知识图谱-neo4j入门实战
致读者: 博主是一名数据科学与大数据专业大二的学生,真正的一个互联网萌新,写博客一方面是为了记录自己的学习过程中遇到的问题和思考,一方面是希望能够帮助到很多和自己一样处于困惑的读者。
> 由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!之后会写大数据专业的文章哦。
GitHub链接https://github.com/wfy-belief
尽管现在我的水平可能还不太及格,但我会尽我自己所能,做到最好☺。——天地有正气,杂然赋流形。下则为河岳,上则为日星。
码文不易,可以给我一个小心心吗?♥

文章目录
- 简介
- 特点
- 安装和自启动
- Cypher查询语言
- 实战
- 创建人物节点
- 创建更多的人物节点
- 接下来创建地区节点
- 创建关系
- 关系增加属性
- 增加更多的关系
- 跨节点关系
- 搭建完成
- 查询所有对外有关系的节点
- 查询所有有关系的节点
- 查询所有对外有关系的节点,以及关系类型
- 查询所有有结婚关系的节点
- 创建节点的时候就建好关系
- 查找某人的朋友的朋友
- 增加/修改节点的属性
- 删除节点的属性
- 删除节点
- 删除有关系的节点
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
简介
你可以把Neo看作是一个高性能的图引擎,该引擎具有成熟和健壮的数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。 [1]
Neo是一个网络——面向网络的数据库——也就是说,它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。网络(从数学角度叫做图)是一个灵活的数据结构,可以应用更加敏捷和快速的开发模式。
特点
1.对象关系的不匹配使得把面向对象的“圆的对象”挤到面向关系的“方的表”中是那么的困难和费劲,而这一切是可以避免的。
2.关系模型静态、刚性、不灵活的本质使得改变schemas以满足不断变化的业务需求是非常困难的。由于同样的原因,当开发小组想应用敏捷软件开发时,数据库经常拖后腿。
3.关系模型很不适合表达半结构化的数据——而业界的分析家和研究者都认为半结构化数据是信息管理中的下一个重头戏。
4.网络是一种非常高效的数据存储结构。人脑是一个巨大的网络,万维网也同样构造成网状,这些都不是巧合。关系模型可以表达面向网络的数据,但是在遍历网络并抽取信息的能力上关系模型是非常弱的。
虽然Neo是一个比较新的开源项目,但它已经在具有1亿多个节点、关系和属性的产品中得到了应用,并且能满足企业的健壮性和性能的需求:
