ssd_detect用训练好的模型识别图片中的类
用shell script语言完成大批量图片检测,并将结果(图片中所包含类别及其坐标)打印在txt文本内保存
用python语言完成单张图片检测,并将结果(图片中所包含类别及其坐标)以图片形式展示
用python语言完成多张图片检测,并将结果(图片中所包含类别及其坐标)以图片形式展示
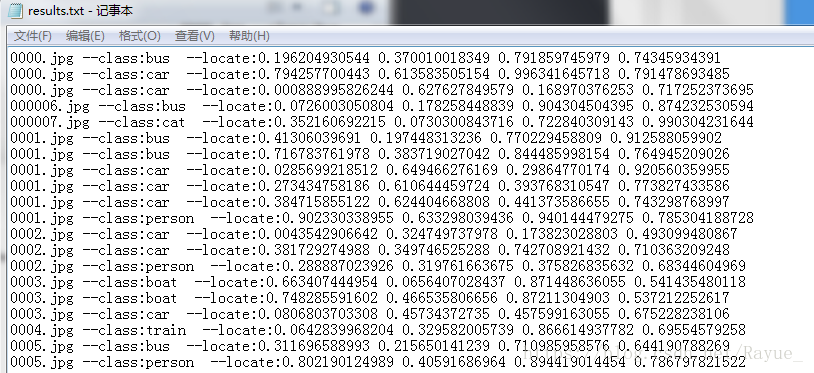
用python语言完成大批量图片检测,并将结果(图片中所包含类别及其坐标)打印在txt文本内保存
方案一、用shell script语句调用ssd_detect.exe文件,完成大批量的图片定位检测
1、在你编译完caffe文件时,会有ssd_detect.exe(ssd_detect.bin)文件生成

如果你是windows下用cmake编译的,文件路径应该是caffe-ssd-python-clear/examples/ssd/Release
如果你是Linux系统下直接编译的,文件路径应该在caffe-ssd/Build/x64/Release(不记得了,不对就自己搜搜)
2、接下来写一个shell script脚本(新建记事本,后缀名改为.sh)
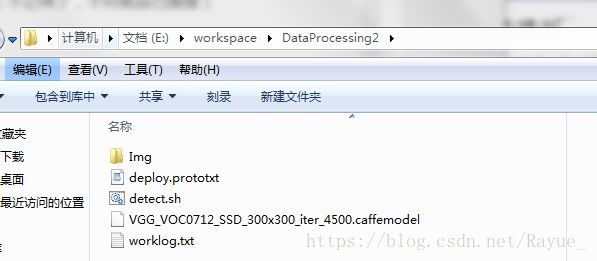
detect.sh文件如下
starttime=`date +'%Y-%m-%d %H:%M:%S'`
E:/workspace/caffe-ssd-gpu/examples/ssd/Release/ssd_detect.exe \
E:/workspace/DataProcessing2/deploy.prototxt \
E:/workspace/DataProcessing2/VGG_VOC0712_SSD_300x300_iter_4500.caffemodel \
E:/workspace/DataProcessing2/Img/work.txt | tee E:/workspace/DataProcessing2/worklog.txt
endtime=`date +'%Y-%m-%d %H:%M:%S'`
start_seconds=$(date --date="$starttime" +%s);
end_seconds=$(date --date="$endtime" +%s);
echo "run time: "$((end_seconds-start_seconds))"s"
read -p "Press any key to continue" varstarttime和endtime是用来计时的
tee | ./././.. 是将结果输出到txt文件里保存的
重要的就是中间那段语句,注意以下几点
ssd_detect.exe、deploy.prototxt、***.caffemodel文件路径正确
work.txt里包含着你批量处理的图片文件清单(包括路径)
3、双击运行detect.sh文件,生成worklog.txt文件,包含文件名、检测类别、匹配程度、物体坐标

方案二、用python实现单张或多张图片的定位检测
自己注意deploy.prototxt、labelmap_voc.prototxt、***.caffemodel文件以及待测图片的路径
1、python实现单张图片检测
# coding: utf-8
# # Detection with SSD
import numpy as np
import matplotlib.pyplot as plt
import pylab
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# Make sure that caffe is on the python path:
caffe_root = 'E:/workspace/caffe-ssd-gpu/' # this file is expected to be in {caffe_root}/examples
root = 'E:/workspace/DataProcessing4/'
import os
os.chdir(caffe_root)
import sys
sys.path.insert(0, 'python')
import caffe
#caffe.set_device(0)
#caffe.set_mode_gpu()
caffe.set_mode_cpu()
