Python入门3
目录:
39.用文件保存游戏(1)
40.用文件保存游戏(2)
41.用文件保存游戏(3)
42.函数的默认参数
43.面向对象(1)
44.面向对象(2)
45.面向对象(3)
46.面向对象(4)
47.and-or技巧
48.元组
49.数学运算
50.真值表
51.正则表达式(1)
52.正则表达式(2)
53.正则表达式(3)
54.正则表达式(4)
55.正则表达式(5)
56.随机数
57.计时
58.pickle
59.列表解析
60.函数的参数传递(1)
61.函数的参数传递(2)
62.函数的参数传递(3)
63.lambda表达式
64.变量的作用域
65.map函数
66.reduce函数
67.多线程
39.用文件保存游戏(1)
到目前为止,python最入门的语法我们都已经有所涉及,相信大家一路学过来,多少也能写出一些小程序。在接下来的课程中,我会基于实例来更深入地介绍python。现在,我要在最早我们开发的那个猜数字游戏的基础上,增加保存成绩的功能。用到的方法就是前几课讲过的文件读写。今天是第一部分。
在动手写代码前,先想清楚我们要解决什么问题,打算怎么去解决。你可以选择根据每次游戏算出一个得分,记录累计的得分。也可以让每次猜错都扣xx分,猜对之后再加xx分,记录当前分数。而我现在打算记录下我玩了多少次,最快猜出来的轮数,以及平均每次猜对用的轮数。
于是,我要在文件中记录3个数字,如:
3 5 31
它们分别是:总游戏次数,最快猜出的轮数,和猜过的总轮数(这里我选择记录总轮数,然后每次再算出平均轮数)
接下来可以往代码里加功能了,首先是读取成绩。新建好一个game.txt,里面写上:
0 0 0
作为程序的初始数据。
用之前的方法,读入文件:
f = open('e:\py\game.txt')
score = f.read().split()
这里,我用了open方法,它和file()的效果一样。另外,我还用了绝对路径。当你写这个程序时,记得用你自己电脑上的路径。
为便于理解,把数据读进来后,分别存在3个变量中。
game_times = int(score[0])
min_times = int(score[1])
total_times = int(score[2])
平均轮数根据总轮数和游戏次数相除得到:
avg_times = float(total_times) / game_times
注意两点:
1.我在total_times前加上了float,把它转成了浮点数类型再进行除法运算。如果不这样做,两个整数相除的结果会默认为整数,而且不是四舍五入。
2.因为0是不能作为除数的,所以这里还需要加上判断:
if game_times > 0:
avg_times = float(total_times) / game_times
else:
avg_times = 0
然后,在让玩家开始猜数字前,输出他之前的成绩信息:
print '你已经玩了%d次,最少%d轮猜出答案,平均%.2f轮猜出答案' % (game_times, min_times, avg_times)
%.2f这样的写法我们以前也用过,作用是保留两位小数。
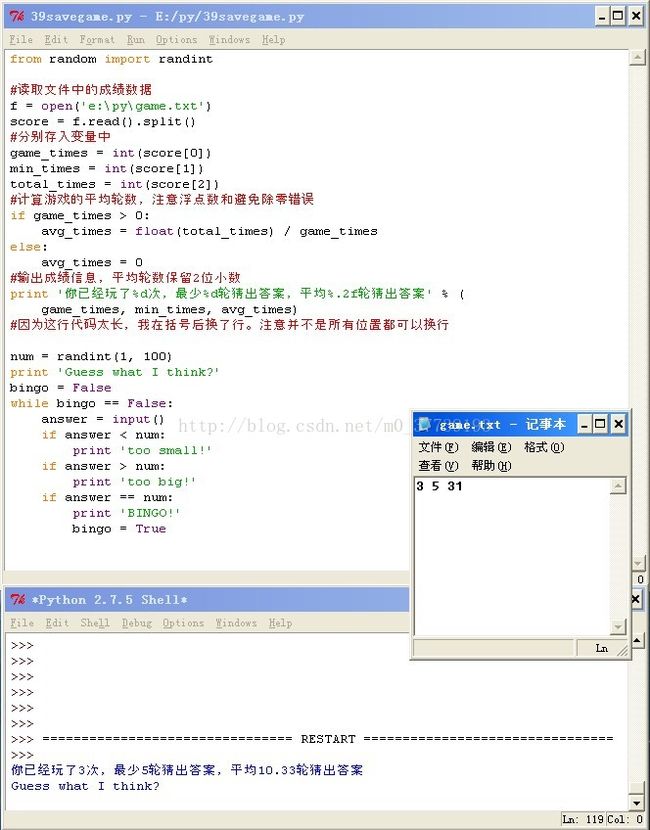
好了,运行程序看一下效果:
你已经玩了0次,最少0轮猜出答案,平均0轮猜出答案
由于还没有做保存功能,我们手动去文件里改一下成绩看运行效果。(其实有些小游戏就可以用类似的方法作弊)
下一节,我们要把真实的游戏数据保存到文件中。
40.用文件保存游戏(2)
话接上回。我们已经能从文件中读取游戏成绩数据了,接下来就要考虑,怎么把我们每次游戏的结果保存进去。
首先,我们需要有一个变量来记录每次游戏所用的轮数:
times = 0
然后在游戏每进行一轮的时候,累加这个变量:
times += 1
当游戏结束后,我们要把这个变量的值,也就是本次游戏的数据,添加到我们的记录中。
如果是第一次玩,或者本次的轮数比最小轮数还少,就记录本次成绩为最小轮数:
if game_times == 0 or times < min_times:
min_times = times
把本次轮数加到游戏总轮数里:
total_times += times
把游戏次数加1:
game_times += 1
现在有了我们需要的数据,把它们拼成我们需要存储的格式:
result = '%d %d %d' % (game_times, min_times, total_times)
写入到文件中:
f = open('e:\py\game.txt', 'w')
f.write(result)
f.close()

按照类似的方法,你也可以记录一些其他的数据,比如设定一种记分规则作为游戏得分。虽然在这个小游戏里,记录成绩并没有太大的乐趣,但通过文件来记录数据的方法,以后会在很多程序中派上用场。
41.用文件保存游戏(3)
你的小游戏现在已经可以保存成绩了,但只有一组成绩,不管谁来玩,都会算在里面。所以今天我还要加上一个更多的功能:存储多组成绩。玩家需要做的就是,在游戏开始前,输入自己的名字。而我会根据这个名字记录他的成绩。这个功能所用到的内容我们几乎都说过,现在要把它们结合起来。
首先要输入名字,这是我们用来区分玩家成绩的依据:
name = raw_input('请输入你的名字:')
接下来,我们读取文件。与之前不同,我们用readlines把每组成绩分开来:
lines = f.readlines()
再用一个字典来记录所有的成绩:
scores = {}
for l in lines:
s = l.split()
scores[s[0]] = s[1:]
这个字典中,每一项的key是玩家的名字,value是一个由剩下的数据组成的数组。这里每一个value就相当于我们之前的成绩数据。
我们要找到当前玩家的数据:
score = scores.get(name)
字典类的get方法是按照给定key寻找对应项,如果不存在这样的key,就返回空值None。
所以如果没有找到该玩家的数据,说明他是一个新玩家,我们给他初始化一组成绩:
if score is None:
score = [0, 0, 0]
这是我们拿到的score,已经和上一课中的score一样了,因此剩下的很多代码都不用改动。
