Yolov3基于Windows系统训练及测试(二.训练及测试篇一)
深度学习.yolov3.基于Windows系统训练及测试.训练及测试篇一
- 0. 目录/步骤
- 3. 基于yolov3的个人数据集训练(训练)
- 3.0 情况分析
- 3.0.1 情况目录列表
- 3.0.2 特殊情况处理
- 3.1 准备VOC数据集
- 3.1.1 创建数据集
- 3.1.2 替换待测数据
- 3.2 数据集批处理
- 3.2.1 分配训练集和验证集
- 3.2.2 生成目标路径及导入坐标
- 3.3 修改数据集及工程属性
- 3.3.1建立数据集连接
- 3.3.2卷积层属性修改
- 下一篇
- 参考文档
0. 目录/步骤
3. 基于yolov3的个人数据集训练(训练)
3.0 情况分析
3.0.1 情况目录列表
1 收到一批数据,封装成Annotations(xml文件)和JPEGImages(训练图片)两个文件夹,且xml文件和图片一一对应,并且xml文件和图片完整无误 ->进入步骤3.1->
3.0.1.1图片数据封装1->
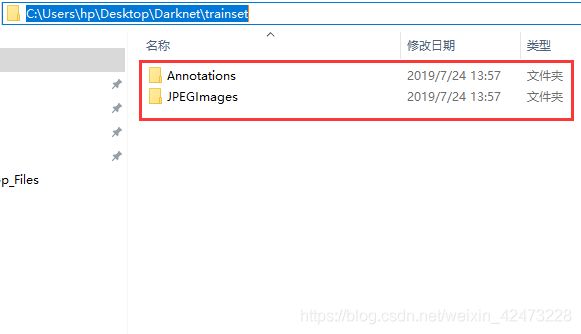
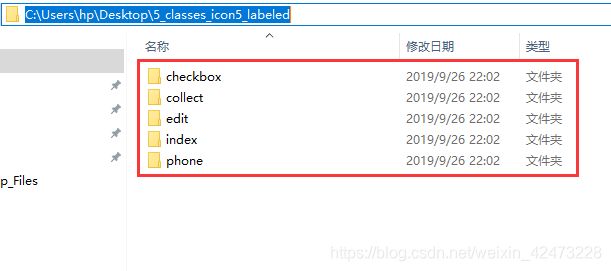
2 收到一批数据,封装成五个以类名命名文件夹,其中包含五类如下图,每个类中的都有待匹配的xml文件和训练图片,并且xml文件和训练图片完整无误 ->进入步骤3.0.2->
3.0.1.2图片数据封装2->
3 收到一批数据,只有文件夹,里面是待打标的训练图片,并且图片完整无误 ->进入步骤3.0.2->
3.0.1.3图片数据封装3->
4 其他情况,后期更新
3.0.2 特殊情况处理
为了增加文章的可读性减少文章的篇幅,我将其他比较特殊的情况单独整理成一篇,有需要的读者可以自行查阅:
文章名:yolov3对于特殊情况数据的处理
网址:待贴
3.1 准备VOC数据集
3.1.1 创建数据集
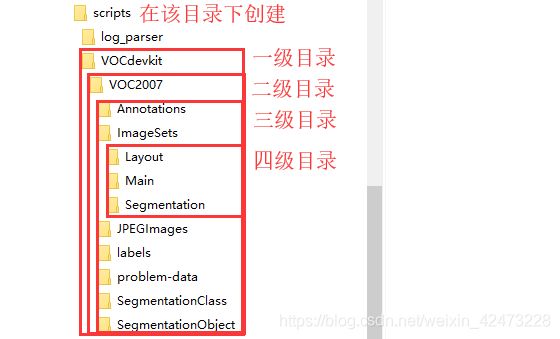
我们回到工程主目录,找到文件夹,在该文件夹下创建文件夹,然后严格按照如下图创建它的子目录
3.1.1.1图片创建空数据集->
3.1.2 替换待测数据
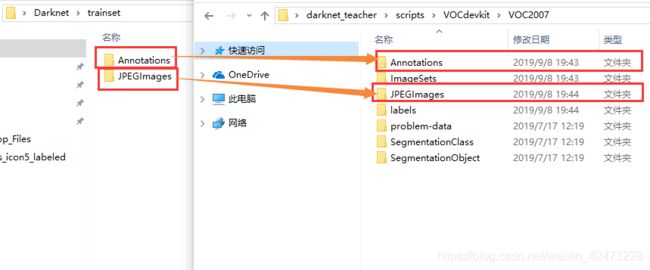
