mysql基础学习笔记
个人的学习笔记,供大家进行参考,如有错误欢迎指出
1. mysql服务端的启动命令
mysql -h localhost -P 3306 -u root -p ******
2. mysql的系统配置
PATH 对应 C://Prohram File(x86)\MySQL\MySQL Server 5.5\bin;
3. 相关命令
1. 查看所有数据库
show databases;
2. 选中数据库
use 【database】;
3. 查看所有表
show tables;
show tables from [database];
4. 查看当前所在库
select database();
5.查看数据库的版本
select version();
6. 创建表
create table 表名 (
列名 列类型;
列名 列类型;
…
)
7. 查看表结构
desc 表名;
4. mysql的语法规范
- 不区分大小写,但是建议关键字大写,表名、列名小写
- 每条命令最好用分号结尾
- 每条命令根据需要,可以进行缩进或换行
- 注释;;单行注释:#文字,,,-- 注释文字;;多行注释:/* 注释文字 */
5. 常见数据类型
1. 数值型
1)整型
如何设置有符号或者无符号
无符号:t int unsigned
| 整数类型 | 字节 | 范围 |
|---|---|---|
| Tinyint | 1 | 有符号:-128~127 无符号:0~255 |
| Smallint | 2 | 有符号:-32768~32767 无符号 |
| Mediumint | 3 | 很大 |
| Int、integer | 4 | 很大 |
| Bigint | 8 | 很大 |
2)小数
-
定点数
DEC(M,D);DECIMAL(M,D):M+2字节;;;默认D,M为(10,0)
-
浮点数
float(M,D):4字节
double(M,D):8字节
D:小数点后边保留几位
M:一共有几位数
2. 字符型
1)较短的文本
1. char(M):M:最多的字符数;;固定长度的字符;效率较高;字符数固定的时候用
2. varchar(M):M:最多的字符数;可变长度的字符;效率较低;字符数不固定的时候用
3. enum(‘’,‘’,...):枚举类型,只能是括号里边的数据
4. set:用于保存集合类型
5. binary:保存二进制
6. varbinary:保存二进制
2)较长的文本
- text
3.日期型
| 日期和时间类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| date只保存日期 | 4 | 1000-01-01 | 9999-12-31 |
| datetime保存日期+时间 | 8 | 1000-01-01 00:00:00 | 9999-12-31 23:59:59 |
| timestamp保存日期+时间 | 4 | 2038年的某个时刻 | |
| time只保存时间 | 3 | -838:59:59 | 838:59:59 |
| year只保存年 | 1 | 1901 | 2155 |
6. DQL语言
1. 基础查询
- SELECT 查询列表 FROM 表名;一般查询;查询列表可以是:表中的字段、常量值、表达式、函数;;;F9执行,F12格式化
- SELECT 查询列表 AS 别名;取别名;便于理解,用于区分,,使用AS 或者 空格都可以
- SELECT DISTINCT 查询列表 FROM 表名; 去重;
- SELECT CONCAT(查询列表,查询列表) AS 别名;拼接;比如拼接姓和名
- SELECT IFNULL(字段,要改为什么);进行字段判断是否为null,以及修改成的内容
2. 条件查询
-
SELECT 查询条件 FROM 表名,WHERE 筛选条件;;
条件表达式:> < = != <> >= <=
逻辑表达式:&& || !
