Don’t Take the Easy Way Out: Ensemble Based Methods for Avoiding Known Dataset Biases论文笔记
Abstract
最先进的模型通常利用数据中的表面模式,这些表面模式不能很好地推广到域外或对抗性设置中。例如,文本蕴涵模型经常了解特定的关键词暗示蕴涵,而与上下文无关,而视觉问答模型则学会预测原型答案,而无需考虑图像中的证据。在本文中,我们表明,如果我们对此类偏差有先验知识,则可以训练该模型对域移位更健壮。我们的方法分为两个阶段:我们(1)训练仅基于数据集偏差进行预测的朴素模型,以及(2)训练与朴素模型合而为一的稳健模型,以鼓励它专注于其他模式在更可能泛化的数据中。对具有域外测试集的五个数据集进行的实验表明,在所有设置下的鲁棒性都得到了显着提高,其中包括在变化的先验视觉问答集上增加了12分,在对抗性问答集上增加了9分。
1 Introduction
在本文中,作者在这些工作的基础上展示,一旦数据集偏差被识别,我们可以通过防止模型利用该偏差来提高模型的域外性能。为了做到这一点,我们利用了这样一个事实,即这些偏差通常可以用简单的、受约束的基线方法显式地建模,以便通过基于集成的训练将它们从最终模型中剔除。
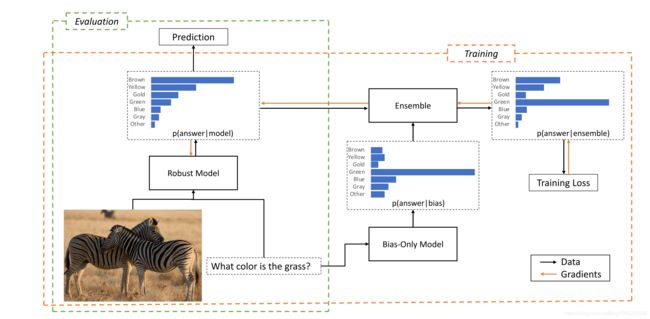
作者的方法分为两步,第一步训练一个带有偏见的模型,模型在训练集表现好,但是在这范围之外表现就很差,第二步再训练一个模型集成带偏见的模型,在测试集上只用第二个模型。
作者首先在两个通过向MNLI添加人工特征来包含人工构建的偏差的合成数据集上验证,然后再在三个有挑战性的数据集(这里包含VQA-CP),作者在所有设定上都取得了很大的进步。
2 Related Work
之前提出的数据集有很多数据集都存在偏见,新提出的数据集在尽量避免存在偏见,作者认为虽然避免数据集存在偏见是很重要的,但是提出一个方法能防止模型利用之前数据集中的偏见,然后之前的数据集就可以继续用,随着我们对我们想要避免的偏见的理解的发展,更新我们的方法。
之前关于偏见(忽略输入的一部分而产生的)的工作主要集中在强制生成模型以理解所有输入的生成目标,精心设计的模型体系结构或从模型的内部表示对抗性删除类指示特征。作者考虑除此之外的偏见,并在VQA-CP上验证。还有一个相关的任务是防止模型使用特定的有问题的数据集特征,这通常是从公平的角度进行研究的。但是作者认为偏见是跟整个任务的特征有关,不能简单的忽略。通过对现有示例应用较小扰动而构建的域外示例的模型评估也成为近期研究的主题。 作者考虑的领域转移涉及对输入分布的较大更改,旨在消除现有模型中的更高级别的缺陷。
3 Methods
3.1 Training a Bias-Only Model
第一阶段的目标是建立一个模型,该模型在训练数据上表现良好,但在域外测试集上的表现可能很差。 由于我们假设我们无法访问测试集中的示例,因此我们必须应用先验知识才能实现此目标。
最直接的方法是在训练过程中识别与类别标签相关但已知与测试集上的标签不相关或不相关的一组特征,然后在这些特征上训练分类器。2 例如,我们的VQA-CP纯偏差模型使用问题类型作为输入,因为问题类型和答案之间的相关性在训练集中与测试集有很大不同(2是“多少个。 。”这类问题的常见答案,但对于测试装置上的此类问题很少见。)
但是,我们方法的好处是可以使用任何一种预测变量对偏差进行建模,从而为我们提供了一种捕获更复杂直觉的方法。 例如,在SQuAD上,我们的“仅偏见”模型会根据TF-IDF分数构建的输入进行操作,而在我们更改的先前TriviaQA数据集上,我们的“仅偏见”模型会使用预先训练的命名实体识别(NER)标记器 。
3.2 Training a Robust Model
3.2.1 Problem Definition
假定有n个训练样本![]() ,每一个样本有一个整数标签
,每一个样本有一个整数标签![]() ,C是类别的数目。此外,我们还假设了一个预先训练的偏差预测器h,其中