当游戏结束,记录成绩的时候,和之前的方法不一样。我们不能直接把这次成绩存到文件里,那样就会覆盖掉别人的成绩。必须先把成绩更新到scores字典中,再统一写回文件中。
把成绩更新到scores中,如果没有这一项,会自动生成新条目:
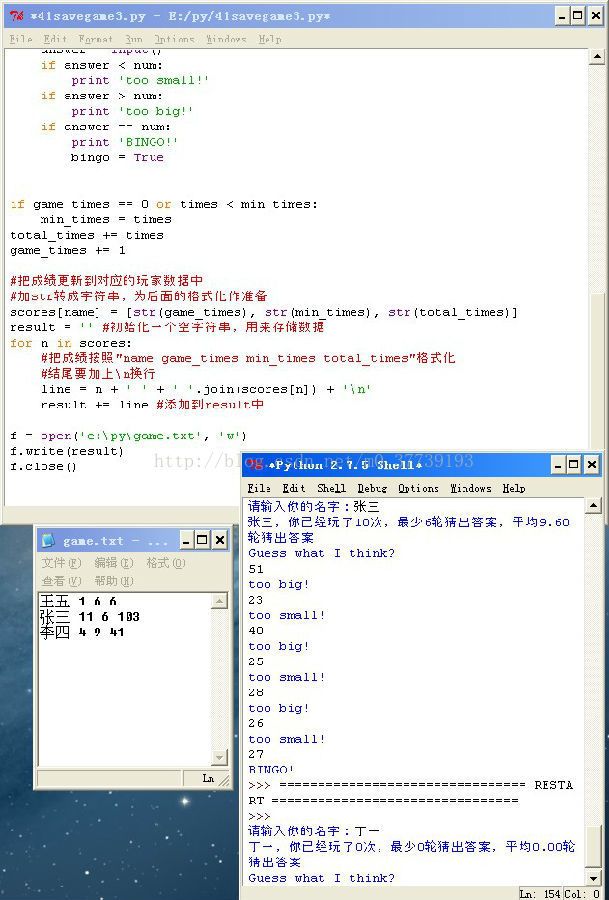
scores[name] = [str(game_times), str(min_times), str(total_times)]
对于每一项成绩,我们要将其格式化:
result = ''
for n in scores:
line = n + ' ' + ' '.join(scores[n]) + '\n'
result += line
把scores中的每一项按照“名字 游戏次数 最低轮数 总轮数\n”的格式拼成字符串,再全部放到result里,就得到了我们要保存的结果。
最后就和之前一样,把result保存到文件中。

如果你充分理解了这个程序,恭喜你,你对文件处理已经有了一个基本的了解。在日常工作学习中,如果需要处理一些大量重复机械的文件操作,比如整理格式、更改文件中的部分文字、统计数据等等,都可以试着用python来解决。
42.函数的默认参数
今天分享一点小技巧。之前我们用过函数,比如:
def hello(name):
print 'hello ' + name
然后我们去调用这个函数:
hello('world')
程序就会输出
hello world
如果很多时候,我们都是用world来调用这个函数,少数情况才会去改参数。那么,我们就可以给这个函数一个默认参数:
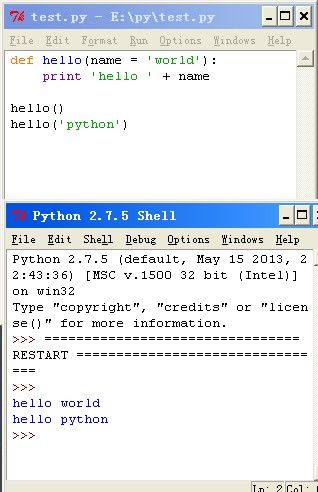
def hello(name = 'world'):
print 'hello ' + name
当你没有提供参数值时,这个参数就会使用默认值;如果你提供了,就用你给的。
这样,在默认情况下,你只要调用
hello()
就可以输出
hello world
同样你也可以指定参数:
hello('python')
输出
hello python
注意,当函数有多个参数时,如果你想给部分参数提供默认参数,那么这些参数必须在参数的末尾。比如:
def func(a, b=5)
是正确的
def func(a=5, b)
就会出错
43.面向对象(1)
我们之前已经写了不少小程序,都是按照功能需求的顺序来设计程序。这种被称为“面向过程”的编程。
还有一种程序设计的方法,把数据和对数据的操作用一种叫做“对象”的东西包裹起来。这种被成为“面向对象”的编程。这种方法更适合较大型的程序开发。
面向对象编程最主要的两个概念就是:类(class)和对象(object)
类是一种抽象的类型,而对象是这种类型的实例。
举个现实的例子:
“笔”作为一个抽象的概念,可以被看成是一个类。而一支实实在在的笔,则是“笔”这种类型的对象。
一个类可以有属于它的函数,这种函数被称为类的“方法”。
一个类/对象可以有属于它的变量,这种变量被称作“域”。
域根据所属不同,又分别被称作“类变量”和“实例变量”。
继续笔的例子。一个笔有书写的功能,所以“书写”就是笔这个类的一种方法。
每支笔有自己的颜色,“颜色”就是某支笔的域,也是这支笔的实例变量。
而关于“类变量”,我们假设有一种限量版钢笔,我们为这种笔创建一种类。而这种笔的“产量”就可以看做这种笔的类变量。因为这个域不属于某一支笔,而是这种类型的笔的共有属性。
域和方法被合称为类的属性。
python是一种高度面向对象的语言,它其中的所有东西其实都是对象。所以我们之前也一直在使用着对象。看如下的例子:
s = 'how are you'
#s被赋值后就是一个字符串类型的对象
l = s.split()
#split是字符串的方法,这个方法返回一个list类型的对象
#l是一个list类型的对象
通过dir()方法可以查看一个类/变量的所有属性:
dir(s)
dir(list)
下节课,我们来自己创建一个类。
44.面向对象(2)
昨天介绍了面向对象的概念,今天我们来创建一个类。
class MyClass:
pass
mc = MyClass()
print mc类名加圆括号()的形式可以创建一个类的实例,也就是被称作对象的东西。我们把这个对象赋值给变量mc。于是,mc现在就是一个MyClass类的对象。
看一下输出结果:
<__main__.MyClass instance at 0x7fd1c8d01200>
这个意思就是说,mc是__main__模块中MyClass来的一个实例(instance),后面的一串十六进制的数字是这个对象的内存地址。
我们给这个类加上一些域:
class MyClass:
name = 'Sam'
def sayHi(self):
print 'Hello %s' % self.name
mc = MyClass()
print mc.name
mc.name = 'Lily'
mc.sayHi()调用类变量的方法是“对象.变量名”。你可以得到它的值,也可以改变它的值。
注意到,类方法和我们之前定义的函数区别在于,第一个参数必须为self。而在调用类方法的时候,通过“对象.方法名()”格式进行调用,而不需要额外提供self这个参数的值。self在类方法中的值,就是你调用的这个对象本身。
输出结果:
Sam
Hello Lily
之后,在你需要用到MyClass这种类型对象的地方,就可以创建并使用它。
45.面向对象(3)
面向对象是比较复杂的概念,初学很难理解。我曾经对人夸张地说,面向对象是颠覆你编程三观的东西,得花上不少时间才能搞清楚。我自己当年初学Java的时候,也是折腾了很久才理清点头绪。所以我在前面的课程中没有去提及类和对象这些概念,不想在一开始给大家造成混淆。
在刚开始编程的时候,从上到下一行行执行的简单程序容易被理解,即使加上if、while、for之类的语句以及函数调用,也还是不算困难。有了面向对象之后,程序的执行路径就变得复杂,很容易让人混乱。不过当你熟悉之后会发现,面向对象是比面向过程更合理的程序设计方式。
今天我用一个例子来展示两种程序设计方式的不同。
假设我们有一辆汽车,我们知道它的速度(60km/h),以及A、B两地的距离(100km)。要算出开着这辆车从A地到B地花费的时间。(很像小学数学题是吧?)