经过3.0.1的情况分析,无论你是哪种情况,现在我们都有被封装好的Annotations
和JPEGImages两个文件夹,我们将Annotations的所有xml文件,复制(Ctrl+A->Ctrl+C)到刚刚创建的数据集中的中,同样的将所有训练图片复制到数据集对应文件夹下
3.1.2.1图片替换数据文件夹->
3.2 数据集批处理
3.2.1 分配训练集和验证集
1 网盘下载链接(first-test.py):
安装包:first-test.py
链接:https://pan.baidu.com/s/17WK07o9Qw8xf5kLDa0eP_A 提取码:dcrt
2 first-test.py帮助我们以二八原则随机分配数据,便于后期的训练
下载好first-test.py,我们用pycharm打开,如果没有这个编译器的话,作者这里也提供下载,网盘下载链接(pycharm)
安装包: pycharm
链接:https://pan.baidu.com/s/17WK07o9Qw8xf5kLDa0eP_A 提取码:dcrt
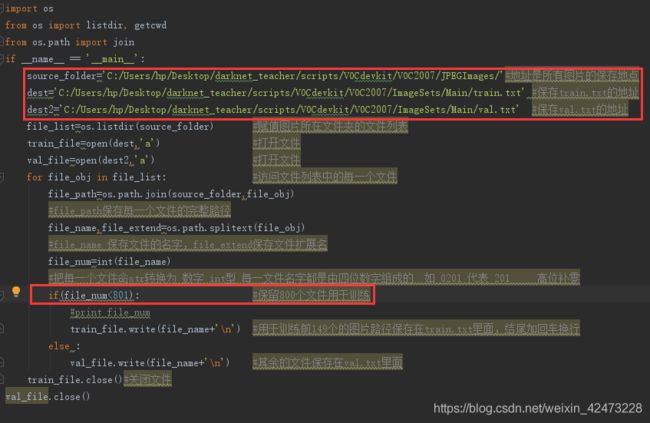
打开后,我们需要修改源码的四个地方如下图:
Source_floder: 训练图片所在路径,修改路径到我们训练图片的所在的地址
dest: 生成train.txt保存的地址,修改路径到Main文件夹下
dest2: 生成val.txt保存的地址,修改路径到Main文件夹下
file_num: 原理:随机分配图片,采用二八原则,20%验证集+80%测试集,将八成数据放入train.txt用于训练,其他的两成数据放入val.txt用于批量测试.而这里的file_num就是控制训练集数量的,举个例子:1000张图片,这里file_num=1000x0.8+1=801
3.2.1.1图片修改first-test.py->
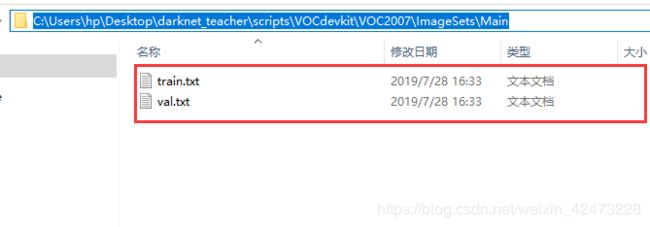
3 修改好这些代码后,右键点击Run voc_label,运行成功就会看见在Main文件夹下看见train.txt和val.txt两个文件,里面是对数据的命名分配
3.2.1.2图片生成文件->
3.2.2 生成目标路径及导入坐标
1 在主目录scripts文件夹下,找到voc_label.py,如果没有的话,这里也提供下载:
