(Hadoop)S10 Sqoop
简介
- 介绍:Sqoop是Apache的一款开源工具,Sqoop主要用于在Hadoop和关系数据库或大型机之间传输数据,可以使用Sqoop工具将数据从关系数据库管理系统导入(import)到Hadoop分布式文件系统中,或者将Hadoop中的数据转换导出(export)到关系数据库管理系统。
- 版本 Sqoop1是1.4.x。Sqoop是1.99.x。
- Sqoop1用于服务管理进行简单的数据迁移
- Sqoop2功能复杂强大(一般不用)
原理
- Sqoop是传统关系型数据库服务器与Hadoop间进行数据同步的工具,其底层利用MapReduce并行计算模型以批处理方式加快数据传输速度,并且具有较好的容错性功能,工作流程如下所示。

- Sqoop是关系型数据库与Hadoop之间的数据桥梁,这个桥梁的重要组件是Sqoop连接器,它用于实现与各种关系型数据库的连接,从而实现数据的导入和导出操作。可以连接大多数关系型数据库。如Mysql、Oracle、DB2还有一个通用的JDBC连接器。用于连接支持JDBC的数据库

导入原理
- 在导入数据之前,Sqoop使用JDBC检查导入的数据表,检索出表中的所有列以及列的SQL数据类型,并将这些SQL类型映射为Java数据类型,在转换后的MapReduce应用中使用这些对应的Java类型来保存字段的值,Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
导出原理
在导出数据前,Sqoop会根据目标表的定义生成一个Java类,这个生成的类能够从文本中解析出记录数据,并能够向表中插入类型合适的值,然后启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析出记录,并且执行选定的导出方法。
Sqoop的安装配置
- 下载sqoop镜像站

- 解压到/opt下并改名

- 复制conf下的sqoop-env-template.sh并改名个为sqoop-env.sh。
- 修改sqoop-env.sh
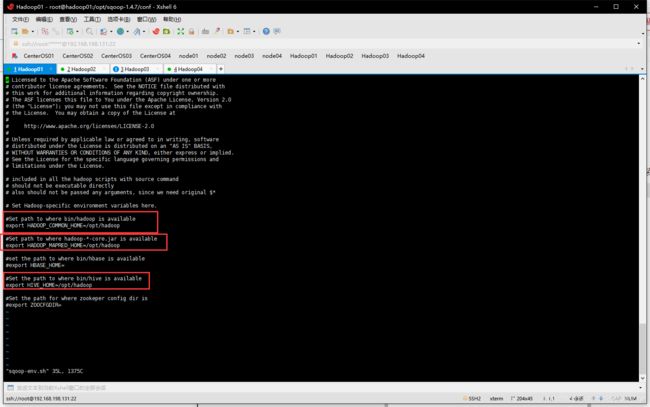
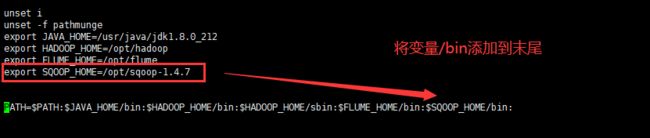
- 为sqoop添加环境变量
vi /etc/profile
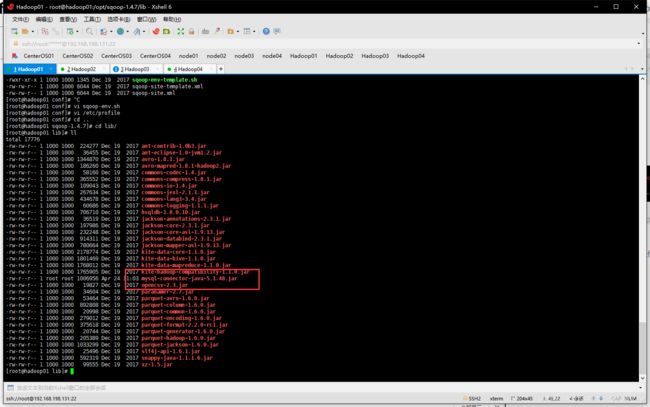
- 将 mysql-connector-java-5.1.32.jar包上传至Sqoop目录的lib目录下
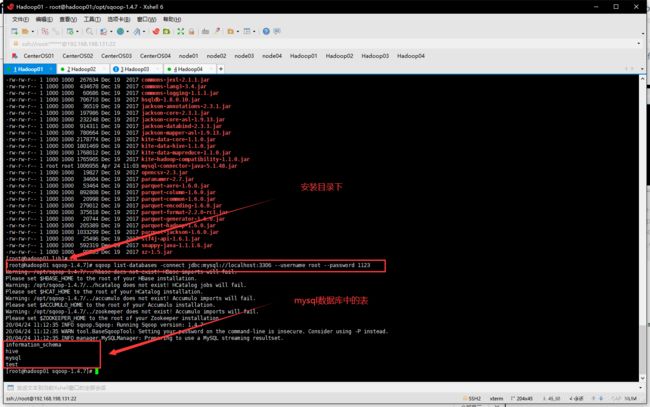
- 测试,在sqoop目录下
sqoop list-databases -connect jdbc:mysql://localhost:3306 --username root --password 1123
Sqoop指令
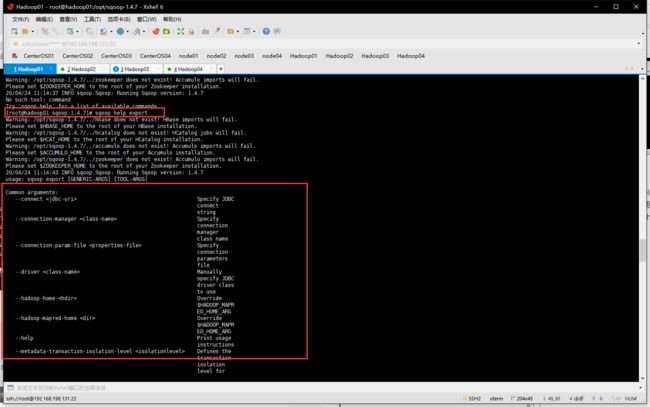
- Sqoop作为一款工具,开发者只需掌握工具的使用方式,它提供了一系列的工具指令,来进行数据的导入、导出操作等,开发人员只需输入”sqoop help“帮助指令查看帮助文档,如下所示。