面向过程的方法:
speed = 60.0
distance = 100.0
time = distance / speed
print time
面向对象的方法:
class Car:
speed = 0
def drive(self, distance):
time = distance / self.speed
print time
car = Car()
car.speed = 60.0
car.drive(100.0)但是,如果我们让题目再稍稍复杂一点。假设我们又有了一辆更好的跑车,它的速度是150km/h,然后我们除了想从A到B,还要从B到C(距离200km)。要求分别知道这两种车在这两段路上需要多少时间。
面向过程的方法:
speed1 = 60.0
distance1 = 100.0
time1 = distance1 / speed1
print time1
distance2 = 200.0
time2 = distance2 / speed1
print time2
speed2 = 150.0
time3 = distance1 / speed2
print time3
time4 = distance2 / speed2
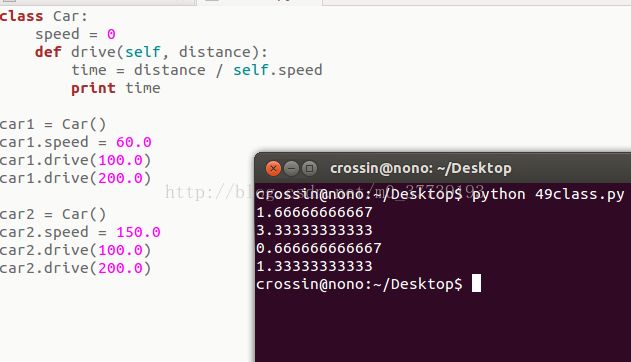
print time4class Car:
speed = 0
def drive(self, distance):
time = distance / self.speed
print time
car1 = Car()
car1.speed = 60.0
car1.drive(100.0)
car1.drive(200.0)
car2 = Car()
car2.speed = 150.0
car2.drive(100.0)
car2.drive(200.0)面向对象的水还很深,我们这里只是粗略一瞥。它不再像之前print、while这些概念那么一目了然。但也没必要对此畏惧,等用多了自然就熟悉了。找一些实例亲手练练,会掌握得更快。遇到问题时,欢迎来论坛和群里讨论。
46.面向对象(4)
上一课举了一个面向对象和面向过程相比较的例子之后,有些同学表示,仍然没太看出面向对象的优势。没关系,那是因为我们现在接触的程序还不够复杂,等以后你写的程序越来越大,就能体会到这其中的差别了。
今天我们就来举一个稍稍再复杂一点的例子。
仍然是从A地到B地,这次除了有汽车,我们还有了一辆自行车!
自行车和汽车有着相同的属性:速度(speed)。还有一个相同的方法(drive),来输出行驶/骑行一段距离所花的时间。但这次我们要给汽车增加一个属性:每公里油耗(fuel)。而在汽车行驶一段距离的方法中,除了要输出所花的时间外,还要输出所需的油量。
面向过程的方法,你可能需要写两个函数,然后把数据作为参数传递进去,在调用的时候要搞清应该使用哪个函数和哪些数据。有了面向对象,你可以把相关的数据和方法封装在一起,并且可以把不同类中的相同功能整合起来。这就需要用到面向对象中的另一个重要概念:继承。
我们要使用的方法是,创建一个叫做Vehicle的类,表示某种车,它包含了汽车和自行车所共有的东西:速度,行驶的方法。然后让Car类和Bike类都继承这个Vehicle类,即作为它的子类。在每个子类中,可以分别添加各自独有的属性。
Vehicle类被称为基本类或超类,Car类和Bike类被成为导出类或子类。
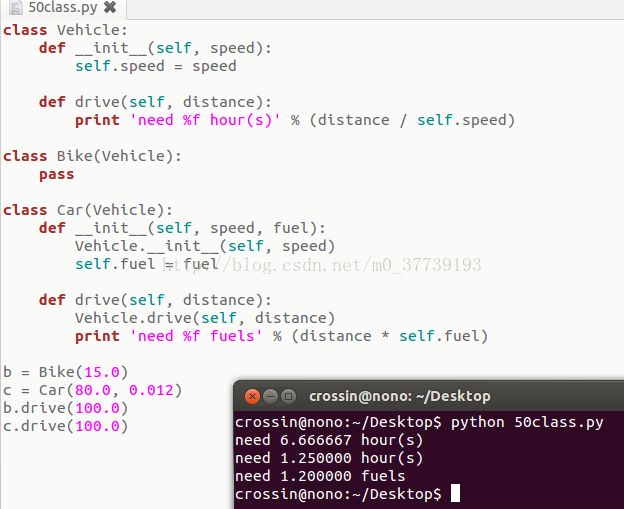
class Vehicle:
def __init__(self, speed):
self.speed = speed
def drive(self, distance):
print 'need %f hour(s)' % (distance / self.speed)
class Bike(Vehicle):
pass
class Car(Vehicle):
def __init__(self, speed, fuel):
Vehicle.__init__(self, speed)
self.fuel = fuel
def drive(self, distance):
Vehicle.drive(self, distance)
print 'need %f fuels' % (distance * self.fuel)
b = Bike(15.0)
c = Car(80.0, 0.012)
b.drive(100.0)
c.drive(100.0)__init__函数会在类被创建的时候自动调用,用来初始化类。它的参数,要在创建类的时候提供。于是我们通过提供一个数值来初始化speed的值。
注意:__init__是python的内置方法,类似的函数名前后是两个下英文划线,如果写错了,则不会起到原本应有的作用。
class定义后面的括号里表示这个类继承于哪个类。Bike(Vehicle)就是说Bike是继承自Vehicle中的子类。Vehicle中的属性和方法,Bike都会有。因为Bike不需要有额外的功能,所以用pass在类中保留空块,什么都不用写。
Car类中,我们又重新定义了__init__和drive函数,这样会覆盖掉它继承自Vehicle的同名函数。但我们依然可以通过“Vehicle.函数名”来调用它的超类方法。以此来获得它作为Vehicle所具有的功能。注意,因为是通过类名调用方法,而不是像之前一样通过对象来调用,所以这里必须提供self的参数值。在调用超类的方法之后,我们又给Car增加了一个fuel属性,并且在drive中多输出一行信息。
最后,我们分别创建一个速度为15的自行车对象,和一个速度为80、耗油量为0.012的汽车,然后让它们去行驶100的距离。
47.and-or技巧
今天介绍一个python中的小技巧:and-or
看下面这段代码:
a = "heaven"
b = "hell"
c = True and a or b
print c
d = False and a or b
print d
输出:
heaven
hell
结果很奇怪是不是?
表达式从左往右运算,1和"heaven"做and的结果是"heaven",再与"hell"做or的结果是"heaven";0和"heaven"做and的结果是0,再与"hell"做or的结果是"hell"。
抛开绕人的and和or的逻辑,你只需记住,在一个bool and a or b语句中,当bool条件为真时,结果是a;当bool条件为假时,结果是b。
有学过c/c++的同学应该会发现,这和bool?a:b表达式很像。
有了它,原本需要一个if-else语句表述的逻辑:
if a > 0:
print "big"
else:
print "small"
就可以直接写成:
print (a > 0) and "big" or "small"
然而不幸的是,如果直接这么用,有一天你会踩到坑的。和c语言中的?:表达式不同,这里的and or语句是利用了python中的逻辑运算实现的。当a本身是个假值(如0,"")时,结果就不会像你期望的那样。
比如:
a = ""
b = "hell"
c = True and a or b
print c
得到的结果不是""而是"hell"。因为""和"hell"做or的结果是"hell"。
所以,and-or真正的技巧在于,确保a的值不会为假。最常用的方式是使 a 成为 [a] 、 b 成为 [b],然后使用返回值列表的第一个元素:
a = ""
b = "hell"
c = (True and [a] or [b])[0]
print c
由于[a]是一个非空列表,所以它决不会为假。即使a是0或者''或者其它假值,列表[a]也为真,因为它有一个元素。
在两个常量值进行选择时,and-or会让你的代码更简单。但如果你觉得这个技巧带来的副作用已经让你头大了,没关系,用if-else可以做相同的事情。不过在python的某些情况下,你可能没法使用if语句,比如lambda函数中,这时候你可能就需要and-or的帮助了。
什么是lambda函数?呵呵,这是python的高阶玩法,暂且按住不表,以后有机会再说。
48.元组
上一次pygame的课中有这样一行代码:
x, y = pygame.mouse.get_pos()
这个函数返回的其实是一个“元组”,今天我们来讲讲这个东西。
元组(tuple)也是一种序列,和我们用了很多次的list类似,只是元组中的元素在创建之后就不能被修改。
如:
postion = (1, 2)
geeks = ('Sheldon', 'Leonard', 'Rajesh', 'Howard')
都是元组的实例。它有和list同样的索引、切片、遍历等操作(参见25~27课):
print postion[0]
for g in geeks:
print g
print geeks[1:3]
其实我们之前一直在用元组,就是在print语句中:
print '%s is %d years old' % ('Mike', 23)
('Mike', 23)就是一个元组。这是元组最常见的用处。
再来看一下元组作为函数返回值的例子:
def get_pos(n):
return (n/2, n*2)
得到这个函数的返回值有两种形式,一种是根据返回值元组中元素的个数提供变量:
x, y = get_pos(50)
print x
print y
这就是我们在开头那句代码中使用的方式。
还有一种方法是用一个变量记录返回的元组:
pos = get_pos(50)
print pos[0]
print pos[1]
49.数学运算
说些python的基础。
在用计算机编程解决问题的过程中,数学运算是很常用的。python自带了一些基本的数学运算方法,这节课给大家介绍一二。
python的数学运算模块叫做math,再用之前,你需要
import math
math包里有两个常量:
math.pi
圆周率π:3.141592...
math.e
自然常数:2.718281...