模糊查询:like,between and, in , is null,
<=>,等于。即可以判断NULL值,又可以判断普通的数值
escaps 转义
<>为不等于
如果字段跟关键字重名,用1前面的··反引号。
3. 排序查询
-
SELECT 查询列表 FROM 表 【WHERE 筛选条件】ORDER BY 排序列表【asc 升序|desc 降序】
支持单个字段,多个字段,表达式,函数,别名
放在查询语句的最后边
4. 常见函数
4.1单行函数:
1.字符函数:
1)length:获取参数值的字节数::
select length(‘’);
2)concat:拼接字符:
select concat(‘’,‘’,‘’,…);
3)upper,lower:大小写转换:
select upper(‘’)
4)substr,substring
select substr(‘我是xxx’,3);结果为:xxx。索引从1开始
select substr(‘我是xxx’,3,3);结果为:xxx。从第几个开始,取几个
5)instr
select instr(‘我是xxx’,‘xxx’);结果为:3。后边字符在前面第一次出现的位置,没有则返回0
6)trim
select trim(‘a’ from ‘aaaaaajaaajjaaaaaaaa’);结果为:jaaajj。去掉字符前后的a
7)lpad
select lpad(‘jjj’,10,’*’);结果为:*******jjj。用指定的字符实现左填充,要是规定的长度小于字符则截取相应大小的字符
8)rpad
select rpad(‘jjj’,10,’*’):右填充。
9)replace
select replace(’’,’’);全部替换
2.数学函数:
1)round:四舍五入
select round(1.56);
select round(1.56,2);
2)ceil:向上取整,返回>=该参数的最小整数
select ceil(1.00)
3)floor:向下取整,返回<=该参数的最大整数
4)truncate:截断
select truncate(1.69999,2); 结果为:1.6
5)mod:取余=%
select mod(10,3)
6)rand:获取随机数
返回0-1之间的小数
3.日期函数:
1)now :返回当前系统日期和时间
select now();
2)curdate: 返回当前系统的日期,不包含时间
select curdate();
3)curtime:返回当前时间,不包含日期
select curtime();
4)获取指定的部分,年year、月、日、时、分、秒
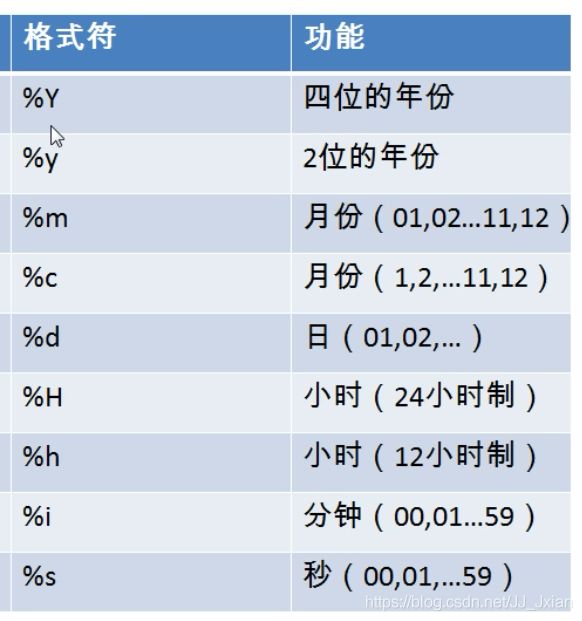
5)str_to_date:将日期格式的字符转换成指定格式的日期
select str_to_date(‘9-13-1998’,’%m-%d-%Y’)
6)date_format:将日期转成字符、
select date_format(‘2018/06/06’,’%Y年%月%日’)
7)datadiff(expr,expr2)
8)monthname:以英文形式返回月
4.其他函数:
version:
database:
user:
password:
md5:
5.流程控制函数:
1)if函数:if else的效果
if(表达式1,表达式2,表达式3);
2)case函数,switch case
case 表达式 when常量1 then 要显示的值或语句 … end;
4.2分组函数:
用作统计使用,又称聚合函数、统计函数、组函数
1)sum 求和
2)avg 求平均值
3)max 最大
4)min 最小
5)count 计数
一般使用count(*)统计行数
特点:
sum、avg一般用于处理数值型;
max、min、count可以处理任何类型;
分组函数忽略null值;
可以和distinct搭配实现去重;
和分组函数异同查询的字段要求是group by 后的字段
5. 分组查询
select 分组函数,列(要求出现在group by的后边) from 表 【where 筛选条件】 group by 分组的列表 【order by 句子】 ;
select max(salary),job_id from employees group by job_id;
select count(*),department_id from employees group by department_id having count(*)>2;
特点
1)筛选条件分为两种:
| 数据源 | 位置 | 关键字 | |
|---|---|---|---|
| 分组前筛选 | 原始表 | group by 字句的前边 | where |
| 分组后筛选 | 分组后的结果集 | group by 字句的后面 | having |
2)分组函数做条件肯定是放在having字句中
3)能用分组前筛选的,就优先考虑使用分组前筛选
4)group by 字句支持单个字段分组,多个字段分组
6. 连接查询
多表查询,
6.1 笛卡尔积
select name ,boyname from b1,b2;
b1表n行,b2表m行,最终的连接查询结果是n*m行结果
原因:没有有效的连接条件;;避免:添加有效的连接条件
6.2 内连接
select 查询条件 from inner jion 表2 别名 on 连接条件
1)等值连接
SELECT s_name,t_name FROM student s,teacher t WHERE s.t_id = t.t_id;