完全支持JTA和JTS、2PC分布式ACID事务、可配置的隔离级别和大规模、可测试的事务恢复。这些不仅仅是口头上的承诺:Neo已经应用在高请求的24/7环境下超过3年了。它是成熟、健壮的,完全达到了部署的门槛。
图:是指数据原理里的树集合成的网络。
Neo4j是一个嵌入式,基于磁盘的,支持完整事务的Java持久化引擎,它在图(网络)中而不是表中存储数据。Neo4j提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图,可以扩展到多台机器并行运行。相对于关系数据库来说,图数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询——在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图进行数据建模,Neo4j会以相同的速度遍历节点与边,其遍历速度与构成图的数据量没有任何关系。此外,Neo4j还提供了非常快的图算法、推荐系统和OLAP风格的分析,而这一切在目前的RDBMS系统中都是无法实现的。
由于使用了“面向网络的数据库”,人们对Neo充满了好奇。在该模型中,以“节点空间”来表达领域数据——相对于传统的模型表、行和列来说,节点空间是很多节点、关系和属性(键值对)构成的网络。关系是第一级对象,可以由属性来注解,而属性则表明了节点交互的上下文。网络模型完美的匹配了本质上就是继承关系的问题域,例如语义Web应用。Neo的创建者发现继承和结构化数据并不适合传统的关系数据库模型:
安装和自启动
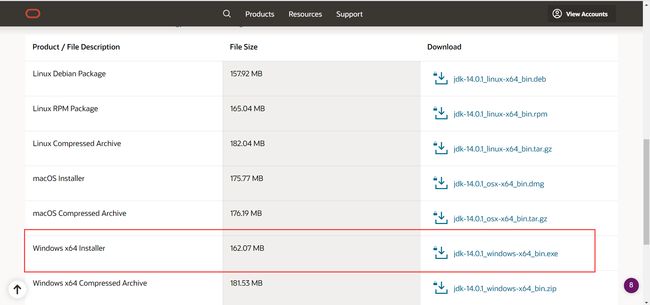
运行需要java支持
java14下载
neo4j console # 单次启动
neo4j install-service
neo4j start
# 地址http://localhost:7474/browser/
参考资料
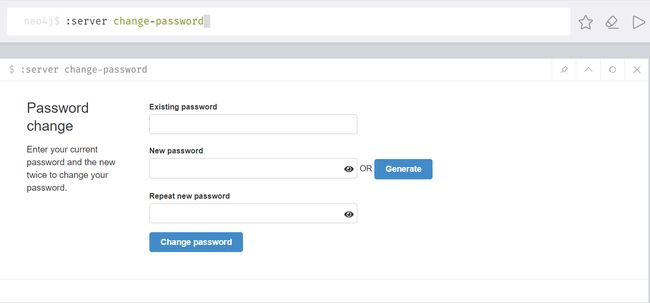
修改默认密码
:server change-password
# 初始密码是 neo4j
Cypher查询语言
Cypher是Neo4J的声明式图形查询语言,允许用户不必编写图形结构的遍历代码,就可以对图形数据进行高效的查询。Cypher的设计目的类似SQL,适合于开发者以及在数据库上做点对点模式(ad-hoc)查询的专业操作人员。其具备的能力包括: - 创建、更新、删除节点和关系 - 通过模式匹配来查询和修改节点和关系 - 管理索引和约束等
