01-learning-Lenet, 主要讲的是 如何用python写一个Lenet,以及用来对手写体数据进行分类(Mnist)。从此教程可以知道如何用python写prototxt,知道如何单步训练网络,以及采用单步训练的方法来获取每一步训练的loss和accuracy,用来绘制曲线图。
其实并没有官方教程一说,只是在caffe/example/下有
00-classification.ipynb;
01-learning-lenet.ipynb;
02-fine-tuning.ipynb;
等等一些列 ipython notebook文件,里面就是一些example,这就是所说的官方教程,打开ipynb文件有多种方式,我是直接在github上打开的(附链接:http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/00-classification.ipynb)
这些example其实是比较全的, 包含很多辅助功能,可以分析我们的model
此教程分以下六步:
1. Setup,import各种需要的,以及把路劲添加进来(e.g. : os.chdir(caffe_root))
2. Create net.prototxt and solver.prototxt,主要是讲如何使用python来生成prototxt
3. Loading and checking the solver ,这一步是检查我们写好的prototxt没问题,input的data没问题,为后续训练做保障(平时我们往往忽略这一步,然而在大量的工程项目中,这一步是异常的重要!当你训练网络出问题时,由找不到是什么问题的情况下,就要考虑检查一下你的网络是否定义错,网络中的参数是否出错,还有你丢进去的data,真正喂到网络的时候是不是你所定义的data,以及你的data和你的label是否一一对应。。。等等)
4. Stepping the solver, 万事俱备只欠东风,这里一步就是在所有需要的东西都准备之后,还需要测试一下你的solver是否可行,否则迭代很久之后发现自己的solver压根没做solver…..
5. Writing a custom training loop,这一步才是开始一遍一遍的训练,这里用的是循环 step(1)方式,每一个step都记录loss和accuracy,最后方便绘出曲线图
6. Experiment with architecture and optimization,这一步是指出一些可改变的参数(learning rate,interations等)、方法(sgd换成Adam之类的);让大家学习对比不同参数带来的结果
Ps:lmdb文件在最下面的百度网盘里的 Result/Section2里面 ,整个代码也在云盘里,供大家参考
第一步、Setup
就是把需要用到的模块 import进来,这里会用到pylab来绘图,所以:
from pylab import *以及caffe import进来,这里提供两种方法,一种是文档里的
caffe_root = '../' # 这是你caffe的根目录,即 /home/***/caffe-master/
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe一种是我用的(参见底部代码)
第二步、Creating the net
用python来创建train_test.prototxt 和 solver.prototxt
from caffe import layers as L, params as P
ef lenet(lmdb, batch_size):
# our version of LeNet: a series of linear and simple nonlinear transformations
n = caffe.NetSpec()
n.data, n.label = L.Data(batch_size=batch_size, backend=P.Data.LMDB, source=lmdb,
transform_param=dict(scale=1./255), ntop=2)
n.conv1 = L.Convolution(n.data, kernel_size=5, num_output=20, weight_filler=dict(type='xavier'))
n.pool1 = L.Pooling(n.conv1, kernel_size=2, stride=2, pool=P.Pooling.MAX)
n.conv2 = L.Convolution(n.pool1, kernel_size=5, num_output=50, weight_filler=dict(type='xavier'))
n.pool2 = L.Pooling(n.conv2, kernel_size=2, stride=2, pool=P.Pooling.MAX)
n.fc1 = L.InnerProduct(n.pool2, num_output=500, weight_filler=dict(type='xavier'))
n.relu1 = L.ReLU(n.fc1, in_place=True)
n.score = L.InnerProduct(n.relu1, num_output=10, weight_filler=dict(type='xavier'))
n.loss = L.SoftmaxWithLoss(n.score, n.label)
return n.to_proto()
with open('mnist/lenet_auto_train.prototxt', 'w') as f:
f.write(str(lenet('mnist/mnist_train_lmdb', 64)))
with open('mnist/lenet_auto_test.prototxt', 'w') as f:
f.write(str(lenet('mnist/mnist_test_lmdb', 100)))(PS:官网没有给出solver怎么写的啊! 在后面我会给出solver.prototxt和train_test.prototxt的代码,不过和教程的不太一样,大家可以对比来看看)
按照官网的执行完以上代码,就会在 /example/mnist/下面出现 lenet_auto_train.prototxt