,C是类别的数目。此外,我们还假设了一个预先训练的偏差预测器h,其中![]() ,其中
,其中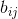 代表仅有偏见的模型针对样本i的预测为类别j的概率。第二个预测器f,带有参数
代表仅有偏见的模型针对样本i的预测为类别j的概率。第二个预测器f,带有参数 ,
,![]() ,
, 也是一个类似的类别概率 。我们的目标是构建一个优化θ的训练目标,以便f可以学习选择正确的类别,而无需使用偏见模型所捕获的策略。
也是一个类似的类别概率 。我们的目标是构建一个优化θ的训练目标,以便f可以学习选择正确的类别,而无需使用偏见模型所捕获的策略。
3.2.2 General Approach
我们将h和f进行融合,特别是一个新类别的概率的分布![]() 是由和
是由和 计算的。在训练期间,loss的计算是通过
计算的。在训练期间,loss的计算是通过![]() ,梯度反向传递f,
,梯度反向传递f,
在验证阶段,只有f使用。
3.2.3 Bias Product
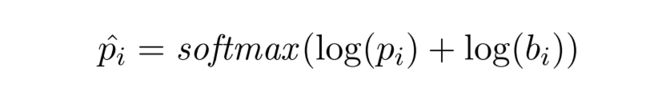
![]() 无限接近
无限接近![]() ,代表的是两个数组进行element-wise相乘。
,代表的是两个数组进行element-wise相乘。
Probabilistic Justification
给定样本 ,
,![]() 代表样本的bias,在只有bias的模型中用到。
代表样本的bias,在只有bias的模型中用到。![]() 代表样本中可被捕捉的除bia之外的信息。假定给定标签c,
代表样本中可被捕捉的除bia之外的信息。假定给定标签c, ![]() 和
和![]() 是有条件独立的。
是有条件独立的。

我们无法直接对![]() 建模,因为通常无法创建排除偏差的数据视图。 相反,为了鼓励模型落入计算
建模,因为通常无法创建排除偏差的数据视图。 相反,为了鼓励模型落入计算![]() 的角色,我们使用仅偏差模型计算
的角色,我们使用仅偏差模型计算![]() 并训练 两个模型的乘积来计算
并训练 两个模型的乘积来计算![]() 。
。
实际上,我们忽略了p(c)因子,因为在我们的数据集上,要么类是均匀分布(MNLI)的,要么纯偏差模型无法轻松地捕获类,因为它正在使用指针网络(QA);或者 因为我们还是想从模型(VQA)中删除类优先级。
3.2.4 Learned-Mixin
条件独立性(等式3)的假设通常太强了。 例如,在某些情况下,健壮模型可能能够预测仅偏倚模型对于某些种类的训练示例而言将是不可靠的。 我们发现这可能会导致健壮模型选择性地调整其行为,以补偿仅偏差模型的不准确性,从而导致域外设置出现错误(请参阅第5.1节)。
相反,我们允许模型明确确定在给定输入的情况下信任偏差的程度:

其中g是一个学习的函数,![]() ,其中w是一个学习的向量。
,其中w是一个学习的向量。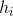 是样本
是样本 的模型的最后一层。
的模型的最后一层。![]() ,用于通过将模型乘以负权重来防止模型逆转偏差。w与其他参数一起训练,当
,用于通过将模型乘以负权重来防止模型逆转偏差。w与其他参数一起训练,当![]() 时,这减少了偏差乘积。
时,这减少了偏差乘积。
这种方法的一个困难是模型可以学习将偏差积分到中并将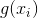 设置为0。我们发现这种情况有时在实践中会发生,我们的下一种方法可以缓解这一挑战。
设置为0。我们发现这种情况有时在实践中会发生,我们的下一种方法可以缓解这一挑战。
3.2.5 Learned-Mixin +H
为了防止Learned-mixin集合忽略,我们对损失添加了熵惩罚:
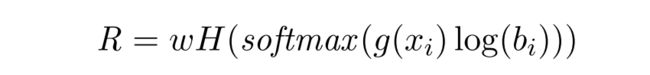

w是一个超参数,惩罚熵会鼓励偏差分量不均匀,从而对整体产生更大的影响。
4 Evaluation Methodology