网盘下载链接:
安装包: voc_label.py
链接:https://pan.baidu.com/s/17WK07o9Qw8xf5kLDa0eP_A提取码:dcrt
2 voc_label.py将first-test.py随机分配的集合以地址的形式呈现出来,并且
同样的,我们用pycharm打开,这里需要修改源码的两个地方:
3.2.2.1图片修改voc_label.py->
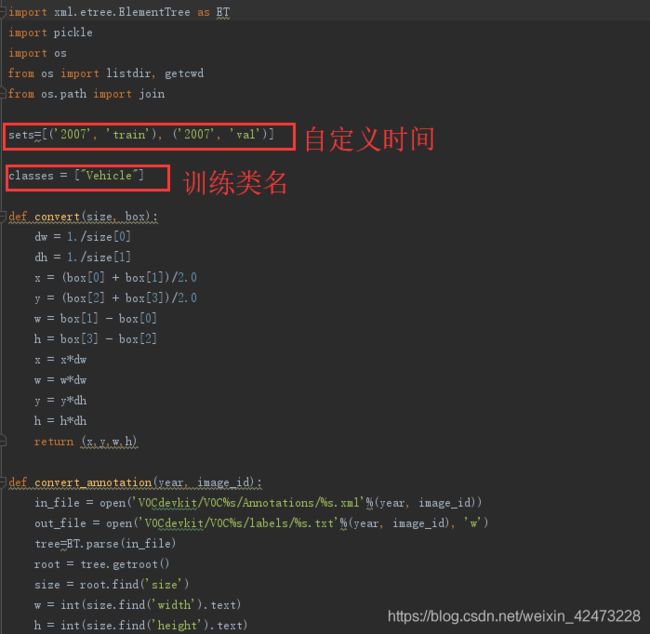
sets: 基础设置,设置自定义时间和数据集命名,这个一般不变,有必要的和
下一级目录时间相同,和xml文件内folder, database, annotation键值对内所指时间相同,规避后期的不可预判报错
3.2.2.2图片下一级目录时间->
3.2.2.3图片键值对时间->
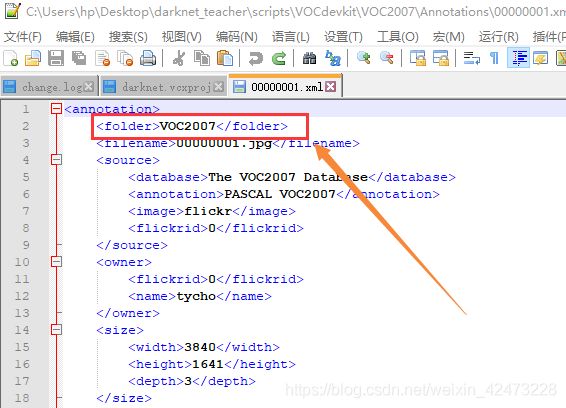
Classes: 所要训练的类名,这个一定要和xml文件里的类名相对应,不对应的话,会在后期的训练过程中出现大量的-nan loss异常,详细细节 见错误3.2.2->
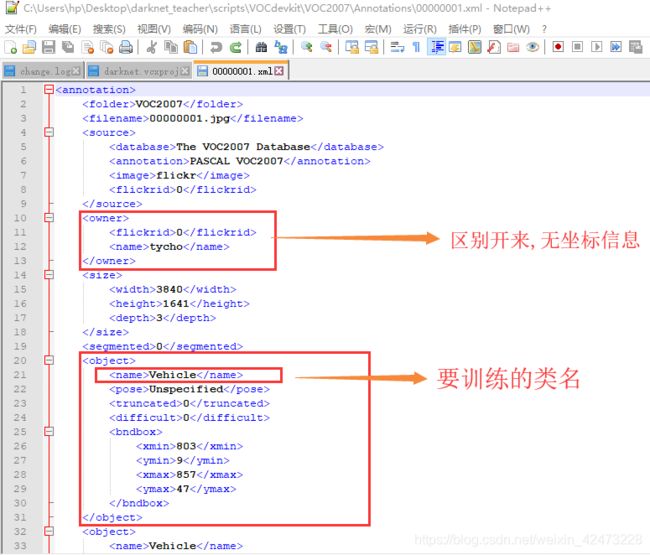
如果对训练数据类名不清楚,我们可以打开xml文件,在xml布局文件中搜索name,对键值对进行筛选,对有坐标的name作为一类,就是我们要填入Classes的类名,示例如下图:
3.2.2.4图片xml键值对筛选->
3 修改好这些代码后,右键点击** Run voc_label**,运行成功后我们会在scripts文件夹下,发现新创了两个文件2007_train.txt, 2007_val.txt,里面是分别是各分配数据的路径
3.2.2.5图片新创文件内容->
4 我们检查所有的目标坐标是否已经导入到,所有新建的坐标文件,放在如下地址下:
工程主目录\scipts\VOCdevkit\VOC2007\labels->
我们打开路径,所有的坐标文件已经生成好
3.2.2.6图片生成坐标文件->
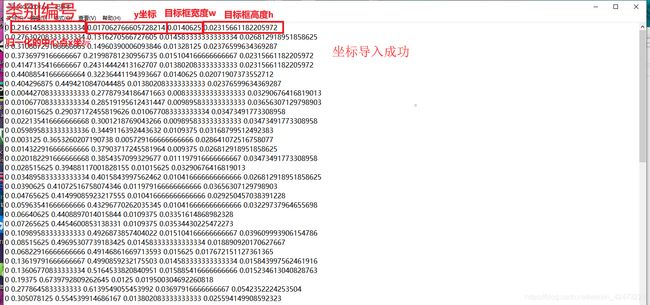
打开一个坐标文件,如果里面所有的xml坐标信息已经导入进来了,那么恭喜你成功. 如果在voc_label运行成功的情况下,发现坐标文件里面是空的 见错误3.2.2->
