Django电商网站项目(4)--商品模块
前文中已设计了与商品模块有关的表如下:
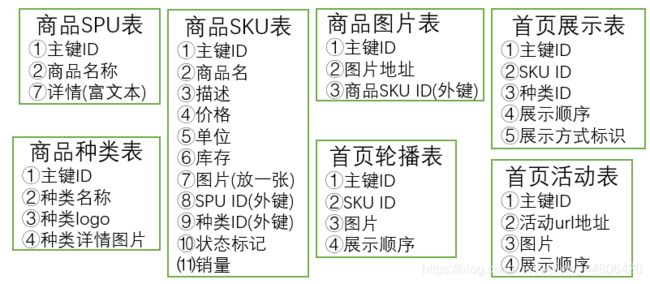
首页活动表用于展示一些活动图片(并附带活动链接);
首页轮播表用于展示一些轮播图片(具体轮播的效果在前端使用CSS完成);
首页展示表用于展示首页按分类排列后的一部分具体商品,展示方式意为以图片展示或以文字展示;
商品图片表用于存储商品图片,由于一种SKU商品可能有多张图片,因此将其专门提出制作一个表;
商品种类表用于存储商品的种类,即类似于水果/蔬菜/肉类此种大分类;
商品SKU与SPU表存储商品的具体信息。
注:虽然有专用于存储商品图片的商品图片表,但为了方便和减少查询次数起见还是在需要的表中添加了图片字段(用于存储一张显示于主页的图片),注意所有的图片类型其在数据库保存的都是一个图片的URL而非图片本身。
使用FastDFS保存图片
FastDFS在前文中已有过介绍,在Django中通过Nginx与FastDFS联用的方法可参考网上的方法或我的项目代码中的教程(github中),此处只描述流程。
配置FastDFS与Nginx与Django
其他部分略,在Django的配置中添加:
# 设置Django的文件存储类并指定路径,若不设置则默认为系统自带的文件存储类
DEFAULT_FILE_STORAGE = 'utils.fdfs.storage.FDFSStorage'
# 设置fdfs所需要的参数
FDFS_CLIENT_OPTION = {
'FDFS_CLIENT_CONF': './utils/fdfs/client.conf',
'BASE_URL': 'http://192.168.85.178:8888/',
'SERVER_IP': '192.168.85.178',
}
在相应的路径下即 项目主目录/utils/fdfs/storage.py 中自定义文件存储类,其需要依照Django的规范进行定义,代码如下:
from django.core.files.storage import Storage
from django.conf import settings
from fdfs_client.client import *
class FDFSStorage(Storage):
'''fdfs文件存储类'''
def __init__(self, option=None):
if not option:
self.option = settings.FDFS_CLIENT_OPTION
else:
self.option = option
def _open(self, name, mode='rb'):
'''需要返回一个文件对象,用于直接打开文件'''
pass
def _save(self, name, content):
'''保存文件时使用,name为选择上传文件的名字,content为一个包含上传文件内容的File类实例对象'''
conf = get_tracker_conf(self.option.get('FDFS_CLIENT_CONF'))
client = Fdfs_client(conf)
# 上传文件到fdfs中,根据内容上传文件
res = client.upload_by_buffer(content.read())
#res是一个字典格式的结果
if res.get('Status') != 'Upload successed.':
# 上传失败
raise Exception('上传文件失败')
filename = res.get('Remote file_id')
# 返回的内容即在数据表中保存的内容,由于返回的是bytes,将其解码
return filename.decode('utf-8')
def exists(self, name):
'''判断name在Django中是否可用,由于使用fdfs保存文件,因此直接返回False表示文件名可用'''
return False
def url(self, name):
'''返回访问文件的url路径'''
return (self.option.get('BASE_URL')+name)
配置完成后,在admin界面上传图片时就直接调用此重写的文件存储类,将数据保存于与Django关联的fdfs存储文件夹中,并返回一个拼接过的url用于访问。
浏览器访问图片的流程
如图所示。

注意此处生成的URL已经不是Django服务器的地址,而是配置的nginx服务器的地址,因此将其应用到模板中后,用户通过浏览器访问到的图片是直接通过nginx访问了fdfs中的图片,没有经过Django,减少了Django服务器的压力。
首页的显示与优化
商品首页的显示
商品首页的显示分为以下几个部分:
①首页广告;
②首页轮播商品;
③首页分类与分类商品;
④判断用户是否登录及购物车数目。
①②③:基础逻辑类似,从数据库中获取信息并传入模板,③中对于分类商品的显示,由于其显示的类型可能不同(图片或文字),因此可以动态的对查询到的商品种类模型类实例添加其对应的不同显示类型的商品模型类实例,减少模板使用中的逻辑,且代码整体更简洁。
④:判断用户是否登录,Django的认证系统会给每个请求添加user属性,可以方便的使用user.is_authenticated判断是否登录,然后获取购物车相关的信息,对于购物车的设计思路如下:
Ⅰ添加:当用户选择添加到购物车时需要添加购物车记录,详情页/列表页;
Ⅱ获取:当使用购物车数据和访问购物车页面时需要获取购物车记录;