(就是我所说的train_test.prototxt),然后可以打开看看,是否正确
第三步、Loding and checking the solver
这一步是检查我们写好的prototxt没问题,input的data没问题,为后续训练做保障(平时我们往往忽略这一步,然而在大量的工程项目中,这一步是异常的重要!当你训练网络出问题时,由找不到是什么问题的情况下,就要考虑检查一下你的网络是否定义错,网络中的参数是否出错,还有你丢进去的data,真正喂到网络的时候是不是你所定义的data,以及你的data和你的label是否一一对应。。。等等)
caffe.set_device(0)
caffe.set_mode_gpu()
load the solver and create train and test nets
solver = None # ignore this workaround for lmdb data (can't instantiate two solvers on the same data)
solver = caffe.SGDSolver('mnist/lenet_auto_solver.prototxt') # 把solver 读进来
# each output is (batch size, feature dim, spatial dim)
print [(k, v.data.shape) for k, v in solver.net.blobs.items()] # 检测一下各个blob的shape是否符合我们所设定的
# just print the weight sizes (we'll omit the biases)
[(k, v[0].data.shape) for k, v in solver.net.params.items()] # 检查一下params的shape是否符合预期, v[0]是filters的, v[1]是bias看完网络没问题之后,来看看数据有没有问题,图片与标签对应不对应,一张图片喂到网络后,出来的结果是什么。
solver.net.forward() # train net
solver.test_nets[0].forward() # test net (there can be more than one)
imshow(solver.net.blobs['data'].data[:8, 0].transpose(1, 0, 2).reshape(28, 8*28), cmap='gray'); axis('off') # 自己要加上 plt.show()才能显示图片噢!
plt.show()
print 'train labels:', solver.net.blobs['label'].data[:8]执行这三句后可以看到我们的图片以及对应的labels
再来看看test集里面的
imshow(solver.test_nets[0].blobs['data'].data[:8, 0].transpose(1, 0, 2).reshape(28, 8*28), cmap='gray'); axis('off')
print 'test labels:', solver.test_nets[0].blobs['label'].data[:8]
plt.show()如图: 
第四步、Stepping the solver
教程给的是单步的训练,好处就是可以一步一步的去看网络中参数变化,可以记录每一步网络训练的相关参数,便于分析训练是否得当。
solver.step(1) # 这就是一步训练,一步训练是的意思就是 一个batchsize的图片喂给网络,网络得到相应的误差,然后进行更新,这样就是一步训练。既然训练了一步,filters得到相应的更新值,这个更新值就在diff里
imshow(solver.net.params['conv1'][0].diff[:, 0].reshape(4, 5, 5, 5)
.transpose(0, 2, 1, 3).reshape(4*5, 5*5), cmap='gray'); axis('off')
plt.show() filters更新的值就是下面这张图所展示的: 
第五步、Writing a custom training loop
之前都是为训练做准备的,现在要真正的让网络跑起来(训练)
由于采用单步训练(solver.step(1)),所以我们要写一个for循环来进行循环迭代训练
单步训练就可以把每一步的train_loss记录下来,用于后面的绘制loss曲线图,以便于对此次训练效果进行评估
niter = 200
test_interval = 25
# losses will also be stored in the log
train_loss = zeros(niter)
test_acc = zeros(int(np.ceil(niter / test_interval)))
output = zeros((niter, 8, 10))
# the main solver loop
for it in range(niter):
solver.step(1) # SGD by Caffe
# store the train loss
train_loss[it] = solver.net.blobs['loss'].data
# store the output on the first test batch
# (start the forward pass at conv1 to avoid loading new data)
solver.test_nets[0].forward(start='conv1')
output[it] = solver.test_nets[0].blobs['score'].data[:8]
# run a full test every so often
# (Caffe can also do this for us and write to a log, but we show here
# how to do it directly in Python, where more complicated things are easier.)
if it % test_interval == 0:
print 'Iteration', it, 'testing...'