3.2.2.7图片导入成功->
3.3 修改数据集及工程属性
3.3.1建立数据集连接
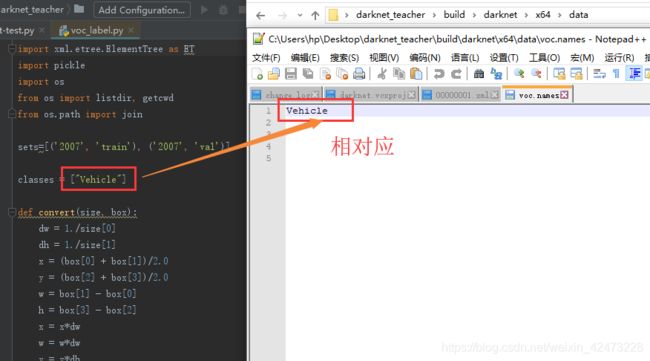
1 修改voc.names
我们打开路径:工程主目录\build\darknet\x64\data->,找到voc.names用记事本打开,voc.names里存放的都是我们稍后训练的类名,这些类名以回车隔开,这些类名即和 步骤3.2.2.2 中Classes类名相对应.
3.3.1.1图片修改voc.names->
2 修改voc.data
在相同路径下,找到voc.data用记事本打开,我们需要修改前三行,如下图:
3.3.1.2图片修改voc.data->
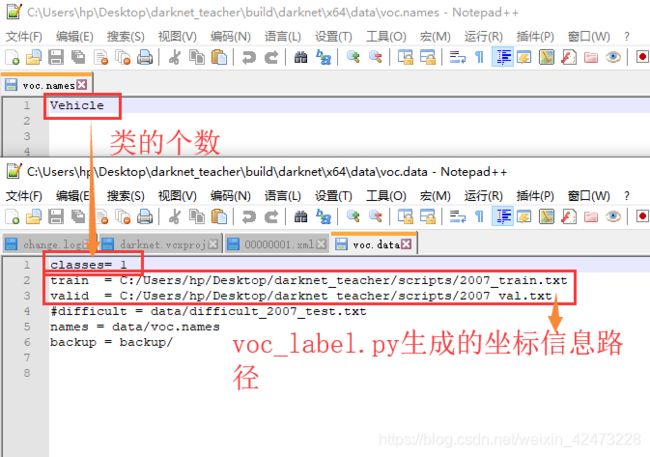
Classes: 为需要目标检测的类数量,即为步骤3.3.1中类名数量
train: 为训练集的路径,即为步骤3.2.2.3生成的2007_train.txt文件的地址
valid: 为验证集的路径,即为步骤3.2.2.3生成的2007_val.txt文件的地址
3.3.2卷积层属性修改
最后就是修改我们的卷积层文件了,在x64目录下,找到yolov3-voc.cfg文件,用**记事本/Notepad++**打开,我们需要修改的五个参数如下:
1修改filters,classes及 random
filters: 与聚类数目分布有关,计算公式:filter=(num/3)x(classes+coords+1) 一般地,
coords=4,num=9其中num在cfg中给出,需要大家根据自己情况确认,3.4.4也对该参数做了讲解
所以优化公式: filter=3x(classes+5),举个例子:作者中有一个类Vehicle.那么filter=3x(1+5)=18
classes: 类数量,如何修改这两个参数呢,我们用记事本搜索yolo,会找到三处yolo, filters与classes分别就分布在yolo地上下方, 其他的filter就不要动了
3.3.2.1图片修改filters及classes->

random: 多尺度训练开关,在电脑GPU配置不优秀的情况下,建议读者不要开了
同样的,记事本搜索random,一共三处,将random的参数改为0.