Ⅲ存储:使用redis存储(在内存中);
Ⅳ如何存储:一个用户的购物车记录用一条数据保存,使用hash类型保存,cart_userid:{sku_id1:数量, sku_id2:数量}。
关于购物车的添加等功能在购物车模块中详细设计,此处直接查询数据库中购物车的相关数据,并提供一个数量参数传入模板。
商品首页的优化
关于网站页面(多为首页)的优化主要分为两部分,静态页面的使用和缓存的使用,如下:
①因为首页内容需要查询表单多,且变化频率不高,因此使用celery生成首页的静态页面,设置当管理员修改相应后台页面时重新生成;
②原因同上,但由于登录用户的用户信息需要在django中获取,因此使用django缓存,将页面信息存放在缓存中,使用时先从缓存中获取;
③目的:网站本身性能的优化,减少数据库查询的次数,防止恶意攻击,并在一定程度上防止DDOS攻击。
实现①:使用celery,生成的静态文件模板是没有用户登录的模板,生成页面即使用render方法渲染模板后不直接返回(因为生成的模板中不包含用户信息,因此需要使用新的模板用于渲染),将生成的内容写入文件(即生成一个新的html文件),生成的新文件位于celery服务器上,要实现此过程需要在celery中添加任务,并设置当管理员修改相应后台页面时重新生成,生成静态页面文件的代码如下:
def generate_static_index_html():
'''产生首页的静态页面'''
# 获取商品的种类信息
types = GoodsType.objects.all()
# 获取首页轮播商品信息
goods_banners = IndexGoodsBanner.objects.all().order_by('index')
# 获取首页促销活动信息
promotion_banners = IndexPromotionBanner.objects.all().order_by('index')
# 获取首页分类商品展示信息,由于不同种类的商品展示信息存储在同一个表中,因此需要对其进行分类,并对每一个种类的商品信息进行查询
for type in types:
title_banners = IndexTypeGoodsBanner.objects.filter(types=type, display_type=0)
image_banners = IndexTypeGoodsBanner.objects.filter(types=type, display_type=1)
# 将获取到的每个种类的商品信息添加到种类的实例属性中,此中type是GoodType的实例,因此可以随意添加实例属性
type.title_banners = title_banners
type.image_banners = image_banners
# 组织模板上下文
context = {
'types': types,
'goods_banners': goods_banners,
'promotion_banners': promotion_banners,
}
# 加载模板文件
temp = loader.get_template('static_index.html')
# 渲染模板生成一个大字符串
static_index_html = temp.render(context)
# 生成文件,拼接路径
save_path = os.path.join(settings.BASE_DIR, 'index.html')
with open(save_path, 'w') as f:
f.write(static_index_html)
在admin.py中重写Admin操作,并对所有在admin页面显示的模型类进行继承与注册,代码如下(即实现在admin操作时,重新生成静态文件页面):
from django.contrib import admin
from django.core.cache import cache
from goods.models import GoodsType, GoodsSKU, GoodsSPU, GoodsImage, IndexGoodsBanner, IndexTypeGoodsBanner, IndexPromotionBanner
class BaseModelAdmin(admin.ModelAdmin):
def save_model(self, request, obj, form, change):
'''在新增或修改模型类表时应用'''
super().save_model(request, obj, form, change)
from celery_tasks.tasks import generate_static_index_html
generate_static_index_html.delay()
# 删除缓存,由于view中缓存若不存在会生成,因此无需在此生成
cache.delete('index_page_data')
def delete_model(self, request, obj):
'''在删除模型类表中数据时使用'''
super().delete_model(request, obj)
from celery_tasks.tasks import generate_static_index_html
generate_static_index_html.delay()
# 删除缓存
cache.delete('index_page_data')
