python pandas操作excel表
原始excel表
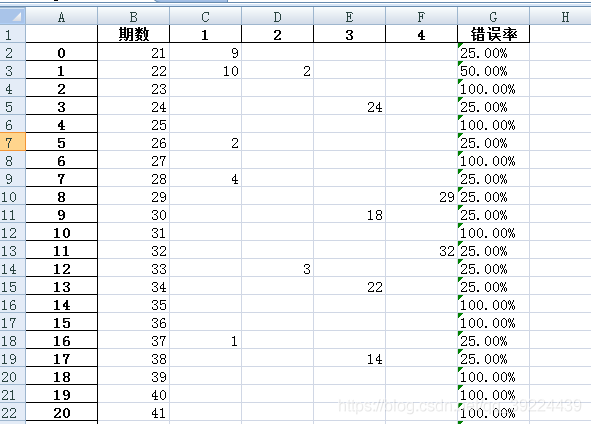
要转换成的excel表
代码
import pandas as pd
class Daletou(object):
def __init__(self):
# 读取excel表的哪几列
self.lie = 'A,B,C,D,E,F'
# renpan
self.ren_wen_pan = {
1: [1, 11, 13, 25],
2: [2, 10, 14, 26],
3: [3, 9, 15, 27],
4: [4, 8, 16, 28],
5: [5, 7, 17, 29],
6: [6, 6, 18, 30],
7: [7, 5, 19, 31],
8: [8, 4, 20, 32],
9: [9, 3, 21, 33],
10: [10, 2, 22, 34],
11: [11, 1, 23, 35],
0: [12, 12, 24, 36],
}
# pandas读取excel文件
self.data = pd.read_excel('大乐透.xlsx', sheet_name='Sheet1', usecols=self.lie)
"""
把读取到的excel转换成字典类型:
{
21: [8, 6, 5, 15, 9],
22: [33, 19, 10, 35, 2],
23: [13, 18, 29, 12, 21],
24: [32, 2, 16, 30, 24],
....
}
"""
self.data_dict = self.data.set_index('期数').T.to_dict('list')
# print(self.data_dict)
def parse(self):
"""
处理彩票正确率
:return: 返回处理好的字典类型:
{'期数':[21,22,23,24],
'人文盘1':[1,'','',''],
'人文盘2':['','',2,''],
'人文盘3':['','',2,''],
'人文盘4':['','',2,''],
'错误率':['','',2,''],
}
"""
rst_dit = {}
for i_k, i_v in self.data_dict.items():
test = []
rst_dit[i_k] = []
for j_k, j_v in self.ren_wen_pan.items():
if i_k % 12 == j_k:
for ren in self.ren_wen_pan[j_k]:
if ren in i_v:
test.append(ren)
rst_dit[i_k].append(ren)
else:
rst_dit[i_k].append(' ')
if len(test) == 0:
rst_dit[i_k].append("%.2f%%" % (1 * 100))
else:
rst_dit[i_k].append("%.2f%%" % (len(test) / 4 * 100))
# rst_dit[i_k].append(test)
pd_data = {
'期数': [],
'人文盘1': [],
'人文盘2': [],
'人文盘3': [],
'人文盘4': [],
'错误率': [],
}
for i_v, i_k in rst_dit.items():
pd_data['期数'].append(i_v)
pd_data['人文盘1'].append(i_k[0])
pd_data['人文盘2'].append(i_k[1])
pd_data['人文盘3'].append(i_k[2])
pd_data['人文盘4'].append(i_k[3])
pd_data['错误率'].append(i_k[4])
# print(pd_data)
return pd_data
def save_excel(self, data_dict):
"""
把处理好的字典写到新的excel里
:param data_dict: 处理好的字典
:return:
"""
# 打开一个新的excel
writer = pd.ExcelWriter('大乐透正确率.xlsx')
# 把字典转化为dataframe类型
df = pd.DataFrame(data_dict)
# 把转化好的dataframe写到刚才打开的writer里
df.to_excel(writer, 'Sheet1')
# 保存写好的excel
writer.save()
def run(self):
self.save_excel(self.parse())
if __name__ == '__main__':
data = Daletou()
data.run()