CDH5.16搭建Kylin和Dashboard功能开启
CDH5.16环境下搭建Kylin2.6.6
注意事项: 从 v2.6.1 开始, Kylin 不再包含 Spark 二进制包,需要单独下载
1.软件版本介绍:
CDH5.16.2
Kylin: 2.6.6
2. CDH版本kylin2.6.6下载软件
https://archive.apache.org/dist/kylin/apache-kylin-2.6.6/apache-kylin-2.6.6-bin-cdh57.tar.gz
3. 创建目录
mkdir /opt/dev_env/kylin4.上传并解压 /opt/dev_env/kylin目录:
tar -zxvf apache-kylin-2.6.6-bin-cdh57.tar.gz -C ./5.建立软连接
[joy@hadoop002 kylin]$ ln -s apache-kylin-2.6.6-bin-cdh57/ kylin6. 添加环境变量
export KYLIN_HOME=/opt/dev_env/kylin/kylin
export PATH=$KYLIN_HOME/bin:$PATH7. 环境变量生效
source /etc/profile- 注意:
从 v2.6.1 开始, Kylin 不再包含 Spark 二进制包;
##(没有设置环境变量也可以启动) 您需要另外下载 Spark,然后设置 SPARK_HOME 系统变量到 Spark 安装目录:
- 使用脚本下载
$KYLIN_HOME/bin/download-spark.shKylin tarball 目录
- bin: shell 脚本,用于启动/停止 Kylin,备份/恢复 Kylin 元数据,以及一些检查端口、获取 Hive/HBase 依赖的方法等;
- conf: Hadoop 任务的 XML 配置文件,这些文件的作用可参考配置页面
- lib: 供外面应用使用的 jar 文件,例如 Hadoop 任务 jar, JDBC 驱动, HBase coprocessor 等.
- meta_backups: 执行 bin/metastore.sh backup 后的默认的备份目录;
- sample_cube 用于创建样例 Cube 和表的文件。
- spark: 自带的 spark。
- tomcat: 自带的 tomcat,用于启动 Kylin 服务。
- tool: 用于执行一些命令行的jar文件。
8. 修改kylin.properties配置文件
进入kylin/conf配置文件下
cp kylin.properties kylin.properties.bakvim kylin.properties
# 修改:
kylin.server.cluster-servers=hadoop002:7070
# 添加配置:
kylin.job.jar=/opt/dev_env/kylin/kylin/lib/kylin-job-2.6.6.jar
kylin.coprocessor.local.jar=/opt/dev_env/kylin/kylin/lib/kylin-coprocessor-2.6.6.jar
kylin.job.yarn.app.rest.check.status.url=http://hadoop002:8088/ws/v1/cluster/apps/${job_id}?anonymous=trueCube构建出错:
java.lang.ClassNotFoundException: org.apache.hadoop.hive.serde2.typeinfo.TypeInfo
解决方案:
在kylin.properties中添加
#kylin.job.mr.lib.dir=/opt/cloudera/parcels/CDH/lib/sentry/lib 9.检查
[joy@hadoop002 bin]# cd /opt/dev_env/kylin/kylin/bin
[joy@hadoop002 bin]$ ./check-env.sh
Retrieving hadoop conf dir...
KYLIN_HOME is set to /opt/dev_env/kylin/kylin
[joy@hadoop002 bin]$ hdfs dfs -ls /
drwxr-xr-x - joy supergroup 0 2020-06-09 14:47 /kylin
[joy@hadoop002 bin]$ ./find-hbase-dependency.sh
Retrieving hbase dependency...
[joy@hadoop002 bin]$ ./find-hive-dependency.sh
Retrieving hive dependency...10.启动kylin
[joy@hadoop002 kylin]$ bin/kylin.sh start
Retrieving hadoop conf dir...
KYLIN_HOME is set to /opt/dev_env/kylin/kylin
Retrieving hive dependency...
Retrieving hbase dependency...
Retrieving hadoop conf dir...
Retrieving kafka dependency...
Retrieving Spark dependency...
11.查看kylinUI日志
tail 200 -f logs/kylin.out12.登陆kylin
http://hadoop002:7070/kylin/loginUser: ADMIN
Pass: KYLIN