class GoodsTypeAdmin(BaseModelAdmin):
pass
class GoodsSKUAdmin(BaseModelAdmin):
pass
class GoodsSPUAdmin(BaseModelAdmin):
pass
class GoodsImageAdmin(BaseModelAdmin):
pass
class IndexGoodsBannerAdmin(BaseModelAdmin):
pass
class IndexTypeGoodsBannerAdmin(BaseModelAdmin):
pass
class IndexPromotionBannerAdmin(BaseModelAdmin):
pass
admin.site.register(GoodsType, GoodsTypeAdmin)
admin.site.register(GoodsSKU, GoodsSKUAdmin)
admin.site.register(GoodsSPU, GoodsSPUAdmin)
admin.site.register(GoodsImage, GoodsImageAdmin)
admin.site.register(IndexGoodsBanner, IndexGoodsBannerAdmin)
admin.site.register(IndexTypeGoodsBanner, IndexTypeGoodsBannerAdmin)
admin.site.register(IndexPromotionBanner, IndexPromotionBannerAdmin)
实现②:在用户访问首页时判断有无缓存,若有则无需重新查询表,直接渲染模板,若无则生成,注意在上述admin中重写了后台更改数据时删除缓存,保证用户访问时可以及时的获取到更新。(关于Django缓存的使用见前文)
注:①在生成了静态页面之后,配置nginx,通过一定的调度手段,使用户去访问Nginx服务器从(celery服务器上)获取静态页面而非从Django服务器上获取首页(因此无法使用Django中的用户信息);
②调度的实现方法(后详):在Django和celery/nginx服务器前添加一个nginx服务器专用于调度(即只暴露给用户这个nginx调度服务器的IP,提高了安全性),可以在调度服务器中设置ip:port/去访问celery/nginx静态页面,ip:port/index去访问django服务器(例如让所有用户都先访问静态页面,具体的链接点击时会访问Django服务器判断是否需要缓存)。
商品详情页的显示
在商品详情页中需要的内容有:
①SKU商品的名称图片等信息,并同SPU的其他商品;
②显示商品种类和种类新品;
③商品评论(由于评论位于订单模型类中,因此此处简略);
④用户购物车数量及当用户登录时添加历史浏览记录;
⑤添加到购物车的页面变化及数据库操作(位于购物车模块);
具体代码如下:
class DetailView(View):
'''商品详情页面'''
def get(self, request, goods_id):
# 尝试获取ID
try:
sku = GoodsSKU.objects.get(id=goods_id)
except GoodsSKU.DoesNotExit:
# 所查商品不存在,返回一个页面
return redirect(reverse(' goods:index '))
# 获取商品的分类信息
types = GoodsType.objects.all()
# 获取商品的评论信息,[对评论内容进行筛选]
sku_orders = OrderGoods.objects.filter(sku=sku)
# 获取该种类新品,通过创建时间排序,并切片取前两个
new_skus = GoodsSKU.objects.filter(types=sku.types).order_by('-create_time')[:2]
# 获取同一个SPU其他规格的商品
same_spu_skus = GoodsSKU.objects.filter(spu=sku.spu).exclude(id=goods_id)
# 获取用户购物车中商品数量
user = request.user
# 判断用户已登录
if user.is_authenticated:
conn = get_redis_connection('default')
cart_key = 'cart_{}'.format(user.id)
cart_count = conn.hlen(cart_key)
# 添加历史浏览记录
history_key = 'history_{}'.format(user.id)
# 对历史浏览记录是否重复进行判断和移除
conn.lrem(history_key, 0, goods_id)
# 添加当前的商品ID
conn.lpush(history_key, goods_id)
# 设置只保存用户最新浏览的5条信息
conn.ltrim(history_key, 0, 4)
else:
cart_count = 0
# 此处应该设置登录后跳转回原链接
# 组织模板上下文
context = {
'sku': sku,
'types': types,
'sku_orders': sku_orders,
'new_skus': new_skus,
'cart_count': cart_count,
'same_spu_skus': same_spu_skus,
}