- 执行Sqoop相关指令时,需要指定各种指令参数,可以使用“sqoop help command”指令来进行查看。例如查看数据导入import指令使用方式,可以使用“sqoop help import”指令进行查看,如下图所示。
数据导入
- Sqoop数据导入(import)是将关系型数据库中的单个表数据导入到HDFS、Hive等具有Hadoop分布式存储结构的文件系统中,表中的每一行都被视为一条记录,所有记录默认以文本文件格式进行逐行存储,还可以以二进制形式存储,例如Avro文件格式、序列文件格式(SequenceFile)。
连接数据库在hadoop01
mysql -uroot -p1123
准备数据
- 创建并使用userdb数据库
create database userdb;
user userdb
- 创建emp表并插入数据
CREATE TABLE emp (
'id' int(11) NOT NULL,
'name' varchar(100) DEFAULT NULL,
'deg' varchar(100) DEFAULT NULL,
'salary' int(11) DEFAULT NULL,
'dept' varchar(10) DEFAULT NULL,
PRIMARY KEY ('id')
);
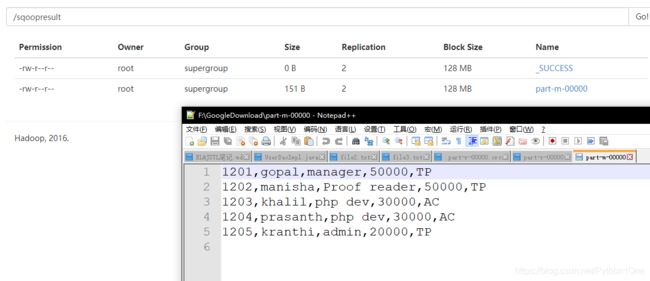
INSERT INTO emp VALUES ('1201', 'gopal', 'manager', '50000', 'TP');
INSERT INTO emp VALUES ('1202', 'manisha', 'Proof reader', '50000', 'TP');
INSERT INTO emp VALUES ('1203', 'khalil', 'php dev', '30000', 'AC');
INSERT INTO emp VALUES ('1204', 'prasanth', 'php dev', '30000', 'AC');
INSERT INTO emp VALUES ('1205', 'kranthi', 'admin', '20000', 'TP');
- 创建emp-add表并插入数据
CREATE TABLE emp_add (
'id' int(11) NOT NULL,
'hno' varchar(100) DEFAULT NULL,
'street' varchar(100) DEFAULT NULL,
'city' varchar(100) DEFAULT NULL,
PRIMARY KEY ('id')
);
INSERT INTO emp_add VALUES ('1201', '288A', 'vgiri', 'jublee');
INSERT INTO emp_add VALUES ('1202', '108I', 'aoc', 'sec-bad');
INSERT INTO emp_add VALUES ('1203', '144Z', 'pgutta', 'hyd');
INSERT INTO emp_add VALUES ('1204', '78B', 'old city', 'sec-bad');
INSERT INTO emp_add VALUES ('1205', '720X', 'hitec', 'sec-bad');
- 将emp表中的数据导入HDFS
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --target-dir /sqoopresult --table emp --num-mappers 1
| 参数 | 说明 |
|---|---|
| import | 导入操作 |
| –connect | 连接数据库 |
| –target-dir | 导入到HDFS的目标目录,自动创建 |
| –table | 指定哪张表 |
| –num-mappers | map的线程数目 |
增量导入
- 当MySQL表中的数据发生新增或修改变化,需要更新HDFS上对应的数据时,就可以使用Sqoop的增量导入功能,Sqoop目前支持两种增量导入模式:append模式(追加模式)和lastmodified模式(修改数据的增量导入)。
- append模式:主要针对insert新增数据的增量导入
- lastmodified模式:主要针对update修改数据的增量导入
向数据表emp进行增量导入
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --target-dir /sqoopresult --table emp --num-mappers 1 --incremental append --check-column id --last-value 1205 (1205是上一次的id最后一个)
| 参数 | 说明 |
|---|---|
| incremental | 模式选择 |
| –check-column | 根据参数用来检查哪个是新增的,一般设置为主键 |
| –last-value | 用于只增量last-value值以后的数据,存储到之前相应目录下的一个单独文件 |
- 向数据库新增一个数据
INSERT INTO emp VALUES ('1206', 'kranthi', 'admin', '20000', 'TP');
- 增量导入
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --target-dir /sqoopresult --table emp --num-mappers 1 --incremental append --check-column id --last-value 1205
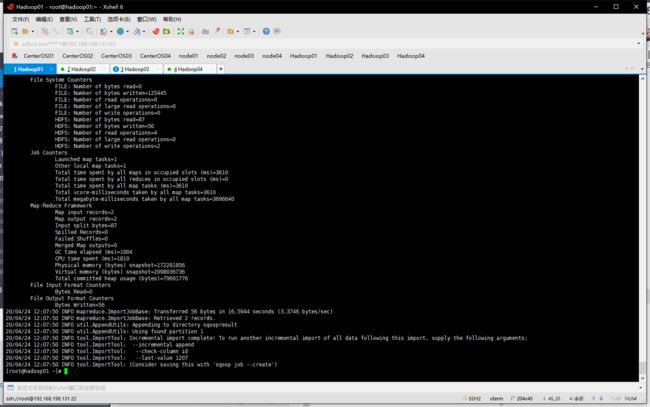