数值运算:
math.ceil(x)
对x向上取整,比如x=1.2,返回2.0(py3返回2)
math.floor(x)
对x向下取整,比如x=1.2,返回1.0(py3返回1)
math.pow(x,y)
指数运算,得到x的y次方
math.log(x)
对数,默认基底为e。可以使用第二个参数,来改变对数的基底。比如math.log(100, 10)
math.sqrt(x)
平方根
math.fabs(x)
绝对值
三角函数:
math.sin(x)
math.cos(x)
math.tan(x)
math.asin(x)
math.acos(x)
math.atan(x)
注意:这里的x是以弧度为单位,所以计算角度的话,需要先换算
角度和弧度互换:
math.degrees(x)
弧度转角度
math.radians(x)
角度转弧度
以上是你平常可能会用到的函数。除此之外,还有一些,这里就不罗列,可以去
http://docs.python.org/2/library/math.html
查看官方的完整文档。
有了这些函数,可以更方便的实现程序中的计算。比如中学时代算了无数次的
(-b±√(b2-4ac))/2a
现在你就可以写一个函数,输入一元二次方程的a、b、c系数,直接给你数值解。好,这题就留作课后作业吧。
50.真值表
逻辑判断是编程中极为常用的知识。之前的课我们已经说过,见第6课和第11课。但鉴于逻辑运算的重要性,今天我再把常用的运算结果总结一下,供大家参考。
这种被称为“真值表”的东西,罗列了基本逻辑运算的结果。你不一定要全背下来,但应该对运算的规律有所了解。
为了便于看清,我用<=>来表示等价关系。
<=>左边表示逻辑表达式,<=>右边表示它的结果。
NOT
not False <=> True
not True <=> False
(not的结果与原值相反)
OR
True or False <=> True
True or True <=> True
False or True <=> True
False or False <=> False
(只要有一个值为True,or的结果就是True)
AND
True and False <=> False
True and True <=> True
False and True <=> False
False and False <=> False
(只要有一个值为False,and的结果就是False)
NOT OR
not (True or False) <=> False
not (True or True) <=> False
not (False or True) <=> False
not (False or False) <=> True
NOT AND
not (True and False) <=> True
not (True and True) <=> False
not (False and True) <=> True
not (False and False) <=> True
!=
1 != 0 <=> True
1 != 1 <=> False
0 != 1 <=> True
0 != 0 <=> False
==
1 == 0 <=> False
1 == 1 <=> True
0 == 1 <=> False
0 == 0 <=> True51.正则表达式(1)
今天来挖个新坑,讲讲正则表达式。
什么是正则表达式?在回答这个问题之前,先来看看为什么要有正则表达式。
在编程处理文本的过程中,经常会需要按照某种规则去查找一些特定的字符串。比如知道一个网页上的图片都是叫做'image/8554278135.jpg'之类的名字,只是那串数字不一样;又或者在一堆人员电子档案中,你要把他们的电话号码全部找出来,整理成通讯录。诸如此类工作,如果手工去做,当量大的时候那简直就是悲剧。但你知道这些字符信息有一定的规律,可不可以利用这些规律,让程序自动来做这些无聊的事情?答案是肯定的。这时候,你就需要一种描述这些规律的方法,正则表达式就是干这事的。
正则表达式就是记录文本规则的代码。
所以正则表达式并不是python中特有的功能,它是一种通用的方法。python中的正则表达式库,所做的事情是利用正则表达式来搜索文本。要使用它,你必须会自己用正则表达式来描述文本规则。之前多次有同学表示查找文本的事情经常会遇上,希望能介绍一下正则表达式。既然如此,我们就从正则表达式的基本规则开始说起。
(1).首先说一种最简单的正则表达式,它没有特殊的符号,只有基本的字母或数字。它满足的匹配规则就是完全匹配。例如:有个正则表达式是“hi”,那么它就可以匹配出文本中所有含有hi的字符。
来看如下的一段文字:
Hi, I am Shirley Hilton. I am his wife.
如果我们用“hi”这个正则表达式去匹配这段文字,将会得到两个结果。因为是完全匹配,所以每个结果都是“hi”。这两个“hi”分别来自“Shirley”和“his”。默认情况下正则表达式是严格区分大小写的,所以“Hi”和“Hilton”中的“Hi”被忽略了。
为了验证正则表达式匹配的结果,你可以用以下这段代码做实验:
import re
text = "Hi, I am Shirley Hilton. I am his wife."
m = re.findall(r"hi", text)
if m:
print m
else:
print 'not match'(2).如果我们只想找到“hi”这个单词,而不把包含它的单词也算在内,那就可以使用“\bhi\b”这个正则表达式。在以前的字符串处理中,我们已经见过类似“\n”这种特殊字符。在正则表达式中,这种字符更多,以后足以让你眼花缭乱。
“\b”在正则表达式中表示单词的开头或结尾,空格、标点、换行都算是单词的分割。而“\b”自身又不会匹配任何字符,它代表的只是一个位置。所以单词前后的空格标点之类不会出现在结果里。
在前面那个例子里,“\bhi\b”匹配不到任何结果。但“\bhi”的话就可以匹配到1个“hi”,出自“his”。用这种方法,你可以找出一段话中所有单词“Hi”,想一下要怎么写。
(3).最后再说一下[]这个符号。在正则表达式中,[]表示满足括号中任一字符。比如“[hi]”,它就不是匹配“hi”了,而是匹配“h”或者“i”。
在前面例子中,如果把正则表达式改为“[Hh]i”,就可以既匹配“Hi”,又匹配“hi”了。
52.正则表达式(2)
有同学问起昨天那段测试代码里的问题,我来简单说一下。
(1).r"hi"
这里字符串前面加了r,是raw的意思,它表示对字符串不进行转义。为什么要加这个?你可以试试print "\bhi"和r"\bhi"的区别。
>>> print "\bhi"
hi
>>> print r"\bhi"
\bhi
可以看到,不加r的话,\b就没有了。因为python的字符串碰到“\”就会转义它后面的字符。如果你想在字符串里打“\”,则必须要打“\\”。
>>> print "\\bhi"
\bhi
这样的话,我们的正则表达式里就会多出很多“\”,让本来就已经复杂的字符串混乱得像五仁月饼一般。但加上了“r”,就表示不要去转义字符串中的任何字符,保持它的原样。
(2).re.findall(r"hi", text)
re是python里的正则表达式模块。findall是其中一个方法,用来按照提供的正则表达式,去匹配文本中的所有符合条件的字符串。返回结果是一个包含所有匹配的list。
(3).今天主要说两个符号“.”和“*”,顺带说下“\S”和“?”。
“.”在正则表达式中表示除换行符以外的任意字符。在上节课提供的那段例子文本中:
Hi, I am Shirley Hilton. I am his wife.
如果我们用“i.”去匹配,就会得到
['i,', 'ir', 'il', 'is', 'if']
你若是暴力一点,也可以直接用“.”去匹配,看看会得到什么。
与“.”类似的一个符号是“\S”,它表示的是不是空白符的任意字符。注意是大写字符S。
(4).在很多搜索中,会用“?”表示任意一个字符,“*”表示任意数量连续字符,这种被称为通配符。但在正则表达式中,任意字符是用“.”表示,而“*”则不是表示字符,而是表示数量:它表示前面的字符可以重复任意多次(包括0次),只要满足这样的条件,都会被表达式匹配上。
结合前面的“.*”,用“I.*e”去匹配,想一下会得到什么结果?