correct = 0
for test_it in range(100):
solver.test_nets[0].forward()
correct += sum(solver.test_nets[0].blobs['score'].data.argmax(1)
== solver.test_nets[0].blobs['label'].data)
test_acc[it // test_interval] = correct / 1e4跑完200步(niter=200),来看看曲线
_, ax1 = subplots()
ax2 = ax1.twinx()
ax1.plot(arange(niter), train_loss)
ax2.plot(test_interval * arange(len(test_acc)), test_acc, 'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('train loss')
ax2.set_ylabel('test accuracy')
ax2.set_title('Test Accuracy: {:.2f}'.format(test_acc[-1]))
plt.show()如图; 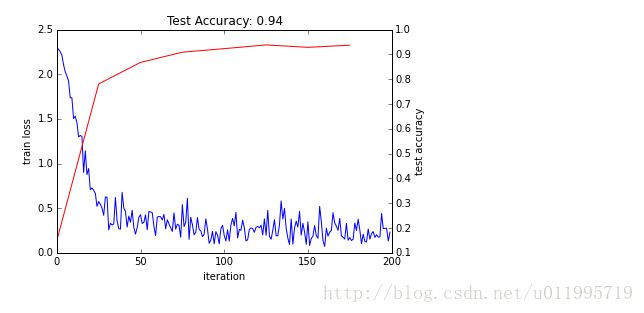
从曲线看网络还是不够生动,教程给出一个方法可以把看出 每个样本的predict的分布变化情况
例如:
for i in range(1):
figure(figsize=(2, 2))
imshow(solver.test_nets[0].blobs['data'].data[i, 0], cmap='gray')
figure(figsize=(10, 2))
imshow(output[:50, i].T, interpolation='nearest', cmap='gray')
xlabel('iteration')
ylabel('label')来看看第一个样本的predict随网络训练的变化情况
如图: 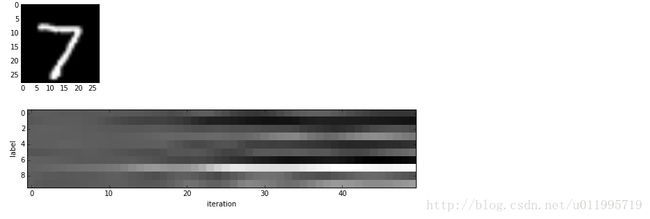
越白色的表示预测的值(这里不是概率,下面那个展示才是概率,也就是softmax-computed probability vectors),反之越小。
可以看到,一开始每个类别都是灰色的,预测都很随机,随着10个iteration之后,7这个类别逐渐变亮。这提供了一个很好的可视化方法来观察我们的网络对样本预测的变化(大赞)
由于刚刚用的是网络最原始输出(the “raw” output scores),不太容易看出区别,接下来画一个用softmax-computed probability vectors来表示的
for i in range(1):
figure(figsize=(2, 2))
imshow(solver.test_nets[0].blobs['data'].data[i, 0], cmap='gray')
figure(figsize=(10, 2))
imshow(exp(output[:50, i].T) / exp(output[:50, i].T).sum(0), interpolation='nearest', cmap='gray')
xlabel('iteration')
ylabel('label')如图: 
这样就很明显了
第六步、Experiment with architecture and optimization
炼丹(训练网络)不是那么容易,训练一个网络要设置的参数,超参很多,还要选择不同的方法来求解,这些不同参数对网络的训练有什么影响,都是需要自己去调,去试过才有体会的,所以这一步是给出了一些建议,让大家去调试不同的网络,看看最终网络的performance有什么变化,这里我就没有做了~~
我的代码是分为三个部分,1. 创建 train_test.prototxt 2. 创建 solver.prototxt 3. train
由于我的代码不是放在caffe/里面,所以路径方面请自己相应更改,最后我会吧整个工程文件夹打包放到云盘,供大家下载。
1.写train_test.prototxt
from pylab import *
import sys
sys.path.append('/home/***/caffe-recon-dec-master/python')
sys.path.append('/home/***/caffe-recon-dec-master/python/caffe')
import caffe
import os
from caffe import layers as L, params as P
# down load data if need
# import os
# os.chdir('/home/pi/caffe-recon-dec-master/')
# # Download data
# !data/mnist/get_mnist.sh
# # Prepare data
# !examples/mnist/create_mnist.sh
# # back to examples
# os.chdir('examples')
# creating Lenet.prototxt
def lenet(lmdb, batch_size):
# our version of LeNet: a series of linear and simple nonlinear transformations
n = caffe.NetSpec()
n.data, n.label = L.Data(batch_size=batch_size, backend=P.Data.LMDB, source=lmdb,
transform_param=dict(scale=1./255), ntop=2)
n.conv1 = L.Convolution(n.data, kernel_size=5, num_output=20, weight_filler=dict(type='xavier'))
n.pool1 = L.Pooling(n.conv1, kernel_size=2, stride=2, pool=P.Pooling.MAX)
n.conv2 = L.Convolution(n.pool1, kernel_size=5, num_output=50, weight_filler=dict(type='xavier'))
n.pool2 = L.Pooling(n.conv2, kernel_size=2, stride=2, pool=P.Pooling.MAX)
n.fc1 = L.InnerProduct(n.pool2, num_output=500, weight_filler=dict(type='xavier'))
n.relu1 = L.ReLU(n.fc1, in_place=True)
n.score = L.InnerProduct(n.relu1, num_output=10, weight_filler=dict(type='xavier'))
n.loss = L.SoftmaxWithLoss(n.score, n.label)
return n.to_proto()