# * Load LabelMap.
from google.protobuf import text_format
from caffe.proto import caffe_pb2
# load PASCAL VOC labels
labelmap_file = root+'labelmap_voc.prototxt'
file = open(labelmap_file, 'r')
labelmap = caffe_pb2.LabelMap()
text_format.Merge(str(file.read()), labelmap)
def get_labelname(labelmap, labels):
num_labels = len(labelmap.item)
labelnames = []
if type(labels) is not list:
labels = [labels]
for label in labels:
found = False
for i in xrange(0, num_labels):
if label == labelmap.item[i].label:
found = True
labelnames.append(labelmap.item[i].display_name)
break
assert found == True
return labelnames
# * Load the net in the test phase for inference, and configure input preprocessing.
model_def = root+'deploy.prototxt'
model_weights = root+'VGG_VOC0712_SSD_300x300_iter_120000.caffemodel'
net = caffe.Net(model_def, # defines the structure of the model
model_weights, # contains the trained weights
caffe.TEST) # use test mode (e.g., don't perform dropout)
# input preprocessing: 'data' is the name of the input blob == net.inputs[0]
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2, 0, 1))
transformer.set_mean('data', np.array([104,117,123])) # mean pixel
transformer.set_raw_scale('data', 255) # the reference model operates on images in [0,255] range instead of [0,1]
transformer.set_channel_swap('data', (2,1,0)) # the reference model has channels in BGR order instead of RGB
# ### 2. SSD detection
# * Load an image.
# set net to batch size of 1
image_resize = 300
net.blobs['data'].reshape(1,3,image_resize,image_resize)
image = caffe.io.load_image('E:/workspace/DataProcessing4/Img/2007_000925.jpg')
#plt.imshow(image)
#pylab.show()
# * Run the net and examine the top_k results
transformed_image = transformer.preprocess('data', image)
net.blobs['data'].data[...] = transformed_image
# Forward pass.
detections = net.forward()['detection_out']
# Parse the outputs.
det_label = detections[0,0,:,1]
det_conf = detections[0,0,:,2]
det_xmin = detections[0,0,:,3]
det_ymin = detections[0,0,:,4]
det_xmax = detections[0,0,:,5]
det_ymax = detections[0,0,:,6]
# Get detections with confidence higher than 0.6.
top_indices = [i for i, conf in enumerate(det_conf) if conf >= 0.6]
top_conf = det_conf[top_indices]
top_label_indices = det_label[top_indices].tolist()
top_labels = get_labelname(labelmap, top_label_indices)
top_xmin = det_xmin[top_indices]
top_ymin = det_ymin[top_indices]
top_xmax = det_xmax[top_indices]
top_ymax = det_ymax[top_indices]
# * Plot the boxes
colors = plt.cm.hsv(np.linspace(0, 1, 21)).tolist()
plt.imshow(image)
currentAxis = plt.gca()
for i in xrange(top_conf.shape[0]):
xmin = int(round(top_xmin[i] * image.shape[1]))
ymin = int(round(top_ymin[i] * image.shape[0]))
xmax = int(round(top_xmax[i] * image.shape[1]))
ymax = int(round(top_ymax[i] * image.shape[0]))
score = top_conf[i]
label = int(top_label_indices[i])
label_name = top_labels[i]
display_txt = '%s: %.2f'%(label_name, score)
coords = (xmin, ymin), xmax-xmin+1, ymax-ymin+1
color = colors[label]
currentAxis.add_patch(plt.Rectangle(*coords, fill=False, edgecolor=color, linewidth=2))
currentAxis.text(xmin, ymin, display_txt, bbox={'facecolor':color, 'alpha':0.5})
pylab.show()检测效果


2、python实现多张图片检测
#coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
import pylab
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# Make sure that caffe is on the python path:
root = 'E:/workspace/DataProcessing4/'
import os
os.chdir(root)
import caffe
#caffe.set_device(0)
#caffe.set_mode_gpu()
caffe.set_mode_cpu()