hadoop fs -cat /sqoopresult/part-m-00001

数据导入到Hive
- 要在sqoop的conf中的sqoop-env.sh配置了hive的安装路径(前面配置过了)
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --table emp_add --hive-table zcx.emp_add_sp --create-hive-table --hive-import --num-mappers 1
| 参数 | 说明 |
|---|---|
| hive-table | 意义是导入hive的哪个仓库的哪张表 仓库.表 |
| -create-hive-table | 如果表不存在,则自动创建 |
| –hive-import | 将mysql数据导入到hive |
- 首先确定在hive中有zcx数据库

- 配置HADOOP_CLASSPATH环境变量(因之前没有配置)
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_212
export HADOOP_HOME=/opt/hadoop
export HADOOP_CLASSPATH=/opt/hadoop/lib
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hive/lib/* # 必须有
export FLUME_HOME=/opt/flume
export SQOOP_HOME=/opt/sqoop-1.4.7
export HIVE_HOME=/opt/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf #必须有
PAT=H$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin::$FLUME_HOME/bin:$SQOOP_HOME/bin:$HIVE_HOME/bin:
- 导入数据
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --table emp_add --hive-table zcx.emp_add_sp --create-hive-table --hive-import --num-mappers 1

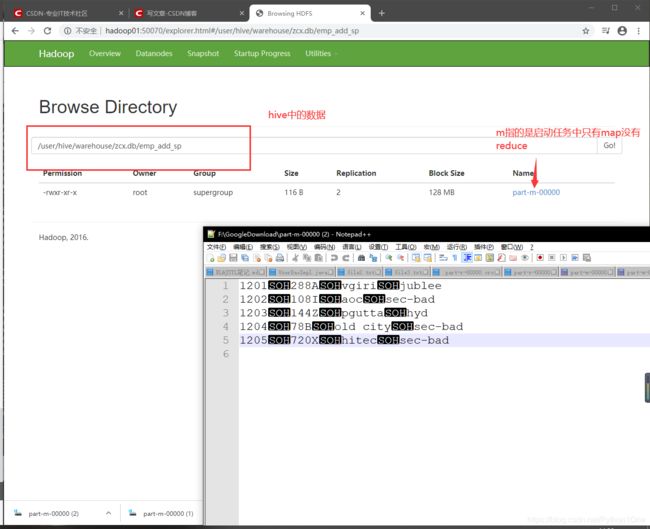
mysql表数据子集导入
where指令
- 对部分数据进行导入
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --where "city ='sec-bad'" --target-dir /wherequery --table emp_add --num-mappers 1
| 参数 | 说明 |
|---|---|
| –where | 添加条件 如"city =‘sec-bad’" |
| -target-dir | 将满足条件的导入到哪个文件夹 |
| –table | mysql中标的名字 |
- 启动
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --where "city ='sec-bad'" --target-dir /wherequery --table emp_add --num-mappers 1