['I am Shirley Hilton. I am his wife']
是不是跟你想的有些不一样?也许你会以为是
['I am Shirle', 'I am his wife']
这是因为“*”在匹配时,会匹配尽可能长的结果。如果你想让他匹配到最短的就停止,需要用“.*?”。如“I.*?e”,就会得到第二种结果。这种匹配方式被称为懒惰匹配,而原本尽可能长的方式被称为贪婪匹配。
最后留一道习题:
从下面一段文本中,匹配出所有s开头,e结尾的单词。
site sea sue sweet see case sse ssee loses
53.正则表达式(3)
先来公布上一课习题的答案:
\bs\S*e\b
有的同学给出的答案是"\bs.*?e\b"。测试一下就会发现,有奇怪的'sea sue'和'sweet see'混进来了。既然是单词,我们就不要空格,所以需要用"\S"而不是"."
有位同学在论坛上说,用正则表达式匹配出了文件中的手机号。这样现学现用很不错。匹配的规则是"1.*?\n",在这个文件的条件下,是可行的。但这规则不够严格,且依赖于手机号结尾有换行符。今天我来讲讲其他的方法。
匹配手机号,其实就是找出一串连续的数字。更进一步,是11位,以1开头的数字。
还记得正则第1讲里提到的[]符号吗?它表示其中任意一个字符。所以要匹配数字,我们可以用
[0123456789]
由于它们是连续的字符,有一种简化的写法:[0-9]。类似的还有[a-zA-Z]的用法。
还有另一种表示数字的方法:
\d
要表示任意长度的数字,就可以用
[0-9]*
或者
\d*
但要注意的是,*表示的任意长度包括0,也就是没有数字的空字符也会被匹配出来。一个与*类似的符号+,表示的则是1个或更长。
所以要匹配出所有的数字串,应当用
[0-9]+
或者
\d+
如果要限定长度,就用{}代替+,大括号里写上你想要的长度。比如11位的数字:
\d{11}
想要再把第一位限定为1,就在前面加上1,后面去掉一位:
1\d{10}
OK. 总结一下今天提到的符号:
[0-9]
\d
+
{}
现在你可以去一个混杂着各种数据的文件里,抓出里面的手机号,或是其他你感兴趣的数字了。
54.正则表达式(4)
(1).我们已经了解了正则表达式中的一些特殊符号,如\b、\d、.、\S等等。这些具有特殊意义的专用字符被称作“元字符”。常用的元字符还有:
\w - 匹配字母或数字或下划线或汉字(我试验下了,发现3.x版本可以匹配汉字,但2.x版本不可以)
\s - 匹配任意的空白符
^ - 匹配字符串的开始
$ - 匹配字符串的结束
(2).\S其实就是\s的反义,任意不是空白符的字符。同理,还有:
\W - 匹配任意不是字母,数字,下划线,汉字的字符
\D - 匹配任意非数字的字符
\B - 匹配不是单词开头或结束的位置
[a]的反义是[^a],表示除a以外的任意字符。[^abcd]就是除abcd以外的任意字符。
(3).之前我们用过*、+、{}来表示字符的重复。其他重复的方式还有:
? - 重复零次或一次
{n,} - 重复n次或更多次
{n,m} - 重复n到m次
正则表达式不只是用来从一大段文字中抓取信息,很多时候也被用来判断输入的文本是否符合规范,或进行分类。来点例子看看:
^\w{4,12}$
这个表示一段4到12位的字符,包括字母或数字或下划线或汉字,可以用来作为用户注册时检测用户名的规则。(但汉字在python2.x里面可能会有问题)
\d{15,18}
表示15到18位的数字,可以用来检测身份证号码
^1\d*x?
以1开头的一串数字,数字结尾有字母x,也可以没有。有的话就带上x。
另外再说一下之前提到的转义字符\。如果我们确实要匹配.或者*字符本身,而不是要它们所代表的元字符,那就需要用\.或\*。\本身也需要用\\。
比如"\d+\.\d+"可以匹配出123.456这样的结果。
留一道稍稍有难度的习题:
写一个正则表达式,能匹配出多种格式的电话号码,包括
(021)88776543
010-55667890
02584453362
0571 66345673
55.正则表达式(5)
来说上次的习题:
(021)88776543
010-55667890
02584453362
0571 66345673
一个可以匹配出所有结果的表达式是
\(?0\d{2,3}[) -]?\d{7,8}
解释一下:
\(?
()在正则表达式里也有着特殊的含义,所以要匹配字符"(",需要用"\("。?表示这个括号是可有可无的。
0\d{2,3}
区号,0xx或者0xxx
[) -]?
在区号之后跟着的可能是")"、" "、"-",也可能什么也没有。
\d{7,8}
7或8位的电话号码
可是,这个表达式虽然能匹配出所有正确的数据(一般情况下,这样已经足够),但理论上也会匹配到错误的数据。因为()应当是成对出现的,表达式中对于左右两个括号并没有做关联处理,例如(02188776543这样的数据也是符合条件的。
我们可以用正则表达式中的“|”符号解决这种问题。“|”相当于python中“or”的作用,它连接的两个表达式,只要满足其中之一,就会被算作匹配成功。
于是我们可以把()的情况单独分离出来:
\(0\d{2,3}\)\d{7,8}
其他情况:
0\d{2,3}[ -]?\d{7,8}
合并:
\(0\d{2,3}\)\d{7,8}|0\d{2,3}[ -]?\d{7,8}
使用“|”时,要特别提醒注意的是不同条件之间的顺序。匹配时,会按照从左往右的顺序,一旦匹配成功就停止验证后面的规则。假设要匹配的电话号码还有可能是任意长度的数字(如一些特殊的服务号码),你应该把
|\d+
这个条件加在表达式的最后。如果放在最前面,某些数据就可能会被优先匹配为这一条件。你可以写个测试用例体会一下两种结果的不同。
关于正则表达式,我们已经讲了5篇,介绍了正则表达式最最皮毛的一些用法。接下来,这个话题要稍稍告一段落。推荐一篇叫做《正则表达式30分钟入门教程》的文章(直接百度一下就能找到,我也会转到论坛上),想要对正则表达式进一步学习的同学可以参考。这篇教程是个标题党,里面涉及了正则表达式较多的内容,30分钟绝对看不完。
56.随机数
说一说python中的random模块。
random模块的作用是产生随机数。之前的小游戏中用到过random中的randint:
import random
num = random.randint(1,100)
random.randint(a, b)可以生成一个a到b间的随机整数,包括a和b。
a、b都必须是整数,且必须b≥a。当等于的时候,比如:
random.randint(3, 3)
的结果就永远是3
除了randint,random模块中比较常用的方法还有:
random.random()
生成一个0到1之间的随机浮点数,包括0但不包括1,也就是[0.0, 1.0)。
random.uniform(a, b)
生成a、b之间的随机浮点数。不过与randint不同的是,a、b无需是整数,也不用考虑大小。
random.uniform(1.5, 3)
random.uniform(3, 1.5)
这两种参数都是可行的。
random.uniform(1.5, 1.5)永远得到1.5。
random.choice(seq)
从序列中随机选取一个元素。seq需要是一个序列,比如list、元组、字符串。
random.choice([1, 2, 3, 5, 8, 13]) #list
random.choice('hello') #字符串
random.choice(['hello', 'world']) #字符串组成的list
random.choice((1, 2, 3)) #元组
都是可行的用法。
random.randrange(start, stop, step)
生成一个从start到stop(不包括stop),间隔为step的一个随机数。start、stop、step都要为整数,且start
random.randrange(1, 9, 2)
就是从[1, 3, 5, 7]中随机选取一个。
start和step都可以不提供参数,默认是从0开始,间隔为1。但如果需要指定step,则必须指定start。
random.randrange(4) #[0, 1, 2, 3]
random.randrange(1, 4) #[1, 2, 3]
random.randrange(start, stop, step)其实在效果上等同于
random.choice(range(start, stop, step))
random.sample(population, k)
从population序列中,随机获取k个元素,生成一个新序列。sample不改变原来序列。
random.shuffle(x)
把序列x中的元素顺序打乱。shuffle直接改变原有的序列。
以上是random中常见的几个方法。如果你在程序中需要其中某一个方法,也可以这样写:
