ik", type = FieldType.String)
private String content;9、编写测试代码
public void testSave() {
Article article = new Article();
article.setId(1001);
article.setTitle("Spring Data Elasticsearch 1.3.1 昨天发布");
article.setContent("DATAES-171 - 添加失效查询关键字支持 DATAES-194 - 测试可以清理 data 目录 DATAES-179 - 支持 Attachment 字段类型 DATAES-94 - 更新到最新版本的 elasticsearch 1.7.3 驱动器");
articleService.save(article);
}