# * Load LabelMap.
# In[ ]:
from google.protobuf import text_format
from caffe.proto import caffe_pb2
# load PASCAL VOC labels
labelmap_file = root+'labelmap_voc.prototxt'
file = open(labelmap_file, 'r')
labelmap = caffe_pb2.LabelMap()
text_format.Merge(str(file.read()), labelmap)
def get_labelname(labelmap, labels):
num_labels = len(labelmap.item)
labelnames = []
if type(labels) is not list:
labels = [labels]
for label in labels:
found = False
for i in xrange(0, num_labels):
if label == labelmap.item[i].label:
found = True
labelnames.append(labelmap.item[i].display_name)
break
assert found == True
return labelnames
# * Load the net in the test phase for inference, and configure input preprocessing.
# In[3]:
model_def = root+'deploy.prototxt'
model_weights = root+'VGG_VOC0712_SSD_300x300_iter_120000.caffemodel'
net = caffe.Net(model_def, # defines the structure of the model
model_weights, # contains the trained weights
caffe.TEST) # use test mode (e.g., don't perform dropout)
# input preprocessing: 'data' is the name of the input blob == net.inputs[0]
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2, 0, 1))
transformer.set_mean('data', np.array([104,117,123])) # mean pixel
transformer.set_raw_scale('data', 255) # the reference model operates on images in [0,255] range instead of [0,1]
transformer.set_channel_swap('data', (2,1,0)) # the reference model has channels in BGR order instead of RGB
colors = plt.cm.hsv(np.linspace(0, 1, 21)).tolist()
# ### 2. SSD detection
# * Load an image.
# In[4]:
dir=root+'Img/'
filelist=[]
filenames=os.listdir(dir) #返回指定目录下的所有文件和目录名
for fn in filenames:
fullfilename=os.path.join(dir,fn) #os.path.join--拼接路径
filelist.append(fullfilename) #filelist里存储每个图片的路径
# set net to batch size of 1
image_resize = 300
net.blobs['data'].reshape(1,3,image_resize,image_resize)
for j in range(0,len(filelist)):
img=filelist[j] #获取当前图片的路径
image = caffe.io.load_image(img)
# * Run the net and examine the top_k results
# In[5]:
transformed_image = transformer.preprocess('data', image)
net.blobs['data'].data[...] = transformed_image
# Forward pass.
detections = net.forward()['detection_out']
# Parse the outputs.
det_label = detections[0,0,:,1]
det_conf = detections[0,0,:,2]
det_xmin = detections[0,0,:,3]
det_ymin = detections[0,0,:,4]
det_xmax = detections[0,0,:,5]
det_ymax = detections[0,0,:,6]
# Get detections with confidence higher than 0.6.
top_indices = [i for i, conf in enumerate(det_conf) if conf >= 0.6]
top_conf = det_conf[top_indices]
top_label_indices = det_label[top_indices].tolist()
top_labels = get_labelname(labelmap, top_label_indices)
top_xmin = det_xmin[top_indices]
top_ymin = det_ymin[top_indices]
top_xmax = det_xmax[top_indices]
top_ymax = det_ymax[top_indices]
# * Plot the boxes
# In[6]:
plt.imshow(image)
currentAxis = plt.gca()
for i in xrange(top_conf.shape[0]):
xmin = int(round(top_xmin[i] * image.shape[1]))
ymin = int(round(top_ymin[i] * image.shape[0]))
xmax = int(round(top_xmax[i] * image.shape[1]))
ymax = int(round(top_ymax[i] * image.shape[0]))
score = top_conf[i]
label = int(top_label_indices[i])
label_name = top_labels[i]
display_txt = '%s: %.2f'%(label_name, score)
coords = (xmin, ymin), xmax-xmin+1, ymax-ymin+1
color = colors[label]
currentAxis.add_patch(plt.Rectangle(*coords, fill=False, edgecolor=color, linewidth=2))
currentAxis.text(xmin, ymin, display_txt, bbox={'facecolor':color, 'alpha':0.5})
pylab.show()
每显示一张图片,手动关闭后会自动打开下一张图片
3、python实现大批量图片检测,并将检测结果写入txt文件保存
#coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
import pylab
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# Make sure that caffe is on the python path:
root = 'E:/workspace/DataProcessing4/'
import os
os.chdir(root)
import caffe
#caffe.set_device(0)
#caffe.set_mode_gpu()
caffe.set_mode_cpu()