from random import randint
randint(1, 10)
另外,有些编程基础的同学可能知道,在随机数中有个seed的概念,需要一个真实的随机数,比如此刻的时间、鼠标的位置等等,以此为基础产生伪随机数。在python中,默认用系统时间作为seed。你也可以手动调用random.seed(x)来指定seed。
57.计时
Python中有一个time模块,它提供了一些与时间相关的方法。利用time,可以简单地计算出程序运行的时间。对于一些比较复杂、耗时较多的程序,可以通过这种方法了解程序中哪里是效率的瓶颈,从而有针对性地进行优化。
在计算机领域有一个特殊的时间,叫做epoch,它表示的时间是1970-01-01 00:00:00 UTC。
Python中time模块的一个方法
time.time()
返回的就是从epoch到当前的秒数(不考虑闰秒)。这个值被称为unix时间戳。
于是我们可以用这个方法得到程序开始和结束所用的时间,进而算出运行的时间:
import time
starttime = time.time()
print 'start:%f' % starttime
for i in range(10):
print i
endtime = time.time()
print 'end:%f' % endtime
print 'total time:%f' % (endtime-starttime) 有了这个方法,我们还可以在Pygame课程中的打飞机游戏里,得到每一次游戏主循环刷新的时间,计算出游戏的每秒帧数,显示在屏幕上。
顺便再说下time中的另一个很有用的方法:
time.sleep(secs)
它可以让程序暂停secs秒。例如:
import time
print 1
time.sleep(3)
print 2
在抓取网页的时候,适当让程序sleep一下,可以减少短时间内的请求,提高请求的成功率。
58.pickle
在使用文件存储时,通常需要对数据进行一些处理,按照一定的规范把数据整理成文本,再写入文件中。下次使用时,从文件中读出文本,再按照此规范解析这些数据。
这种将数据转成文本的过程又被称为“序列化”,即将对象状态转换为可保持或传输的格式的过程。对应的,从序列化的格式中解析对象状态的过程被称为“反序列化”。
在之前的课程和示例中,我们都自己手动实现了这个过程。其实Python提供了一个标准模块来做这件事,就是pickle。它可以把任何Python对象存储在文件中,再把它原样取出来。
来看一下存储的过程:
import pickle
test_data = ['Save me!', 123.456, True]
f = file('test.data', 'w')
pickle.dump(test_data, f)
f.close()(lp0
S'Save me!'
p1
aF123.456
aI01
a.
这就是经 pickle 序列化后的数据,隐约可以看到之前对象的影子。你可能无法看出这个文件的规律,这没关系,Python能看懂就可以了。
下面取存储的过程:
import pickle
f = file('test.data')
test_data = pickle.load(f)
f.close()
print test_data['Save me!', 123.456, True]
和存储前的数据是一致的。
如果你想保存多个对象,一种方法是把这些对象先全部放在一个序列中,在对这个序列进行存储:
a = 123
b = "hello"
c = 0.618
data = (a, b, c)
...
pickle.dump(data, f)
另一种方法就是依次保存和提取:
...
pickle.dump(a, f)
pickle.dump(b, f)
pickle.dump(c, f)
...
x = pickle.load(f)
y = pickle.load(f)
z = pickle.load(f)
dump 方法可以增加一个可选的参数,来指定用二进制来存储:
pickle.dump(data, f, True)
而 load 方法会自动检测数据是二进制还是文本格式,无需手动指定。
Python还提供了另一个模块cPickle,它的功能及用法和pickle模块完全相同,只不过它是用C语言编写的,因此要快得多(比pickle快1000倍)。因此你可以把上述代码中的pickle全部替换为cPickle,从而提高运行速度(尽管在这个小程序中影响微乎其微)。
59.列表解析
Python 里一个我非常喜欢的特性--列表解析(List Comprehension)。所谓列表解析(也有翻译成列表综合),就是通过一个已有的列表生成一个新的列表。
直接看例子:
假设有一个由数字组成的 list,现在需要把其中的偶数项取出来,组成一个新的 list。一种比较“正常”的方法是:
list_1 = [1, 2, 3, 5, 8, 13, 22]
list_2 = []
for i in list_1:
if i % 2 == 0:
list_2.append(i)
print list_2[2, 8, 22]
此方法通过循环来遍历列表,对其中的每一个元素进行判断,若模取2的结果为0则添加至新列表中。
使用列表解析实现同样的效果:
list_1 = [1, 2, 3, 5, 8, 13, 22]
list_2 = [i for i in list_1 if i % 2 == 0]
print list_2[2, 8, 22]
[i for i in list_1] 会把 list_1 中的每一个元素都取出来,构成一个新的列表。
如果需要对其中的元素进行筛选,就在后面加上判断条件if。所以 [i for i in list_1 if i % 2 == 0] 就是把 list_1 中满足 i % 2 == 0 的元素取出来组成新列表。
进一步的,在构建新列表时,还可以对于取出的元素做操作。比如,对于原列表中的偶数项,取出后要除以2,则可以通过 [i / 2 for i in list_1 if i % 2 == 0] 来实现。输出为 [1, 4, 11]。
在实际开发中,适当地使用列表解析可以让代码更加简洁、易读,降低出错的可能。
留一道作业:
用一行 Python 代码实现:把1到100的整数里,能被2、3、5整除的数取出,以分号(;)分隔的形式输出。
60.函数的参数传递(1)
先说下上次课最后留的那题,我自己的解法:
print ';'.join([str(i) for i in range(1,101) if i % 2 == 0 and i % 3 == 0 and i % 5 == 0])
另外,关于上次说的 List Comprehension,我在文中称之为“列表综合”,这是引自《简明 Python 教程》的翻译。也有同学表示叫做“列表解析”或“列表表达式”。都是一个意思,其实在写这课之前,我从来都不去“叫”它,只知道这么用而已。
===================
我们曾经讲过Python中函数的参数传递。最基本的方式是:
定义
def func(arg1, arg2):
print arg1, arg2
调用
func(3, 7)
我们把函数定义时的参数名(arg1、arg2)称为形参,调用时提供的参数(3、7)称为实参。
这种方式是根据调用时提供参数的位置进行匹配,要求实参与行参的数量相等,默认按位置匹配参数。调用时,少参数或者多参数都会引起错误。这是最常用的一种函数定义方式。
在调用时,也可以根据形参的名称指定实参。如:
func(arg2=3, arg1=7)
但同样,必须提供所有的参数。看看和func(3, 7)的运行结果有什么不同。
Python 语言还提供了其他一些更灵活的参数传递方式,如:
func2(a=1, b=2, c=3)
func3(*args)
func4(**kargs)
今天我们先说说func2这种方式。
这种方式可以理解为,在一般函数定义的基础上,增加了参数的默认值。这样定义的函数可以和原来一样使用,而当你没有提供足够的参数时,会用默认值作为参数的值。
例如:
定义
def func(arg1=1, arg2=2, arg3=3):
print arg1, arg2, arg3
调用
func(2, 3, 4)
func(5, 6)
func(7)
输出为
2 3 4
5 6 3
7 2 3
提供的参数会按顺序先匹配前面位置的参数,后面未匹配到的参数使用默认值。
也可以指定其中的部分参数,如:
func(arg2=8)
func(arg3=9, arg1=10)
输出为
1 8 3
10 2 9
或者混合起来用:
func(11, arg3=12)
输出为
11 2 12
但要注意,没有指定参数名的参数必须在所有指定参数名的参数前面,且参数不能重复。以下的调用都是错误的:
func(arg1=13, 14)