# 这是一段防爬代码,请读者不要介意
文章出处 https://blog.csdn.net/weixin_43906799
构建在个人网站 https://wfyblog.cn/notes/#/neo4j/0
实战
MATCH是匹配操作,而小括号()代表一个节点node(可理解为括号类似一个圆形),括号里面的n为标识符。
创建人物节点
CREATE (n:People {name:'John'}) RETURN n
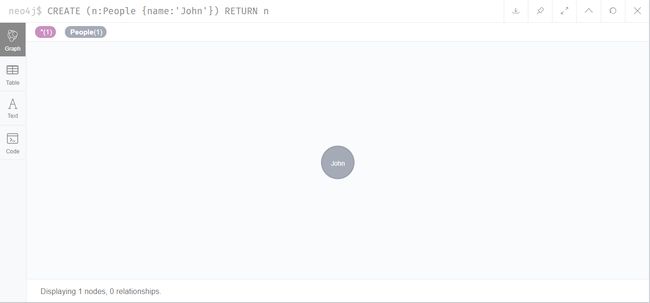
CREATE是创建操作,People是标签,代表节点的类型。花括号{}代表节点的属性,属性类似Python的字典。这条语句的含义就是创建一个标签为People的节点,该节点具有一个name属性,属性值是John。
创建更多的人物节点
继续来创建更多的人物节点,并分别命名:
CREATE (n:People {name:'Sally'}) RETURN n
CREATE (n:People {name:'Steve'}) RETURN n
CREATE (n:People {name:'Mike'}) RETURN n
CREATE (n:People {name:'Liz'}) RETURN n
CREATE (n:People {name:'Shawn'}) RETURN n
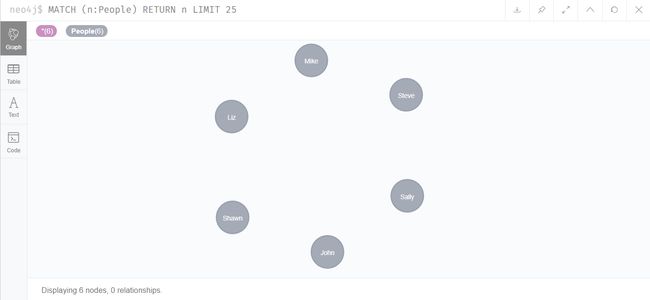
创建完成,执行查询语句
MATCH (n:People) RETURN n LIMIT 25
接下来创建地区节点
接下来创建地区节点:
CREATE (n:Location {city:'Miami', state:'FL'})
CREATE (n:Location {city:'Boston', state:'MA'})
CREATE (n:Location {city:'Lynn', state:'MA'})
CREATE (n:Location {city:'Portland', state:'ME'})
CREATE (n:Location {city:'San Francisco', state:'CA'})
执行查询
MATCH (n:Location) RETURN n LIMIT 25
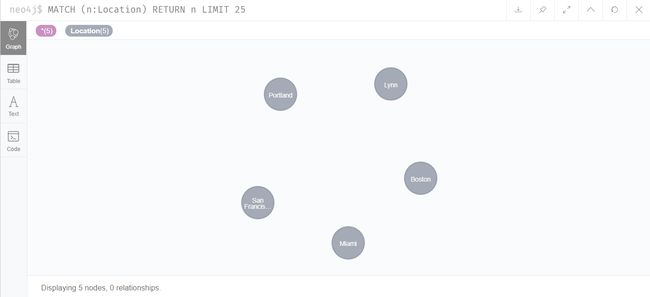
可以看到,节点类型为Location,属性包括city和state。
如图所示,共有6个人物节点、5个地区节点,Neo4J贴心地使用不用的颜色来表示不同类型的节点。
执行以下语句
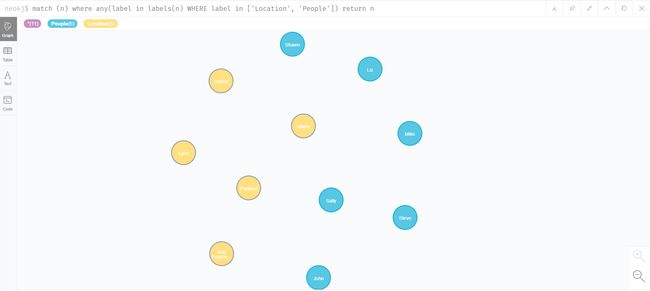