在几个具有域外测试集的数据集上评估我们的方法。其中一些任务,如HANS或Adversarial SQuAD,可以很容易地通过生成与测试集中类似的额外训练示例来解决。相反,我们证明了通过利用模型可能采用的一般的、有偏见的策略的知识来提高这些任务的性能是可能的。
我们的评估设置包括训练集,域外测试集,纯偏差模型和主模型。 为了进行评估,我们在训练集上训练纯偏差模型,在使用第3节中的一种方法的同时,在训练集上训练主模型,并在域外测试集上评估主模型。 如果可用,我们还会报告域内测试集的性能。 我们使用的模型在主模型中可以很好地完成其各自的任务,并且不会进一步调整其超参数或进行早期停止。
我们考虑了两个提取的质量检查数据集,我们将其视为联合分类任务,其中模型必须选择开始和结束答案令牌。 对于这些数据集,我们建立了独立的仅偏倚模型来选择开始标记和结束标记,然后将这些偏见与分类器的开始标记和结束标记的输出分布结合在一起。 我们在问题和段落嵌入中应用ReLU层,然后进行最大池化,以构造一个隐藏状态来计算学习的mixin权重。
我们将我们的方法与以下所述的重新加权基准进行比较,并与未经任何修改地训练主模型进行了比较。 在VQA上,我们还与对抗方法进行了比较。 我们考虑的其他偏差并非仅基于观察部分输入,因此这些对抗方法无法直接应用。
4.1 Reweight Baseline
作为非整体基线,我们在数据的加权版本上训练主模型,其中示例的权重为![]() (即,我们将示例权重为1减去仅偏向模型分配正确标签的概率 )。 这鼓励主模型专注于仅偏见模型出错的示例。
(即,我们将示例权重为1减去仅偏向模型分配正确标签的概率 )。 这鼓励主模型专注于仅偏见模型出错的示例。
4.2 Hyperparameters
我们的一种方法(Learned-Mixin + H)需要超参数调整。 但是,由于我们的假设是在培训期间我们无法访问域外测试示例,因此在我们的设置中,超参数调整面临挑战。 一个合理的选择是调整展示给测试集相关但不相同的域转移的开发集上的超参数,但不幸的是,我们的数据集中都没有这样的开发集。 相反,我们遵循先前的工作(Grand and Belinkov,2019; Ramakrishnan et al。,2018),并在测试集上执行模型选择。 尽管这对该方法的结果提出了重要的警告,但我们认为仍然有必要观察到熵正则化器可以产生很大的影响。 未来的工作可能能够构建合适的开发集,或者提出其他超参数调整方法来缓解此问题。 所选的超参数显示在附录A中。
5 Experiments
因为我只对VQA任务感兴趣,所以只列一下VQA-CP
5.2 VQA-CP
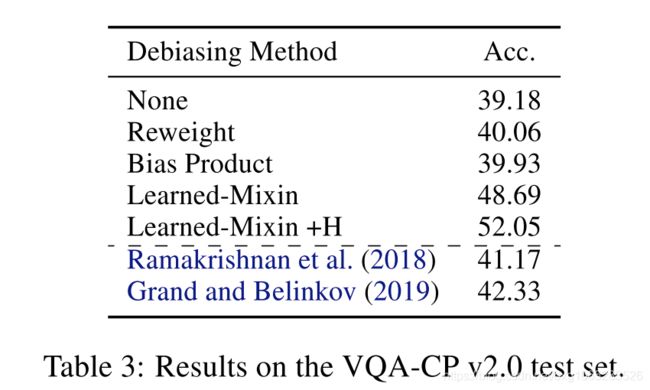
Data:我们对VQA-CP v2(Agrawal等人,2018)数据集进行了评估,该数据集是通过将VQA 2.0(Goyal等人,2018)训练和验证集重新划分为新的训练和测试集而构建的,从而使相关性 每个拆分之间问题类型和答案之间的差异也不同。 例如,“网球”是在训练集中以“什么运动...”开头的问题的最常见答案,而“滑雪”是在测试集中这些问题的最常见答案。 因为训练数据中很典型而选择答案的模型在此测试集上的表现会很差。
Bias-Only Model:VQA-CP附带有题为65个问题类型之一的问题,与问题的前几个单词相对应(例如,“什么颜色”)。 纯偏差模型使用此分类标签作为输入,并在与主模型相同的多标签目标上进行训练。
Main Model 我们使用BottomUpToDown(Anderson等人,2018)VQA模型的流行实现。 该模型使用多标签目标,因此我们通过将每个可能的答案视为两类分类问题来应用集成方法。
Results:表3显示了结果。 learned-mixin法非常有效,将VQA-CP的性能提高了约9个点,而熵正则化函数又可以将其提高3个点,大大超过了以前的工作。 对于learned-mixin集合,我们发现与偏差的预期准确性密切相关,在测试数据上的长矛相关性为0.77。 定性示例(图2)进一步表明,当模型知道是否可以依赖纯偏差模型时,模型会增加。