func(15, arg1=16)
定义参数默认值的函数可以在调用时更加简洁。大量 Python 模块中的方法都运用了这一方式,让使用者在调用时可以提供尽可能少的参数。
接下来的几次课,我会继续介绍其他的参数传递方式。
61.函数的参数传递(2)
接着上一次的内容,来介绍一种更加灵活的参数传递方式:
def func(*args)
这种方式的厉害之处在于,它可以接受任意数量的参数。来看具体例子:
def calcSum(*args):
sum = 0
for i in args:
sum += i
print sumcalcSum(1,2,3)
calcSum(123,456)
calcSum()
输出:
6
579
0
在变量前加上星号前缀(*),调用时的参数会存储在一个 tuple(元组)对象中,赋值给形参。在函数内部,需要对参数进行处理时,只要对这个 tuple 类型的形参(这里是 args)进行操作就可以了。因此,函数在定义时并不需要指明参数个数,就可以处理任意参数个数的情况。
不过有一点需要注意,tuple 是有序的,所以 args 中元素的顺序受到赋值时的影响。如:
def printAll(*args):
for i in args:
print i,
print调用:
printAll(1,2,3)
printAll(3,2,1)
输出:
1 2 3
3 2 1
虽然3个参数在总体上是相同的,但由于调用的顺序不一样,结果也是不同的。
还有一种参数传递方式,既可以按参数名传递参数,不受位置的限制,又可以像 tuple 传递一样不受数量限制。这个我将在下次课中做介绍。
62.函数的参数传递(3)
今天来说说最为灵活的一种参数传递方式:
func(**kargs)
上次说的 func(*args) 方式是把参数作为 tuple 传入函数内部。而 func(**kargs) 则是把参数以键值对字典的形式传入。
示例:
def printAll(**kargs):
for k in kargs:
print k, ':', kargs[k]
printAll(a=1, b=2, c=3)
printAll(x=4, y=5)a : 1
c : 3
b : 2
y : 5
x : 4
字典是无序的,所以在输出的时候,并不一定按照提供参数的顺序。同样在调用时,参数的顺序无所谓,只要对应合适的形参名就可以了。于是,采用这种参数传递的方法,可以不受参数数量、位置的限制。
当然,这还不够。Python 的函数调用方式非常灵活,前面所说的几种参数调用方式,可以混合在一起使用。看下面这个例子:
def func(x, y=5, *a, **b):
print x, y, a, b
func(1)
func(1,2)
func(1,2,3)
func(1,2,3,4)
func(x=1)
func(x=1,y=1)
func(x=1,y=1,a=1)
func(x=1,y=1,a=1,b=1)
func(1,y=1)
func(1,2,3,4,a=1)
func(1,2,3,4,k=1,t=2,o=3)1 5 () {}
1 2 () {}
1 2 (3,) {}
1 2 (3, 4) {}
1 5 () {}
1 1 () {}
1 1 () {'a': 1}
1 1 () {'a': 1, 'b': 1}
1 1 () {}
1 2 (3, 4) {'a': 1}
1 2 (3, 4) {'k': 1, 't': 2, 'o': 3}
在混合使用时,首先要注意函数的写法,必须遵守:
带有默认值的形参(arg=)须在无默认值的形参(arg)之后;
元组参数(*args)须在带有默认值的形参(arg=)之后;
字典参数(**kargs)须在元组参数(*args)之后。
可以省略某种类型的参数,但仍需保证此顺序规则。
调用时也需要遵守:
指定参数名称的参数要在无指定参数名称的参数之后;
不可以重复传递,即按顺序提供某参数之后,又指定名称传递。
而在函数被调用时,参数的传递过程为:
(1).按顺序把无指定参数的实参赋值给形参;
(2).把指定参数名称(arg=v)的实参赋值给对应的形参;
(3).将多余的无指定参数的实参打包成一个 tuple 传递给元组参数(*args);
(4).将多余的指定参数名的实参打包成一个 dict 传递给字典参数(**kargs)。
是不是乍一看有点绕?没关系,赶紧打开你的编辑器,自行体会一下不同调用方式的用法。然后在未来的编程实践中慢慢熟悉吧。
63.lambda表达式
Python 是一门简洁的语言,lambda 表达式则充分体现了 Python 这一特点。
lambda 表达可以被看做是一种匿名函数。它可以让你快速定义一个极度简单的单行函数。譬如这样一个实现三个数相加的函数:
def sum(a, b, c):
return a + b + c
print sum(1, 2, 3)
print sum(4, 5, 6)6
15
如果使用 lambda 表达式来实现:
sum = lambda a, b, c: a + b + c
print sum(1, 2, 3)
print sum(4, 5, 6)6
15
两种方法的结果是相同的。
lambda 表达式的语法格式:
lambda 参数列表: 表达式
定义 lambda 表达式时,参数列表周围没有括号,返回值前没有 return 关键字,也没有函数名称。
它的写法比 def 更加简洁。但是,它的主体只能是一个表达式,不可以是代码块,甚至不能是命令(print 不能用在 lambda 表达式中)。所以 lambda 表达式能表达的逻辑很有限。
lambda 表达式创建了一个函数对象,可以把这个对象赋值给一个变量进行调用,就像上面的例子中一样。
来看一个复杂一点的例子,把 lambda 表达式用在 def 函数定义中:
def fn(x):
return lambda y: x + y
a = fn(2)
print a(3)5
这里,fn 函数的返回值是一个 lambda 表达式,也就等于是一个函数对象。当以参数2来调用 fn 时,得到的结果就是:
lambda y: 2 + y
a = fn(2) 就相当于:
a = lambda y: 2 + y
所以 a(3) 的结果就是5。
lambda 表达式其实只是一种编码风格,这种写法更加 pythonic。这并不意味着你一定要使用它。事实上,任何可以使用 lambda 表达式的地方,都可以通过普通的 def 函数定义来替代。在一些需要重复使用同一函数的地方,def 可以避免重复定义函数。况且 def 函数更加通用,某些情况可以带来更好地代码可读性。
而对于像 filter、sort 这种需要内嵌函数的方法,lambda 表达式就会显得比较合适。这个我以后会再单独介绍。
当然对于初学者来说,了解 lambda 表达式还有一个重要作用就是,看懂别人写的代码。
64.变量的作用域
在写代码的时候,免不了要使用变量。但程序中的一个变量并不一定是在哪里都可以被使用,根据情况不同,会有不同的“有效范围”。看这样一段代码:
def func(x):
print 'X in the beginning of func(x): ', x
x = 2
print 'X in the end of func(x): ', x
x = 50
func(x)
print 'X after calling func(x): ', xX in the beginning of func(x): 50
X in the end of func(x): 2
X after calling func(x): 50
变量 x 在函数内部被重新赋值。但在调用了函数之后,x 的值仍然是50。为什么?
这就得说一下变量的“作用域”:
当函数内部定义了一个变量,无论是作为函数的形参,或是另外定义的变量,它都只在这个函数的内部起作用。函数外即使有和它名称相同的变量,也没有什么关联。这个函数体就是这个变量的作用域。像这样在函数内部定义的变量被称为“局部变量”。
要注意的是,作用域是从变量被定义的位置开始。像这样的写法是有问题的:
def func():
print y
y = 2
print y UnboundLocalError: local variable 'y' referenced before assignment
因为在 y = 2 之前,y 并不存在,调用 y 的值就会出错。
回到开始那个例子:
在函数 func 外部,定义的变量 x,赋值为 50,作为参数传给了函数 func。而在函数 func 内部,变量 x 是形参,它的作用域是整个函数体内部。它与外面的那个 x 没有关系。只不过它的初始值是由外面那个 x 传递过来的。
所以,虽然函数体内部的 x 被重新赋值为 2,也不会影响外面那个 x 的值。
不过有时候,我们希望能够在函数内部去改变一些变量的值,并且这些变量在函数外部同样被使用到。怎么办?