特点:
- 多表等值连接的结果为多表的交集部分
- n表连接,至少需要n-1个连接条件
- 多表的顺序没有要求
- 一般需要为表取别名
- 可以搭配前面介绍的所有字句使用,比如排序,分组,筛选
2)非等值连接
select salary,grade_level from employees e,job_grades g where salary between g.‘lowest_sal’ and g.‘highest_sal’
3)自连接
SELECT p.name自己 ,e.name领导 FROM person p ,person e WHERE p.pre = e.id
6.3 外连接
select 查询列表 from 表1 别名 【连接类型】 join 表2 别名 on 连接条件 …
用于查询一个表中有,另一个表中没有的记录
外连接的查询结果为主表中的所有记录,如果从表中有和它匹配,则显示匹配的值,如果从表中没有和他匹配的值则显示null,外连接的结果为=内连接结果+主表中有而从表中没有的记录
1)左外连接 :left 【outer】 left左边的是主表
select xx.xx from xx left outer join xx on xx.xx = xx.xx …;
2)右外连接:right 【outer】 right右边的是主表
select xx.xx from xx right outer join xx on xx.xx = xx.xx …;
3)全外连接:full 【outer】
6.4 交叉连接
7. 子查询
出现在其他语句中的select语句,为子查询或者内查询
7.1 分类
1.按查询出现的位置
select 后边:仅仅支持标量子查询
from后边:支持表子查询
*****where或having后边:
- 标量子查询(单行)
- 列子查询(多行)
- 行子查询(多行多列)
exists后边(相关子查询):表子查询
2.按结果集的行列数不同:
标量子查询:(结果为一行一列)
列子查询
行子查询:
表子查询:
*where或having
**特点:**子查询放在小括号内;
子查询一般放在条件的右侧;
标量子查询,一般搭配着单行操作符来使用(>,<,>=,<=,=,<>);
列子查询,一般搭配着多行操作符使用(in,not in,any,some,all)
子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
标量,select * from empolyees where salary < ( select salary from employee where last_name = ‘jjx’ );
列,
8. 分页查询 *
select 查询列表 from 表 【join type join 表2 on连接条件 where 筛选条件 group by 分组字段 having 分组后的筛选 order by 排序字段 】 limit offset,size;
特点:
- limit语句放在查询语句的最后
- 公式:select 查询条件 from 表 limit(page-1)*size ,size;
9. union联合查询
将多条查询语句的结果合并成一个结果
select * from employees where email like ‘%a%’
union
select * from employees where email department_id > 90
特点:
- 要求多条查询语句的查询列数是一致的
- 要求多条查询语句的查询的每一列的类型和顺序最好一致
- union关键字默认是去重的,union all 是显示所有
7. DML语言
1. 插入
-
insert into 表名(列名,列名,…) values(值1,…) ;
-
insert into 表名 set 列名=值,列名=值,…;
方式一支持插入多行;方式二支持子查询0
2. 修改
1. update 表名 set 列 = 新值.... where 筛选条件;
2. update 表1 别名 inner|left|right join 表2 别名 on 连接条件 set 列 = 值 where 筛选条件;
3. 删除
1. delete from 表名 where 筛选条件
2. truncate table 表名【删除表的所有数据】
3. delete 表1,表2 from 表1 inner|left|right join 表2 别名 on 连接条件
1)delete删除数据后,在插入,自增序列的值从断点开始
2)truncate删除数据后,在插入数据,自增长列的值从1开始
3)truncate 没有返回值,delete有返回值 返回行数
8. DDL语言
数据定义语言
1. 库
1) 创建:create
- 创建数据库:create database 库名;
- 创建数据库不报错:create database if not null 库名;
2)修改:alter
- 修改库的字符集:alter database 库名 character set 字符集;
3)删除:drop
- drop databse 库名;
2. 表
1)表的创建
- create table 表名(列名 列的类型【(长度)约束】,…);
2)表的修改
- 修改列名:alter table 表名 change column 旧列名 新列名 类型;
- 修改列的类型或约束:alter table 表名 modify column 列名 类型;