prototxt_folder ='../../Result/Lenet/'
train_prototxt_name = 'lenet_auto_train.prototxt'
test_prototxt_name = 'lenet_auto_test.prototxt'
if not os.path.exists('../../Result/Lenet/'):
os.makedirs('../../Result/Lenet/')
with open(prototxt_folder+train_prototxt_name, 'w') as f:
f.write(str(lenet('../../Result/Section2/train_lmdb/', 64)))
with open(prototxt_folder+test_prototxt_name, 'w') as f:
f.write(str(lenet('../../Result/Section2/valid_lmdb/', 100)))2.创建 solver.prototxt
import sys
sys.path.append('/home/***/caffe-recon-dec-master/python')
sys.path.append('/home/***/caffe-recon-dec-master/python/caffe')
from caffe.proto.caffe_pb2 import SolverParameter
import argparse
import os
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--train_net', default='../../Result/Lenet/lenet_auto_train.prototxt', help='path to train net prototxt. [DEFAULT=../../Result/Section4/caffenet_train.prototxt]')
parser.add_argument('--test_net', default='../../Result/Lenet/lenet_auto_test.prototxt', help='path to validation net prototxt. [DEFAULT=../../Result/Section4/caffenet_valid.prototxt]')
parser.add_argument('--solver_target_folder', default='../../Result/Lenet/', help='solver target FOLDER. [DEFAULT=../../Result/Section5/]')
parser.add_argument('--solver_filename', default='Lenet_solver.prototxt',help='solver prototxt NAME. [DEFAULT=caffenet_solver.prototxt]')
parser.add_argument('--snapshot_target_folder', default='../../Result/Lenet/', help='snapshot target FOLDER. [DEFAULT=../../Result/Section6/')
parser.add_argument('--snapshot_prefix', default='Lenet', help='snapshot NAME prefix, [DEFAULT=caffenet]')
args = parser.parse_args()
SOLVER_FULL_PATH = args.solver_target_folder + args.solver_filename
SNAPSHOT_FULL_PATH = args.snapshot_target_folder + args.snapshot_prefix
os.system('rm -rf ' + SOLVER_FULL_PATH)
os.system('rm -rf ' + SNAPSHOT_FULL_PATH + '*')
solver = SolverParameter()
solver.train_net = args.train_net
#repeated field is a list, use append to assign values
solver.test_net.append(args.test_net)
solver.test_iter.append(100)
solver.test_interval = 500
solver.base_lr = 0.01
solver.momentum = 0.9
solver.weight_decay = 0.0005
solver.lr_policy = 'inv'
solver.gamma = 0.0001
solver.power = 0.75
# solver.stepsize = 2500
solver.display = 100
solver.max_iter = 10000
solver.snapshot = 5000
solver.snapshot_prefix = SNAPSHOT_FULL_PATH
solver.solver_mode = SolverParameter.GPU
with open(SOLVER_FULL_PATH, 'w') as f:#generating prototxt
f.write(str(solver))3. train Lenet
import sys
sys.path.append('/home/***/caffe-recon-dec-master/python')
sys.path.append('/home/***/caffe-recon-dec-master/python/caffe')
import caffe
import argparse
from pylab import *
# import matplotlib.pyplot as plt
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--solver_folder', default='../../Result/Lenet/', help='path to the solver FOLDER. [DEFAULT=../../Result/Lenet/]')
parser.add_argument('--solver_file', default='Lenet_solver.prototxt', help='path to the solver NAME. [DEFAULT=Lenet_solver.prototxt]')
args = parser.parse_args()
caffe.set_mode_gpu()
caffe.set_device(0)
SOLVER_FULL_PATH = args.solver_folder + args.solver_file
solver = None
solver = caffe.get_solver(SOLVER_FULL_PATH)