一种方法是,用 return 把改变后的变量值作为函数返回值传递出来,赋值给对应的变量。比如开始的那个例子,可以在函数结尾加上
return x
然后把调用改为
x = func(x)
还有一种方法,就是使用“全局变量”。
在 Python 的函数定义中,可以给变量名前加上 global 关键字,这样其作用域就不再局限在函数块中,而是全局的作用域。
通过 global 改写开始的例子:
def func():
global x
print 'X in the beginning of func(x): ', x
x = 2
print 'X in the end of func(x): ', x
x = 50
func()
print 'X after calling func(x): ', xX in the beginning of func(x): 50
X in the end of func(x): 2
X after calling func(x): 2
函数 func 不再提供参数调用。而是通过 global x 告诉程序:这个 x 是一个全局变量。于是函数中的 x 和外部的 x 就成为了同一个变量。这一次,当 x 在函数 func 内部被重新赋值后,外部的 x 也随之改变。
前面讲的局部变量和全局变量是 Python 中函数作用域最基本的情况。实际上,还有一些略复杂的情况,比如:
def func():
print 'X in the beginning of func(x): ', x
# x = 2
print 'X in the end of func(x): ', x
x = 50
func()
print 'X after calling func(x): ', xX in the beginning of func(x): 50
X in the end of func(x): 50
X after calling func(x): 50
程序可以正常运行。虽然没有指明 global,函数内部还是使用到了外部定义的变量。然而一旦加上
x = 2
这句,程序就会报错。因为这时候,x 成为一个局部变量,它的作用域从定义处开始,到函数体末尾结束。
建议在写代码的过程中,显式地通过 global 来使用全局变量,避免在函数中直接使用外部变量。
65.map函数
来看两个问题:
(1). 假设有一个数列,如何把其中每一个元素都翻倍?
(2). 假设有两个数列,如何求和?
第一个问题,普通程序员大概会这么写:
lst_1 = [1,2,3,4,5,6]
lst_2 = []
for item in lst_1:
lst_2.append(item * 2)
print lst_2lst_1 = [1,2,3,4,5,6]
lst_2 = [i * 2 for i in lst_1]
print lst_2lst_1 = [1,2,3,4,5,6]
def double_func(x):
return x * 2
lst_2 = map(double_func, lst_1)
print lst_2map 的第一个参数是一个函数,之后的参数是序列,可以是 list、tuple。
所以刚刚那个问题也可以写成:
lst_1 = (1,2,3,4,5,6)
lst_2 = map(lambda x: x * 2, lst_1)
print lst_2map 中的函数可以对多个序列进行操作。最开始提出的第二个问题,除了通常的 for 循环写法,如果用列表综合的方法比较难实现,但用 map 就比较方便:
lst_1 = [1,2,3,4,5,6]
lst_2 = [1,3,5,7,9,11]
lst_3 = map(lambda x, y: x + y, lst_1, lst_2)
print lst_3对于每组数据中的元素个数,如果有某组数据少于其他组,map 会以 None 来补全这组参数。
此外,当 map 中的函数为 None 时,结果将会直接返回参数组成的列表。如果只有一组序列,会返回元素相同的列表,如果有多组数列,将会返回每组数列中,对应元素构成的元组所组成的列表。听上去很绕口是不是……代码试试看就明白了:
lst_1 = [1,2,3,4,5,6]
lst_2 = [1,3,5,7,9,11]
lst_3 = map(None, lst_1)
print lst_3
lst_4 = map(None, lst_1, lst_2)
print lst_4上次说了Python中一个比较有意思的内置函数 map,今天再来介绍另一个类似的函数:reduce
map可以看作是把一个序列根据某种规则,映射到另一个序列。reduce做的事情就是把一个序列根据某种规则,归纳为一个输出。
上栗子。以前我们给过一个习题,求1累加到100的和。寻常的做法大概是这样:
sum = 0
for i in xrange(1, 101):
sum += i
print sumlst = xrange(1, 101)
def add(x, y):
return x + y
print reduce(add, lst)reduce(function, iterable[, initializer])
第一个参数是作用在序列上的方法,第二个参数是被作用的序列,这与 map 一致。另外有一个可选参数,是初始值。
function 需要是一个接收2个参数,并有返回值的函数。它会从序列 iterable 里从左到右依次取出元素,进行计算。每次计算的结果,会作为下次计算的第一个参数。
提供初始值 initializer 时,它会作为第一次计算的第一个参数。否则,就先计算序列中的前两个值。
如果把刚才的 lst 换成 [1,2,3,4,5],那 reduce(add, lst) 就相当于 ((((1+2)+3)+4)+5)。
同样,可以用 lambda 函数:
reduce((lambda x, y: x + y), xrange(1, 101))
所以,在对于一个序列进行某种统计操作的时候,比如求和,或者诸如统计序列中元素的出现个数等(可尝试下如何用 reduce 做到),可以选择使用 reduce 来实现。相对可以使代码更简洁。
我觉得,写代码的可读性是很重要的事情,简洁易懂的代码,既容易让别人看懂,也便于自己以后的维护。同时,较少的代码也意味着比较高的开发效率和较少的出错可能。应尽量避免写混乱冗长的代码。当然,也不用为了一味追求代码的精简,总是想方设法把代码写在一行里。那就又走了另一个极端,同样也缺乏可读性。而至于是否使用类似 map、reduce 这样的方法,也是根据需要和个人习惯,我认为并没有一定的规则限制。
顺便说句,Python3 里,reduce已经被移出内置函数,使用 reduce 需要先通过 from functools import reduce 引入。
67.多线程
很多人使用 python 编写“爬虫”程序,抓取网上的数据。
举个例子,通过豆瓣的 API 抓取 30 部影片的信息:
import urllib, time
time_start = time.time()
data = []
for i in range(30):
print 'request movie:', i
id = 1764796 + i
url = 'https://api.douban.com/v2/movie/subject/%d' % id
d = urllib.urlopen(url).read()
data.append(d)
print i, time.time() - time_start
print 'data:', len(data)> python test.py
request movie: 0
0 0.741228103638
request movie: 1
1 1.96586918831
...
request movie: 28
28 12.0225770473
request movie: 29
29 12.4063940048
data: 30
程序里用了 time.time() 来计算抓取花费的时间。运行一遍,大约需要十几秒(根据网络情况会有差异)。
如果我们想用这套代码抓取几万部电影,就算中间不出什么状况,估计也得花上好几个小时。
然而想一下,我们抓一部电影信息的过程是独立,并不依赖于其他电影的结果。因此没必要排好队一部一部地按顺序来。那么有没有什么办法可以同时抓取好几部电影?
答案就是:多线程。
来说一种简单的多线程方法:
python 里有一个 thread 模块,其中提供了一个函数:
start_new_thread(function, args[, kwargs])
function 是开发者定义的线程函数,
args 是传递给线程函数的参数,必须是tuple类型,
kwargs 是可选参数。
调用 start_new_thread 之后,会创建一个新的线程,来执行 function 函数。而代码原本的主线程将继续往下执行,不再等待 function 的返回。通常情况,线程在 function 执行完毕后结束。
改写一下前面的代码,将抓取的部分放在一个函数中:
import urllib, time, thread
def get_content(i):
id = 1764796 + i
url = 'https://api.douban.com/v2/movie/subject/%d' % id
d = urllib.urlopen(url).read()
data.append(d)
print i, time.time() - time_start
print 'data:', len(data)
time_start = time.time()
data = []
for i in range(30):
print 'request movie:', i
thread.start_new_thread(get_content, (i,))
raw_input('press ENTER to exit...\n')> python test.py
request movie: 0
request movie: 1
...
request movie: 28
request movie: 29
press ENTER to exit...
1 0.39500784874
data: 1
9 0.428859949112
data: 2
...
data: 28
21 1.03756284714
data: 29
8 2.66121602058
data: 30
因为主线程不在等待函数返回结果,所以在代码最后,增加了raw_input,避免程序提前退出。
从输出结果可以看出:
在程序刚开始运行时,已经发送所有请求
收到的请求并不是按发送顺序,先收到就先显示
总共用时两秒多
data 里同样记录了所有30条结果
所以,对于这种耗时长,但又独立的任务,使用多线程可以大大提高运行效率。但在代码层面,可能额外需要做一些处理,保证结果正确。如上例中,如果需要电影信息按 id 排列,就要另行排序。
多线程通常会用在网络收发数据、文件读写、用户交互等待之类的操作上,以避免程序阻塞,提升用户体验或提高执行效率。
多线程的实现方法不止这一种。另外多线程也会带来一些单线程程序中不会出现的问题。这里只是简单地开个头。