MySQL在线表结构变更工具
MySQL的大表表结构变更常用的解决方案无外乎三种:
一是利用Percona的pt-online-schema-change,Facebook的OSC等三方工具,
二是在备库修改通过切换实现滚动变更,
三则是升级MySQL到5.6/5.7通过官方Online DDL实现部分变更。
然而,引入触发器带来的锁竞争问题,主备切换带来的附加成本以及Online DDL的局限性都不让DBA省心。
gh-ost不依赖于触发器,通过模拟从库,在row binlog中获取增量变更,再异步应用到ghost表。
gh-ost
gh-ost GitHub 的在线 Schema 修改工具,下面工作原理图:
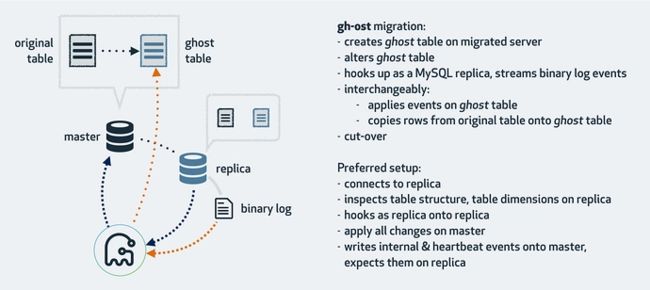
gh-ost 具有如下特性:
-
无触发器
-
轻量级
-
可暂停
-
可动态控制
-
可审计
-
可测试
-
值得信赖
无触发器
gh-ost 没有使用触发器。它通过分析binlog日志的形式来监听表中的数据变更。因此它的工作模式是异步的,只有当原始表的更改被提交后才会将变更同步到临时表(ghost table)
gh-ost 要求binlog是RBR格式 ( 基于行的复制);然而也不是说你就不能在基于SBR(基于语句的复制)日志格式的主库上执行在线变更操作。实际上是可以的。gh-ost 可以将从库的 SBR日志转换为RBR日志,只需要重新配置就可以了。
轻量级
由于没有使用触发器,因此在操作的过程中对主库的影响是最小的。当然在操作的过程中也不用担心并发和锁的问题。 变更操作都是以流的形式顺序的写到binlog文件中,gh-ost只是读取他们并应用到gh-ost表中。实际上,gh-ost 通过读取binlog的写事件来进行顺序的行复制操作。因此,主库只会有一个单独连接顺序的将数据写入到临时表(ghost table)。这和ETL操作有很大的不同。
可暂停
所有的写操作都是由gh-ost控制的,并且以异步的方式读取binlog,当限速的时候,gh-ost可以暂停向主库写入数据,限速意味着不会在主库进行复制,也不会有行更新。当限速时gh-ost会创建一个内部的跟踪(tracking)表,以最小的系统开销向这个表中写入心跳事件
gh-ost 支持多种方式的限速:
-
负载: 为熟悉
pt-online-schema-change工具的用户提供了类似的功能,可以设置MySQL中的状态阈值,如 Threads_running=30 -
复制延迟:
gh-ost内置了心跳机制,可以指定不同的从库,从而对主从的复制延迟时间进行监控,如果达到了设定的延迟阈值程序会自动进入限速模式。 -
查询: 用户可以可以设置一个限流SQL,比如
SELECT HOUR(NOW()) BETWEEN 8 and 17这样就可以动态的设置限流时间。 -
标示文件: 可以通过创建一个标示文件来让程序限速,当删除文件后可以恢复正常操作。
-
用户命令: 可以动态的连接到
gh-ost(下文会提到) 通过网络连接的方式实现限速。
可动态控制
现在的工具,当执行操作的过程中发现负载上升了,DBA不得不终止操作,重新配置参数,如 chunk-size,然后重新执行操作命令,我们发现这种方式效率非常低。
gh-ost 可以通过 unix socket 文件或者TCP端口(可配置)的方式来监听请求,操作者可以在命令运行后更改相应的参数,参考下面的例子:
-
echo throttle | socat - /tmp/gh-ost.sock打开限速,同样的,可以使用no-throttle来关闭限流。 -
改变执行参数:
chunk-size=1500,max-lag-millis=2000,max-load=Thread_running=30这些参数都可以在运行时变更。
可审计
同样的,使用上文提到的程序接口可以获取 gh-ost 的状态。gh-ost 可以报告当前的进度,主要参数的配置以及当前服务器的标示等等。这些信息都可以通过网络接口取到,相对于传统的tail日志的方式要灵活很多。
可测试
因为日志文件和主库负载关系不大,因此在从库上执行修改表结构的操作可以更真实的体现出这些操作锁产生的实际影响。(虽然不是十分理想,后续我们会做优化工作)。
gh-ost 內建支持测试功能,通过使用 --test-on-replica 的参数来指定: 它可以在从库上进行变更操作,在操作结束时gh-ost 将会停止复制,交换表,反向交换表,保留2个表并保持同步,停止复制。可以在空闲时候测试和比较两个表的数据情况。