- 添加新列:alter table 表名 add column 列名 类型;
- 删除列:alter table 表名 drop column 列名 ;
- 修改表名:alter table 表名 rename to 表名;
3)表的删除
1. drop table 表名;
4)表的复制
- create table 表名 like 要复制的表名;只复制表的结构(全部)
- create table 表名 select 字段名,字段名 from 表名 where 1=2;复制部分表结构,不复制数据
- create table 表名 select * from 要复制的表名;复制结构和数据
3. 常见约束
是一种限制,用于限制表中的数据,为了保存表中的数据的准确性和可靠性。
create table 表名(
字段名,字段类型,列级约束,
字段名,字段类型,
…
表级约束
)
1)约束的分类
- not null:非空,
- default :默认,保证该字段有默认值
- primary key:主键,用于保证该字段的唯一性,非空
- unique:唯一,用于保证该字段的值具有唯一性,可以为空,比如座位号。
- check:检查约束【mysql中不支持,没有效果】
- foreign key:外键约束,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值,在从表添加外键约束,主表的被引用列要求是一个key。
2)添加约束的时机
- 创建表时
- 修改表时
3)约束的添加分类
-
列级约束
6个约束语法上都支持,外键约束没有效果
-
表级约束
除了非空和默认其他的都支持
constraint pk primary key (id)主键
contratint fk_stuinfo_major foreign key (majorid) references major(id)外键
4)主键和唯一键的区别
| 保证唯一性 | 是否允许为空 | 一个表中可以有多少个 | 是否允许组合 | |
|---|---|---|---|---|
| 主键 | √ | × | 至多一个 | √,不推荐 |
| 唯一 | √ | √ | 可以有多个 | √,不推荐 |
唯一约束的字段不能有两个null值,视为重复
5)外键:
- 要求在从表设置外键关系
- 从表的外键列的类型和主表的关联列的类型要求是一致或者兼容,名称无要求
- 主表的关联列必须是一个key(一般是主键或者唯一键)
- 插入数据时,先插入主表,在插入从表;删除数据时,先删除从表在删除主表。
6)修改表示添加约束
-
添加列级约束
alter table 表名 modify column 字段名 字段类型 新约束
-
添加表级约束
alter table 表名 add 【constraint 约束名】约束类型(字段名)【外键的引用】
7)级联删除和更新
级联删除:alter table 表名 add constration 约束名 foreign key(从表) references 主表 on delete cascade;
级联置空:alter table 表名 add constration 约束名 foreign key(从表) references 主表 on delete set null;
4. 标识列:自动增长:auto_increment
5. 小总结
通用写法
drop database if exists 数据库名 ;
create database 数据库名;
表同理
9. TCL语言
事务控制语言
1. 事务
一个或者一组sql语句组成一个执行单元,这个执行单元要么全部执行,要不全部不执行。
2. 事务的ACID(acid)属性
1)原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2)一致性(Consistency)
事务必须使数据库从一个一致性状态转换到另一个一致性状态。比如转账,转账之前两个人一共是2000,转后也是2000。
3)隔离性(Isolation)
事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能相互干扰。
4)持久性(Durability)
持久性是指一个事务一旦被提交,他对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该其有任何影响。
3. 事务的创建
**隐式事务:**事务没有明显的开启和结束的标记;比如insert、update、delete语句
**显示事务:**事务具有明显的开启和计数的标记
前提:必须先设置自动提交功能为禁用
步骤:
- 开启事务:set autocommit=0; start transaction;(可选)
- 编写事务中的sql语句:(insert、update、select、delete)
- 结束事务:commit;提交事务,,或者roolback;回滚事务。或者rollback to 回滚点名;
4. 数据库的并发
对于同时运行的多个事务,就这些事物访问数据库中相同的数据时,如果没有采取必要的隔离机制,就会导致各种并发问题:
1)脏读:对于两个事务T1、T2,T1读取了已经被T2更新但是还没有被提交的字段之后,若T2回滚,T1读取的内容就是临时且无效的。
2)不可重复读:对于两个事务T1、T2,T1读取了一个字段,然后T2更新了该字段之后,T1再次读取同一个字段,值就不一样了。