match(a:Location),(b:People) return a,b
match (n) where any(label in labels(n) WHERE label in ['Location', 'People']) return n
MATCH (a:People) ,(b:Location) with [a,b] as m unwind m as mm RETURN mm;
创建关系
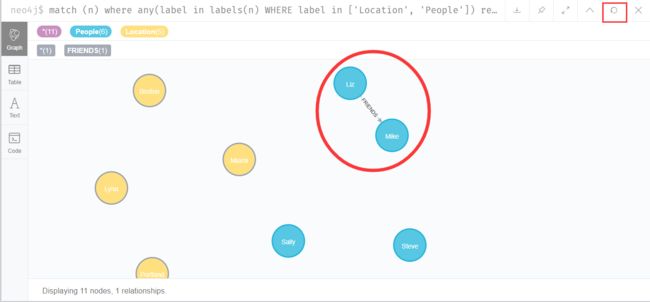
MATCH (a:People {name:'Liz'}),
(b:People {name:'Mike'})
MERGE (a)-[:FRIENDS]->(b)
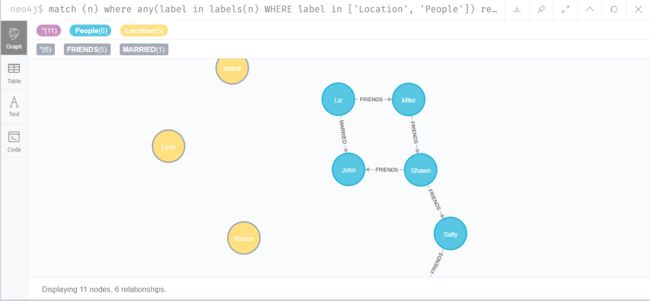
这里的方括号[]即为关系,FRIENDS为关系的类型。注意这里的箭头-->是有方向的,表示是从a到b的关系。 如图,Liz和Mike之间建立了FRIENDS关系,通过Neo4J的可视化很明显的可以看出:
关系增加属性
关系也可以增加属性
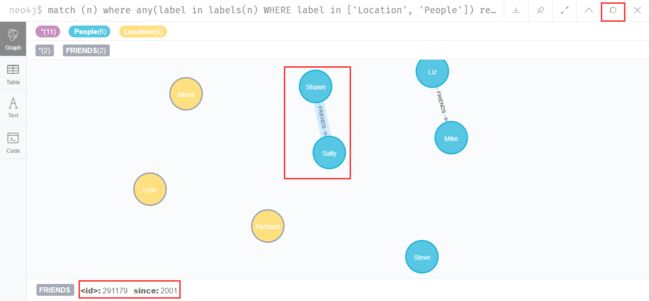
MATCH (a:People {name:'Shawn'}),
(b:People {name:'Sally'})
MERGE (a)-[:FRIENDS {since:2001}]->(b)
# 这是一段防爬代码,请读者不要介意
文章出处 https://blog.csdn.net/weixin_43906799
构建在个人网站 https://wfyblog.cn/notes/#/neo4j/0
增加更多的关系
接下来增加更多的关系
MATCH (a:People {name:'Shawn'}), (b:People {name:'John'}) MERGE (a)-[:FRIENDS {since:2012}]->(b)
MATCH (a:People {name:'Mike'}), (b:People {name:'Shawn'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
MATCH (a:People {name:'Sally'}), (b:People {name:'Steve'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
MATCH (a:People {name:'Liz'}), (b:People {name:'John'}) MERGE (a)-[:MARRIED {since:1998}]->(b)