3.3.2.2图片修改random->

2 修改batch及subdivisions
batch: 一批训练样本的样本数量,相当于组的概念,每batch个样本更新一次参数
subdivisions:将batch再分割为subdivisions个子batch,每个子batch的大小为两者的商,这个商作为一次性送入训练器的样本数量.
那么这两个参数如何修改呢,一般的,设置batch=64, subdivisions=16,也就是每四个进行搬运.特别的,个人配置因人而异,当我们设置subdivisions=16,训练时出现out of memory,我们适当的加大subdivisions值.这和樵夫砍柴搬运的道理差不多,加大subdivisions值,虽然负荷小了,但训练的时间也变长了
当训练器出现out of memory 见错误3.3.2->
3.3.2.3图片修改batch和subdivisions->
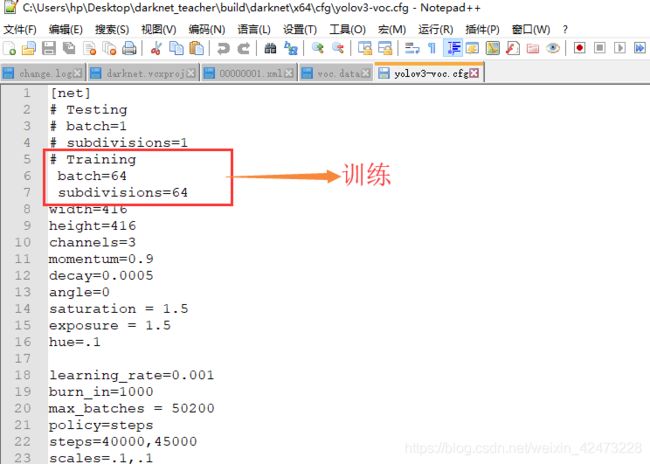
3 batch及subdivisions转换提示
对于训练来说,我们打开训练用参数:
#Training
#batch=64
#subdivisions=64
用#注释掉测试用参数如下:
#Testing
#batch=1
#subdivisions=1
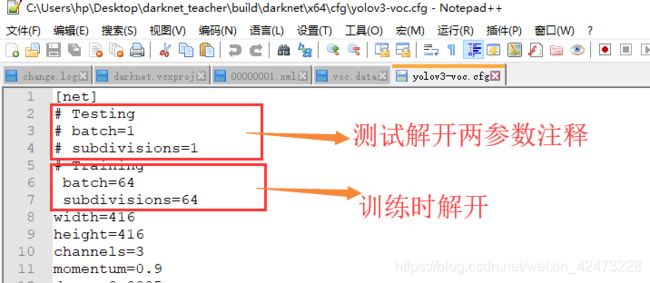
测试则相反:
3.3.2.4图片测试用转换->
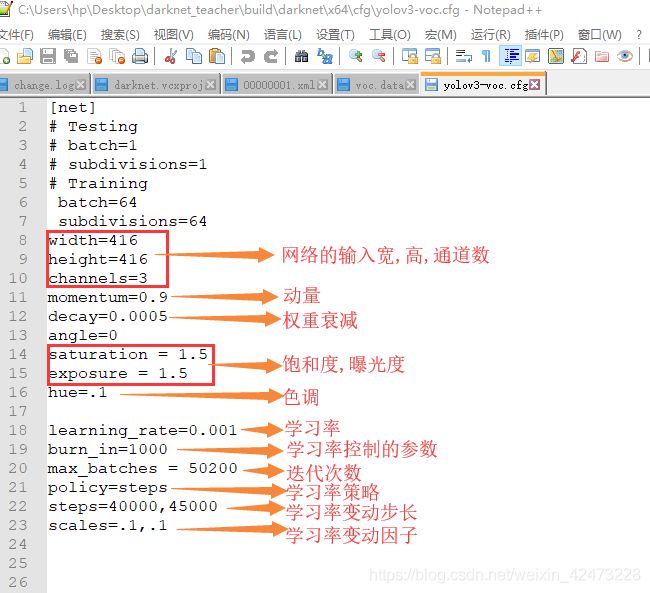
4 卷积层其他参数介绍
3.3.2.5图片卷积层参数介绍->
下一篇
Yolov3基于Windows系统训练及测试(二.训练及测试篇二)
参考文档
[1]Win10+VS2017配置yolov3(2)–训练自己数据集