这是我们在GitHub的生产环境中的测试:我们生产环境中有多个从库;部分从库并不是为用户提供服务的,而是用来对所有表运行的连续覆盖迁移测试。我们生产环境中的表,小的可能没有数据,大的会达到数百GB,我们只是做个标记,并不会正在的修改表结构(engine=innodb)。当每一个迁移结束后会停止复制,我们会对原表和临时表的数据进行完整的checksum确保他们的数据一致性。然后我们会恢复复制,再去操作下一张表。我们的生产环境的从库中已经通过 gh-ost 成功的操作了很多表。
值得信赖
上文提到说了这么多,都是为了提高大家对 gh-ost 的信任程度。毕竟在业界它还是一个新手,类似的工具已经存在了很多年了。
-
在第一次试手之前我们建议用户先在从库上测试,校验数据的一致性。我们已经在从库上成功的进行了数以千计的迁移操作。
-
如果在主库上使用
gh-ost用户可以实时观察主库的负载情况,如果发现负载变化很大,可以通过上文提到的多种形式进行限速,直到负载恢复正常,然后再通过命令微调参数,这样可以动态的控制操作风险。 -
如果迁移操作开始后预完成计时间(ETA)显示要到夜里2点才能完成,结束时候需要切换表,你是不是要留下来盯着?你可以通过标记文件让gh-ost推迟切换操作。gh-ost 会完成行复制,但并不会切换表,它会持续的将原表的数据更新操作同步到临时表中。你第二天来到办公室,删除标记文件或者通过接口
echo unpostpone告诉gh-ost开始切换表。我们不想让我们的软件把使用者绑住,它应该是为我们拜托束缚。 -
说到 ETA,
--exact-rowcount参数你可能会喜欢。相对于一条漫长的SELECT COUNT(*)语句,gh-ost 会预估出迁移操作所需要花费的时间,还会根据当前迁移的工作状况更新预估时间。虽然ETA的时间随时更改,但进度百分比的显示是准确的。
gh-ost 操作模式
gh-ost 可以同时连接多个服务器,为了获取二进制的数据流,它会作为一个从库,将数据从一个库复制到另外一个。它有各种不同的操作模式,这取决于你的设置,配置,和要运行迁移环境。
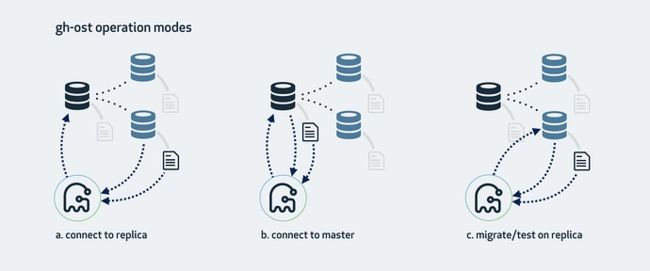
a. 连接到从库,在主库做迁移
这是 gh-ost 默认的工作方式。gh-ost 将会检查从库状态,找到集群结构中的主库并连接,接下来进行迁移操作:
-
行数据在主库上读写
-
读取从库的二进制日志,将变更应用到主库
-
在从库收集表格式,字段&索引,行数等信息
-
在从库上读取内部的变更事件(如心跳事件)
-
在主库切换表
如果你的主库的日志格式是 SBR,工具也可以正常工作。但从库必须启用二级制日志(log_bin, log_slave_updates) 并且设置 binlog_format=ROW ( gh-ost 是读取从库的二级制文件)。
如果直接在主库上操作,当然也需要二进制日志格式是RBR。
b. 连接到主库
如果你没有从库,或者不想使用从库,你可以直接在主库上操作。gh-ost 将会直接在主库上进行所有操作。你需要持续关注复制延迟问题。
-
你的主库的二进制日志必须是 RBR 格式。
-
在这个模式中你必须指定
--allow-on-master参数
c. 在从库迁移/测试
该模式会在从库执行迁移操作。gh-ost 会简单的连接到主库,此后所有的操作都在从库执行,不会对主库进行任何的改动。整个操作过程中,gh-ost 将控制速度保证从库可以及时的进行数据同步
-
--migrate-on-replica表示 gh-ost 会直接在从库上进行迁移操作。即使在复制运行阶段也可以进行表的切换操作。 -
--test-on-replica表示 迁移操作只是为了测试在切换之前复制会停止,然后会进行切换操作,然后在切换回来,你的原始表最终还是原始表。两个表都会保存下来,复制操作是停止的。你可以对这两个表进行一致性检查等测试操作。
gh-ost at GitHub
我们已经在所有线上所有的数据库在线操作中使用了gh-ost ,我们每天都需要使用它,根据数据库修改需求,可能每天要运行多次。凭借其审计和控制功能我们已经将它集成到了ChatOps流程中。我们的工程师可以清醒的了解到迁移操作的进度,而且可以灵活的控制其行为。
开源
gh-ost 在MIT的许可下发布到了开源社区。
https://www.cnblogs.com/zhoujinyi/p/9187502.html
https://yq.aliyun.com/articles/62928