跨节点关系
然后,我们需要建立不同类型节点之间的关系-人物和地点的关系
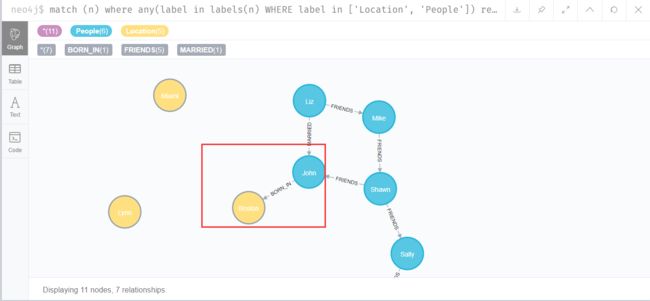
MATCH (a:People {name:'John'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1978}]->(b)
这里的关系是BORN_IN,表示出生地,同样有一个属性,表示出生年份。
如图,在人物节点和地区节点之间,人物出生地关系已建立好。
同样建立更多人的出生地
MATCH (a:People {name:'Liz'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1981}]->(b)
MATCH (a:People {name:'Mike'}), (b:Location {city:'San Francisco'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:People {name:'Shawn'}), (b:Location {city:'Miami'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:People {name:'Steve'}), (b:Location {city:'Lynn'}) MERGE (a)-[:BORN_IN {year:1970}]->(b)
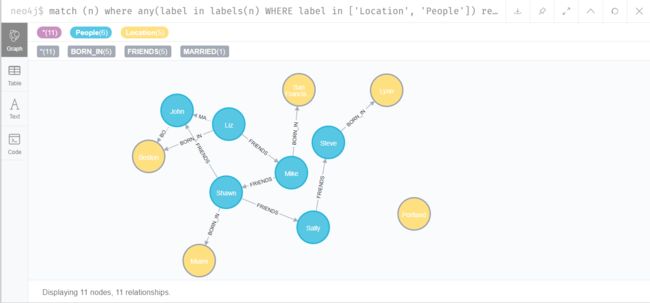
搭建完成
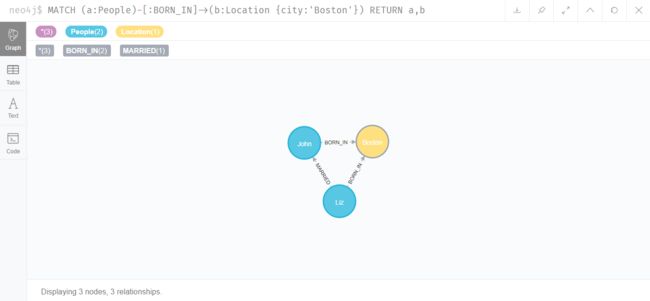
至此,知识图谱的数据已经插入完毕,可以开始做查询了。我们查询下所有在Boston出生的人物
MATCH (a:People)-[:BORN_IN]->(b:Location {city:'Boston'}) RETURN a,b
查询所有对外有关系的节点
MATCH (a:People)-->() RETURN a
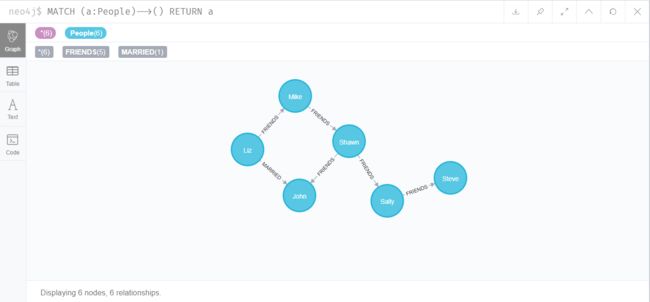
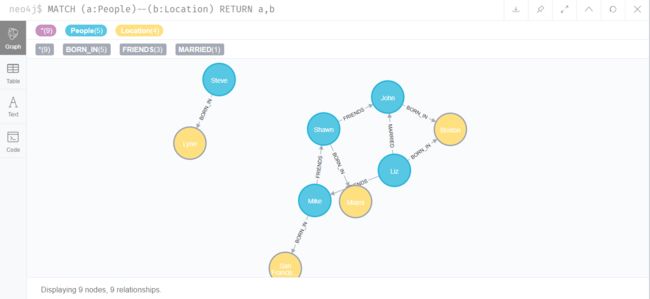
查询所有有关系的节点
MATCH (a:People)--(b:Location) RETURN a,b
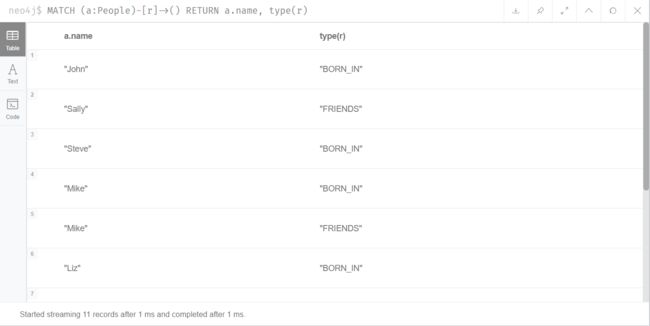
查询所有对外有关系的节点,以及关系类型
查询所有对外有关系的节点,以及关系类型