3)幻读:对于两个事务T1、T2,T1从一个表中读取了一个字段,然后T2在该表中插入了一些新的行之后,如果T1再次读取同一个表,就会多出几行。

查看当前的隔离级别:select @@tx_isolation;
设置当前mysql连接的隔离级别:set transaction isolation level read committed;
设置数据库系统的全局的隔离级别:set global transactionisolation leve read committed;
savepoint 节点名;:设置保存点
5. delete和truncate在事务中的区别
delete的执行在回滚,数据不会被删除。
truncate执行完之后再回滚,数据会被删除;
10. 视图
虚拟表,和普通表一样使用,通过表动态生成的数据;只保存了sql逻辑,不保存查询结果
1)创建视图
create view 视图名 as 查询语句;
2)使用场景
重复的sql语句可以创建一个视图
简化复杂的sql操作
保护数据,提高安全性
3)视图的修改
create or replace view 视图名 as 查询语句;
alter view 视图名 as 查询语句;
4)删除视图
drop view 视图名,视图名…;
5)查看视图
desc 视图名;
show create view 视图名;
6)视图的更新
- 插入:insert into 视图名 values(‘’,’‘,’‘,…);(原表也会插入相应的字段)
- 修改:update 视图名 set 字段名=值,… where 字段名 = 值;(原表也会更新相应的字段)
- 删除:delete from 视图名 where 条件;(原表也会删除相应的字段)
这样不安全,且不适用于所有的视图,可以添加只读的权限。
11. 变量
**系统变量:**变量由系统提供
1. 全局变量:作用域:跨连接,不跨重启
2. 会话变量:作用域:仅仅对当前会有有效
1)查看所有的系统变量:show 【global|session】 variables;
2)查看满足条件的部分系统变量:show 【global|session】 variables like ‘%char%’;
3)查看指定的某个系统变量的值:select @@【global|session】.系统变量名;
4)为某个系统变量赋值:set 【global |session】 系统变量名 = 值;;;set @@【global |session】 系统变量名 = 值
自定义变量:
1)用户变量:作用域:针对于当前会话(连接)有效
声明和初始化:set @用户变量名 = 值;;set @用户变量名 := 值;;select @用户变量名 := 值;
赋值:set @用户变量名 = 值;;set @用户变量名 := 值;;select @用户变量名 := 值;;select 字段 into 变量名 from 表;
使用(查看):select @用户变量名
2) 局部变量:仅仅在定义他的begin end 中有效
声明: declare 变量名 类型;; declare 变量名 类型 default 值;
赋值:set 局部变量名 = 值;;set 局部变量名 := 值;;select @局部变量名 := 值;;select 字段 into 局部变量名 from 表;
使用:select 局部变量名;
11. 存储过程和函数
类似于java的方法
1. 存储过程:
一组预先编译好的sql语句的集合,理解成批处理语句
创建“”create procedure 存储过程(参数列表) begin 存储过程(一组合法的sql语句) end
注意:参数列表包含三个部分:参数模式,参数名,参数类型。
- 参数模式:in :该参数可以作为输入 out:该参数可以作为输出,返回值 inout:既可以传入值又可以返回值
- 设置结束符号:delimiter:你的符号
**调用:**call 存储过程名(实参列表);
**删除存储过程:**drop procedure 存储过程名;一次只能删一个
**查看存储过程信息:**show create procedure 存储过程名;
2. 函数
有且仅有一个返回值,适合做处理数据后返回一个结果
创建:create function 函数名(参数列表) returns 返回类型 begin 函数体 end
调用:select 函数名(参数列表)
查看:show create function 函数名;
删除:drop function 函数名;
12. 流程控制结构
1. 顺序结构:
程序从上到下依次执行
2. 分支结构:
程序从两条或者多条路径中选择一条去执行
1)if函数
if(表达式1,表达式2,表达式3)
if 条件1 then 语句1;elseif 条件2 then 语句2; … else 语句n; end if ;
2)case结构
类似于java的switch
类似多重if-判断

3. 循环结构:
程序在满足一定条件的基础上,重复执行一段代码
-
while、
【标签:】while 循环条件 do
循环体
end while 【标签】;
-
loop、
【标签:】loop
循环体;
end loop 【标签】;
可以用来模拟死循环。用leave跳出循环
-
repeat、
【标签:】repeat
循环体;
until 结束循环条件
end repeat【标签】;
循环控制:
iterate类似于 coutinue,继续,结束本次循环,继续下一次
leave 类似于 break;跳出 ,结束当前所在的循环