# each output is (batch size, feature dim, spatial dim)
# print 'each output is (batch size, feature dim, spatial dim)'
# for k, v in solver.net.blobs.items():
# print k + '\t' + str(v.data.shape)
# just print the weight sizes (we'll omit the biases)
# for k, v in solver.net.params.items():
# print k + '\t' + str(v[0].data.shape)
solver.net.forward() # train net
solver.test_nets[0].forward() # test net
# show the train data
# imshow(solver.net.blobs['data'].data[:8, 0].transpose(1, 0, 2).reshape(28, 8*28), cmap='gray')
# axis('off')
# show()
# print 'train labels:', solver.net.blobs['label'].data[:8]
# show test data
# imshow(solver.test_nets[0].blobs['data'].data[:8, 0].transpose(1, 0, 2).reshape(28, 8*28), cmap='gray')
# axis('off')
# show()
# print 'test labels:', solver.test_nets[0].blobs['label'].data[:8]
# show what gradients propagating through our filters
# solver.step(1)
# imshow(solver.net.params['conv1'][0].diff[:, 0].reshape(4, 5, 5, 5).transpose(0, 2, 1, 3).reshape(4*5, 5*5), cmap='gray')
# axis('off')
# show()
# solver.solve()
niter = 200
test_interval = 25
# losses will also be stored in the log
train_loss = zeros(niter)
test_acc = zeros(int(np.ceil(niter / test_interval)))
output = zeros((niter, 8, 10))
# the main solver loop
for it in range(niter):
solver.step(1) # SGD by Caffe
# store the train loss
train_loss[it] = solver.net.blobs['loss'].data
# store the output on the first test batch
# (start the forward pass at conv1 to avoid loading new data)
solver.test_nets[0].forward(start='conv1')
output[it] = solver.test_nets[0].blobs['score'].data[:8]
# run a full test every so often
# (Caffe can also do this for us and write to a log, but we show here
# how to do it directly in Python, where more complicated things are easier.)
if it % test_interval == 0:
print 'Iteration', it, 'testing...'
correct = 0
for test_it in range(100):
solver.test_nets[0].forward()
correct += sum(solver.test_nets[0].blobs['score'].data.argmax(1)
== solver.test_nets[0].blobs['label'].data)
test_acc[it // test_interval] = correct / 1e4
# plot the train loss and test accuracy
_, ax1 = subplots()
ax2 = ax1.twinx()
ax1.plot(arange(niter), train_loss)
ax2.plot(test_interval * arange(len(test_acc)), test_acc, 'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('train loss')
ax2.set_ylabel('test accuracy')
ax2.set_title('Test Accuracy: {:.2f}'.format(test_acc[-1]))
show()
# watch how our prediction scores evolved
# for i in range(5):
# figure(figsize=(2, 2))
# imshow(solver.test_nets[0].blobs['data'].data[i, 0], cmap='gray')
# figure(figsize=(10, 2))
# imshow(output[:100, i].T, interpolation='nearest', cmap='gray') # 200 is iter
# xlabel('iteration')
# ylabel('label')
# show()
# watch the "raw" output scores rather than the softmax-computed probability vectors
# for i in range(1):
# figure(figsize=(2, 2))
# imshow(solver.test_nets[0].blobs['data'].data[i, 0], cmap='gray')
# figure(figsize=(10, 2))
# imshow(exp(output[:50, i].T) / exp(output[:50, i].T).sum(0), interpolation='nearest', cmap='gray')
# xlabel('iteration')
# ylabel('label')
# show()
整个工程以及 转好的 lmdb文件都打包好在百度云盘:
链接:http://pan.baidu.com/s/1gfxNMSV 密码:eo1n