常见的python爬虫反爬及应对措施
常见反爬
- 通过User-Agent校验反爬
浏览器在发送请求的时候,会附带一部分浏览器及当前系统环境的参数给服务器,服务器会通过User-Agent的值来区分不同的浏览器。
请求时添加headers,可复制浏览器中请求头中的ua,cookie,referer等参数,ua可自建或通过fake-useragent模块创建ua池,cookie可通过reuqests.Session()获取
ua池创建:
pip install fake-useragent
from fake_useragent import UserAgent
# 实例化一个ua对象
ua = UserAgent().random
获取cookie:
import requests
url="" # 可产生cookie的url
text_url="" # 要爬取的目标url
headers={'user-agent':'ua'}
# 创建一个session对象
session=requests.Session()
# 保存cookie
session.get(url,headers=headers)
# 携带cookie发起请求
text=session.get(text_url,headers=headers).text
- 通过访问频度反爬
不少网站会对访问频度设定一个阈值,如果一个IP单位时间内访问频度超过了预设的阈值,将会对该IP做出访问限制。通常需要经过验证码验证后才能继续正常访问,严重的甚至会禁止该IP访问网站一段时间。
可使用ip代理池进行解决,使用智联HTTP等代理网站或者专门写一个爬虫(后续补充),爬取网上公开的代理ip
import requests
from lxml import etree
ip_url="" # 代理提取url
# 提取出所有代理ip
url_text=requests.get(url).text
html=etree.HTML(text)
ip_list=html.xpath("")
# 创建ip池
http_proxy=[]
for ip in ip_list:
ip_dic={'http':ip}
http_proxy.append(ip_dic)
# 携带ip代理发起请求
resopnse=requests.get(url,proxies=random.choice(http_proxy))
- 通过验证码校验反爬
有部分网站不论访问频度如何,一定要来访者输入验证码才能继续操作。例如12306网站,不管是登陆还是购票,全部需要验证验证码,与访问频度无关。
相应的解决措施:验证码识别的基本方法:截图,二值化、中值滤波去噪、分割、紧缩重排(让高矮统一)、字库特征匹配识别(python的PIL库或者其他),也可使用付费网站(超级鹰,云打码)进行识别
1 付费网站识别:
1.充值后创建id
2.下载示例代码
3.根据示例完成
2 基于tesseract的ocr识别,识别度不高,需训练提高:
pip install pytesseract
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd=r"安装路径"
image=Image.open('1.jpg')
# 识别输出字符串,中文:lang="chi_sim"
text=pytesseract.image_to_string(image)
训练代码后续补充
3 通过机器学习进行解决(还在学习中)
- 通过变换网页结构反爬
一些社交网站常常会更换网页结构,而爬虫大部分情况下都需要通过网页结构来解析需要的数据,所以这种做法也能起到反爬虫的作用。在网页结构变换后,爬虫往往无法在原本的网页位置找到原本需要的内容。
只爬取一次时,在其网站结构调整之前,将需要的数据全部爬取下来;使用脚本对网站结构进行监测,结构变化时,发出告警并及时停止爬虫。
- 通过账号权限反爬
部分网站需要登录才能继续操作,这部分网站虽然并不是为了反爬虫才要求登录操作,但确实起到了反爬虫的作用。例如微博查看评论就需要登录账号。
通过模拟登录的方法进行规避,往往也需要通过验证码检验。
- Ajax动态加载
网页的不希望被爬虫拿到的数据使用Ajax动态加载,这样就为爬虫造成了绝大的麻烦,如果一个爬虫不具备js引擎,或者具备js引擎,但是没有处理js返回的方案,或者是具备了js引擎,但是没办法让站点显示启用脚本设置。基于这些情况,ajax动态加载反制爬虫还是相当有效的。
使用selenium进行爬取(参照博文:selenium在爬虫中的基本应用)或者抓包分析数据接口(参照博文:python爬虫js逆向学习)
- 无限debugger
部分网站在前端代码中设置了禁止开启浏览器开发者工具或者进入控制台时自动进入无限debugger,导致无法进行调试。
可取消断点按钮后刷新取消,也可以找出出发debug的js函数用重新成空函数后在控制台执行取消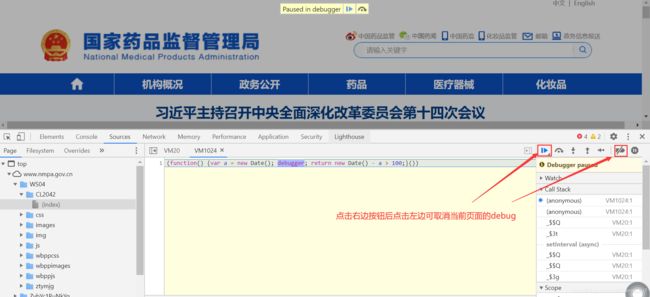
陆续更新中。。。。