MATCH (a:People)-[r]->() RETURN a.name, type(r)
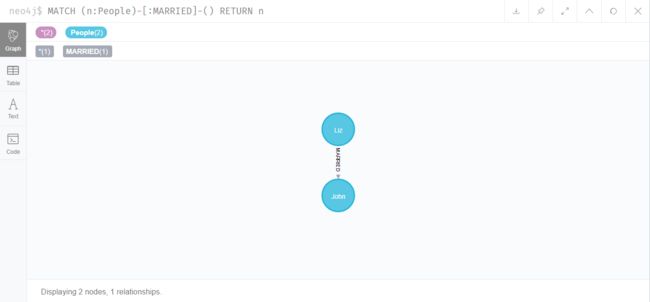
查询所有有结婚关系的节点
MATCH (n:People)-[:MARRIED]-() RETURN n
创建节点的时候就建好关系
CREATE (a:People {name:'Todd'})-[r:FRIENDS]->(b:People {name:'Carlos'})
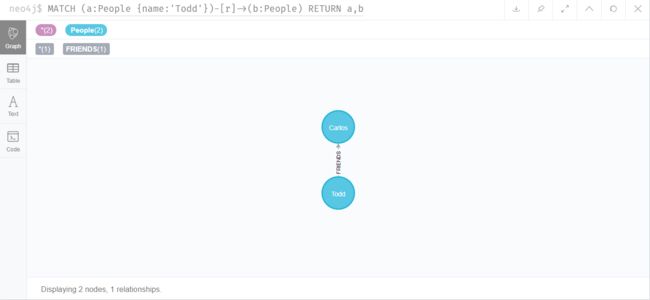
查找某人的朋友的朋友
MATCH (a:People {name:'Mike'})-[r1:FRIENDS]-()-[r2:FRIENDS]-(friend_of_a_friend) RETURN friend_of_a_friend.name AS fofName
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lhykaucs-1595205340208)(https://cdn.jsdelivr.net/gh/wfy-belief/PicGo-images//blog/image-20200708123705623.png)]
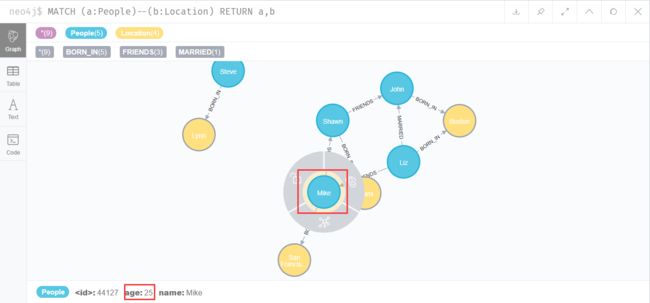
增加/修改节点的属性
MATCH (a:People {name:'Liz'}) SET a.age=34
MATCH (a:People {name:'Shawn'}) SET a.age=32
MATCH (a:People {name:'John'}) SET a.age=44
MATCH (a:People {name:'Mike'}) SET a.age=25
这里,SET表示修改操作
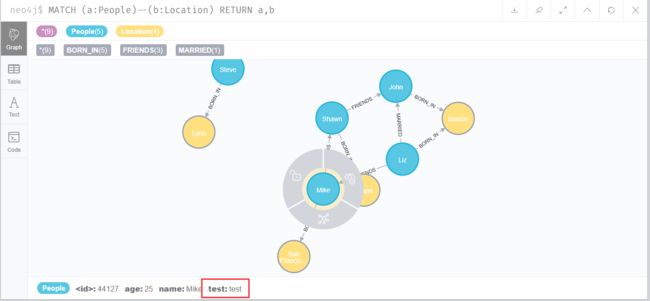
删除节点的属性
MATCH (a:People {name:'Mike'}) SET a.test='test'
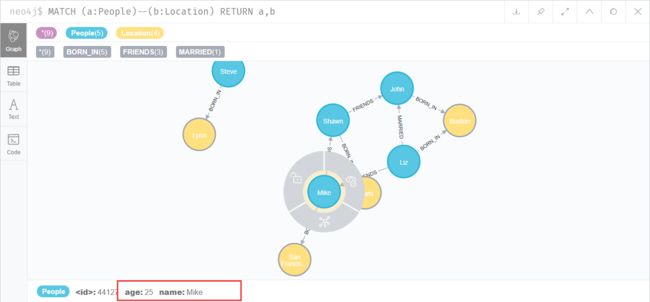
MATCH (a:People {name:'Mike'}) REMOVE a.test
删除属性操作主要通过REMOVE
删除节点
MATCH (a:Location {city:'Portland'}) DELETE a
删除节点操作是DELETE
删除有关系的节点
MATCH (a:People {name:'Todd'})-[rel]-(b:People) DELETE a,b,rel
建议收藏,码文不易,请各位老爷点个赞。