# * Load LabelMap.
# In[ ]:
from google.protobuf import text_format
from caffe.proto import caffe_pb2
# load PASCAL VOC labels
labelmap_file = root+'labelmap_voc.prototxt'
file = open(labelmap_file, 'r')
labelmap = caffe_pb2.LabelMap()
text_format.Merge(str(file.read()), labelmap)
def get_labelname(labelmap, labels):
num_labels = len(labelmap.item)
labelnames = []
if type(labels) is not list:
labels = [labels]
for label in labels:
found = False
for i in xrange(0, num_labels):
if label == labelmap.item[i].label:
found = True
labelnames.append(labelmap.item[i].display_name)
break
assert found == True
return labelnames
# * Load the net in the test phase for inference, and configure input preprocessing.
# In[3]:
model_def = root+'deploy.prototxt'
model_weights = root+'VGG_VOC0712_SSD_300x300_iter_120000.caffemodel'
net = caffe.Net(model_def, # defines the structure of the model
model_weights, # contains the trained weights
caffe.TEST) # use test mode (e.g., don't perform dropout)
# input preprocessing: 'data' is the name of the input blob == net.inputs[0]
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2, 0, 1))
transformer.set_mean('data', np.array([104,117,123])) # mean pixel
transformer.set_raw_scale('data', 255) # the reference model operates on images in [0,255] range instead of [0,1]
transformer.set_channel_swap('data', (2,1,0)) # the reference model has channels in BGR order instead of RGB
# ### 2. SSD detection
# * Load an image.
# In[4]:
dir=root+'Img/'
filelist=[]
filenames=os.listdir(dir) #返回指定目录下的所有文件和目录名
for fn in filenames:
fullfilename=os.path.join(dir,fn) #os.path.join--拼接路径
filelist.append(fullfilename) #filelist里存储每个图片的路径
# set net to batch size of 1
image_resize = 300
net.blobs['data'].reshape(1,3,image_resize,image_resize)
with open(root+'results.txt', 'w')as f:
for j in range(0,len(filelist)):
img=filelist[j] #获取当前图片的路径
image = caffe.io.load_image(img)
# * Run the net and examine the top_k results
# In[5]:
transformed_image = transformer.preprocess('data', image)
net.blobs['data'].data[...] = transformed_image
# Forward pass.
detections = net.forward()['detection_out']
# Parse the outputs.
det_label = detections[0,0,:,1]
det_conf = detections[0,0,:,2]
det_xmin = detections[0,0,:,3]
det_ymin = detections[0,0,:,4]
det_xmax = detections[0,0,:,5]
det_ymax = detections[0,0,:,6]
# Get detections with confidence higher than 0.6.
top_indices = [i for i, conf in enumerate(det_conf) if conf >= 0.6]
top_conf = det_conf[top_indices]
top_label_indices = det_label[top_indices].tolist()
top_labels = get_labelname(labelmap, top_label_indices)
top_xmin = det_xmin[top_indices]
top_ymin = det_ymin[top_indices]
top_xmax = det_xmax[top_indices]
top_ymax = det_ymax[top_indices]
for k in range(len(top_labels)):
f.write('{} --class:{} --locate:{} {} {} {}\n'.format(filenames[j],
top_labels[k],
top_xmin[k],
top_ymin[k],
top_xmax[k],
top_ymax[k]))
效果展示——
图片名 --class:类名 --locate:xmin ymin xmax ymax