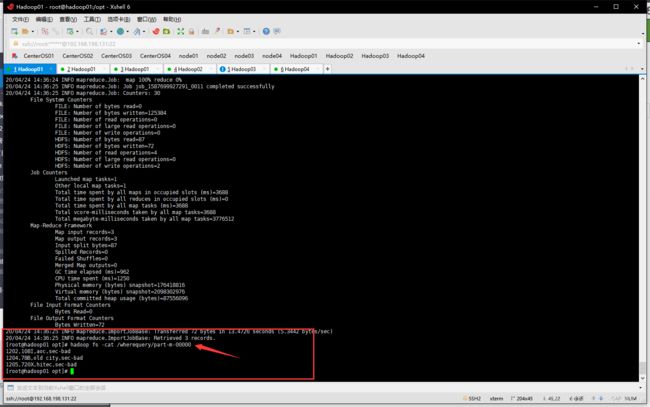
query指令
后面可以加sql查询语句
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --target-dir /wherequery2 --query 'SELECT id,name,deg FROM emp WHERE id>1203 AND $CONDITIONS' --num-mappers 1
| 参数 | 说明 |
|---|---|
| –query | 后面加sql语句 |
| AND $CONDITIONS | 若使用了where 必须在后面加AND $CONDITIONS |
注意
- 如果没有指定
--num-mappers 1(map任务个数1个)则需要添加--split-by参数,针对多副本map任务并执行查询结果进行数据导入以参数值为唯一字段。 - 若使用了where 必须在后面加
AND $CONDITIONS - 若使用了双引号对CONDITIONS,那么前面要加\进行转义
sqoop import --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --target-dir /wherequery2 --query 'SELECT id,name,deg FROM emp WHERE id>1203 AND $CONDITIONS' --num-mappers 1
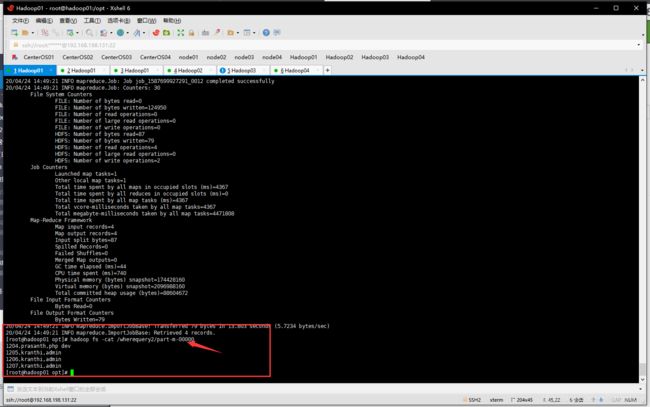
数据导出
- Sqoop导出与导入是相反的操作,也就是将HDFS、Hive、Hbase等文件系统或数据仓库中的数据导出到关系型数据库中,在导出操作之前,目标表必须存在于目标数据库中,否则在执行导出操作时会失败。
将HDFS下的/sqoopresult/part-m-00000写入到mysql
- 创建mysql数据表
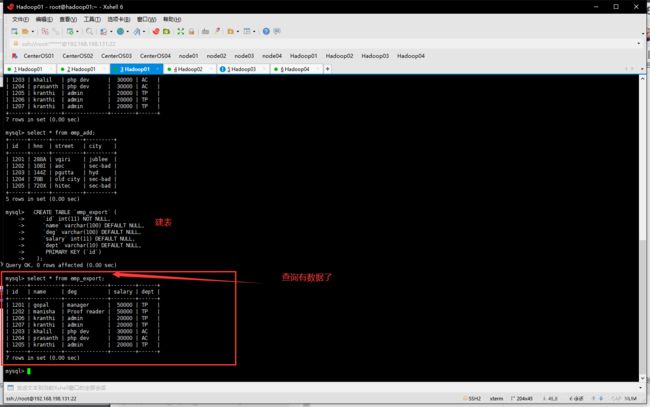
CREATE TABLE emp_export (
`id` int(11) NOT NULL,
`name` varchar(100) DEFAULT NULL,
`deg` varchar(100) DEFAULT NULL,
`salary` int(11) DEFAULT NULL,
`dept` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`)
);
- 导出指令
sqoop export --connect jdbc:mysql://hadoop01:3306/userdb --username root --password 1123 --table emp_export --export-dir /sqoopresult
| 参数 | 说明 |
|---|---|
| export | 导出参数 |
| –table | 指定mysql目标表名 |
| –export-dir | 指定导出的文件 |