return render(request, 'detail.html', context)
商品列表页的显示
商品列表页中,需要注意的点有:
①使用url来传入具体的type_id和排序方式,设置url的格式为 ‘/list/种类ID/页码?sort=排序方式’;
②设置分页显示,并通过解析url获取页码和排序方式;
③获取种类新品和购物车数量;
④根据指定的要求对页码的显示进行处理;
具体代码如下:
class ListView(View):
'''列表页'''
def get(self, request, type_id, page):
try:
# 获取当前分类
type_current = GoodsType.objects.get(id=type_id)
except GoodsType.DoesNotExist:
# 种类不存在
return redirect(reverse('goods:index'))
# 获取商品的分类信息
types = GoodsType.objects.all()
# 获取排序的方式及当前分类的商品
# sort=default默认排序
# sort=price价格排序
# sort=hot人气/销量排序
sort = request.GET.get('sort')
if sort == 'hot':
skus = GoodsSKU.objects.filter(types=type_current).order_by('-sales')
elif sort == 'price':
skus = GoodsSKU.objects.filter(types=type_current).order_by('price')
else:
sort = 'default'
skus = GoodsSKU.objects.filter(types=type_current).order_by('-id')
# 对数据进行分页
paginator = Paginator(skus, 2)
# 获取要求页码的内容
try:
page = int(page)
except Exception as e:
page = 1
# 判断页码是否超出
if page > paginator.num_pages:
page = 1
# 获取指定页码的内容
sku_page = paginator.page(page)
# 至多显示5个页码,显示当前页的前两页和后两页
# 1.页面小于5页,页面上显示所有页码
# 2.当前页是前3页,显示1-5页
# 3.当前页是后3页,显示后5页
# 4.其余:显示当前页的前两页和后两页
# 5.添加跳转到第几页和最后一页的按钮,后续实现
num_pages = paginator.num_pages
if num_pages <= 5:
pages = range(1, num_pages+1)
elif page <= 3:
pages = range(1, 6)
elif num_pages-page <= 2:
pages = range(num_pages-4, num_pages+1)
else:
pages = range(page-2, page+3)
# 获取该种类新品,通过创建时间排序,并切片取前两个
new_skus = GoodsSKU.objects.filter(types=type_current).order_by('-create_time')[:2]
# 获取用户购物车中商品数量
user = request.user
cart_count = 0
# 判断用户已登录
if user.is_authenticated:
conn = get_redis_connection('default')
cart_key = 'cart_{}'.format(user.id)
cart_count = conn.hlen(cart_key)
# 此参数用于改变页码时不改变排序方式,设计url
context = {
'type_current': type_current,
'types': types, 'skus': skus,
'new_skus': new_skus,
'cart_count': cart_count,
'sort': sort,
'skus_page': sku_page,
'pages': pages,
}
return render(request, 'list.html', context)
商品搜索
搜索引擎的简介见前文,此处使用haystack搜索引擎,并使用jieba分词模块,在Django中配置如下:
# 配置全文检索引擎的使用
HAYSTACK_CONNECTIONS = {
'default': {
#使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
#索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
#当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
并建立一个模板文件用于显示搜索结果,其传入模板的对象有:query:搜索关键字,page:自动分页后当前页内容,paginator:分页的paginator对象;其余具体配置过程比较固定,可参网上教程页或参具体代码,此处略。
以上即商品模块的全部内容,完整代码见https://github.com/Icemelon99/test_project。