到这里, 在cdh中搭建Kylin完成
Kylin配置Spark并构建Cube, 配置过程往下看↓↓↓
Kylin测试
1.导入官方测试数据进行测试
cd $KYLIN_HOME/bin
./sample.sh日志倒数两行
Sample cube is created successfully in project 'learn_kylin'.
Restart Kylin Server or click Web UI => System Tab => Reload Metadata to take effect#这句话的意思是 例子cube已成成功创建在了 工程名称叫'learn_kylin'里面了
#重启kylin或者通过webUI => System选项卡=> 重新导入元数据信息
查看Hive default库中的表,多了五张表
hive (default)> show tables;
OK
tab_name
kylin_account
kylin_cal_dt
kylin_category_groupings
kylin_country
kylin_sales
Time taken: 0.024 seconds, Fetched: 5 row(s)2. 加载样例数据
在System中点击Reload Metadata重新加载元数据或者重启kylin,如下图:

导入成功之后,点击Model出现下图:

3. Cube 构建
点击Cube的Actions现象---->再点击Build开始构建


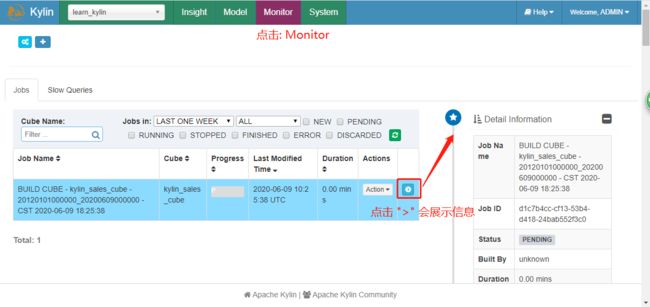
查看正在构建的cube任务,点击monitor:
[joy@hadoop002 spark]$ hbase shell
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
20/06/09 18:32:29 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.0-cdh5.16.2, rUnknown, Mon Jun 3 03:50:03 PDT 2019
hbase(main):001:0> list
TABLE
KYLIN_FORDTHXTYU
kylin_metadata kylin构建自动转化成mapreduce任务进行了:
4. 查询构建好的Cube
select sum(KYLIN_SALES.PRICE) as price_sum
,KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME
,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME
from KYLIN_SALES
inner join KYLIN_CATEGORY_GROUPINGS
on KYLIN_SALES.LEAF_CATEG_ID = KYLIN_CATEGORY_GROUPINGS.LEAF_CATEG_ID and KYLIN_SALES.LSTG_SITE_ID = KYLIN_CATEGORY_GROUPINGS.SITE_ID
group by KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME, KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME
order by KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME asc, KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME desc

Kylin配置Spark并构建Cube
CDH版本: 5.16.2
Kylin版本: 2.6.6
Kylin 的计算引擎除了 MapReduce ,还有速度更快的 Spark ,本文就以 Kylin 自带的示例 kylin_sales_cube 来测试一下 Spark 构建 Cube 的速度。
1.配置Kylin的相关Spark参数
在运行 Spark cubing 前,建议查看一下这些配置并根据集群的情况进行自定义。下面是建议配置,开启了 Spark 动态资源分配:
cd $KYLIN_HOME/conf
vim kylin.properties
## Spark conf (default is in spark/conf/spark-defaults.conf)
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
kylin.engine.spark-conf.spark.yarn.queue=default
kylin.engine.spark-conf.spark.driver.memory=2G
kylin.engine.spark-conf.spark.executor.memory=4G
kylin.engine.spark-conf.spark.executor.instances=40
kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
kylin.engine.spark-conf.spark.eventLog.enabled=true
kylin.engine.spark-conf.spark.eventLog.dir=hdfs\:///kylin/spark-history
kylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs\:///kylin/spark-history
#kylin.engine.spark-conf.spark.hadoop.yarn.timeline-service.enabled=false
#
#### Spark conf for specific job
#kylin.engine.spark-conf-mergedict.spark.executor.memory=6G
#kylin.engine.spark-conf-mergedict.spark.memory.fraction=0.2
#
## manually upload spark-assembly jar to HDFS and then set this property will avoid repeatedly uploading jar at runtime
kylin.engine.spark-conf.spark.yarn.archive=hdfs://hadoop001:8020/kylin/spark/spark-libs.jar
kylin.engine.spark-conf.spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec
#
## uncomment for HDP 如果是HDP版本,请取消下述三行配置的注释
##kylin.engine.spark-conf.spark.driver.extraJavaOptions=-Dhdp.version=current
##kylin.engine.spark-conf.spark.yarn.am.extraJavaOptions=-Dhdp.version=current
##kylin.engine.spark-conf.spark.executor.extraJavaOptions=-Dhdp.version=current其中 kylin.engine.spark-conf.spark.yarn.archive 配置是指定了 Kylin 引擎要运行的 jar 包,该 jar 包需要自己生成且上传到 HDFS 。由于我执行 Kylin 服务的用户是 kylin,所以要先切换到 kylin 用户下去执行。命令如下:
cd $KYLIN_HOME
# 生成spark-libs.jar文件
jar cv0f spark-libs.jar -C $KYLIN_HOME/spark/jars/ ./
# 上传到HDFS上的指定目录
hdfs dfs -mkdir -p /kylin/spark/
hdfs dfs -put spark-libs.jar /kylin/spark/重启kylin(这里一定要重启,不然在Cube时会报错)
$KYLIN_HOME/bin/kylin.sh stop && $KYLIN_HOME/bin/kylin.sh start2.修改Cube的配置
配置好 Kylin 的相关 Spark 参数后,接下来我们需要将 Cube 的计算引擎修改为 Spark ,修改步骤如下:
先指定 Kylin 自带的生成 Cube 脚本:sh ${KYLIN_HOME}/bin/sample.sh ,会在 Kylin Web 页面上加载出两个 Cube 。
接着访问我们的 Kylin Web UI ,然后点击 Model -> Action -> Edit 按钮:

点击第五步:Advanced Setting,往下划动页面,更改 Cube Engine 类型,将 MapReduce 更改为 Spark。然后保存配置修改。如下图所示:


点击 “Next” 进入 “Configuration Overwrites” 页面,点击 “+Property” 添加属性 “kylin.engine.spark.rdd-partition-cut-mb” 其值为 “500” (理由如下):

样例 cube 有两个耗尽内存的度量: “COUNT DISTINCT” 和 “TOPN(100)”;当源数据较小时,他们的大小估计的不太准确: 预估的大小会比真实的大很多,导致了更多的 RDD partitions 被切分,使得 build 的速度降低。500 对于其是一个较为合理的数字。点击 “Next” 和 “Save” 保存 cube。
对于没有”COUNT DISTINCT” 和 “TOPN” 的 cube,请保留默认配置。
3.构建Cube
保存好修改后的 cube 配置后,点击 Action -> Build,选择构建的起始时间(一定要确保起始时间内有数据,否则构建 cube 无意义),然后开始构建 cube 。
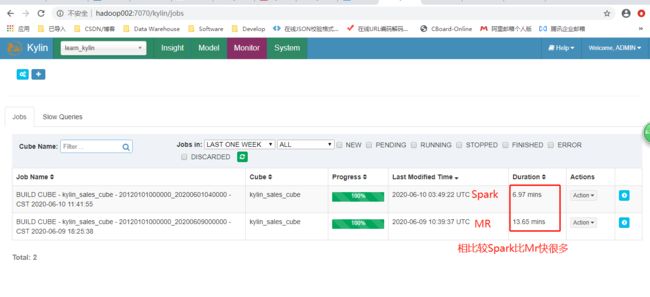
在构建 cube 的过程中,可以打开 Yarn ResourceManager UI 来查看任务状态。当 cube 构建到 第七步 时,可以打开 Spark 的 UI 网页,它会显示每一个 stage 的进度以及详细的信息。
Kylin 是使用的自己内部的 Spark ,所以我们还需要额外地启动 Spark History Server。
${KYLIN_HOME}/spark/sbin/start-history-server.sh hdfs://:8020/kylin/spark-history 启动 Spark History Server 命令
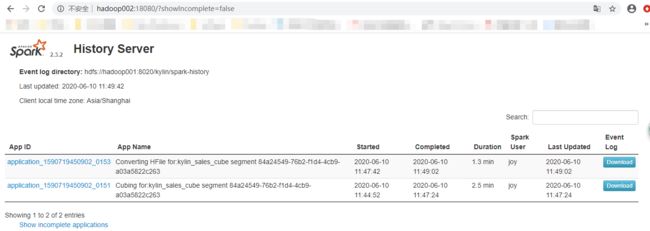
${KYLIN_HOME}/spark/sbin/start-history-server.sh hdfs://hadoop001:8020/kylin/spark-history访问:http://ip:18080/ ,可以看到 Spark 构建 Cube 的 job 详细信息,该信息对疑难解答和性能调整有极大的帮助。
http://hadoop002:18080/
到这里, Kylin使用Spark构建Cube完成, 如有遇到其他问题参考博客, 链接: https://www.cnblogs.com/createboke/p/11581915.html
该博客中有记录实施过程中遇到的一些问题,可搜索关键字: FAQ 快速找到
Kylin Dashboard 功能开启
1.Kylin 为使得在 WebUI 上的 Dashboard 有效,您需要设置
修改kylin.properties,并添加如下内容
kylin.cube.cubeplanner.enabled=true
kylin.server.query-metrics2-enabled=true
kylin.metrics.reporter-query-enabled=true
kylin.metrics.reporter-job-enabled=true
kylin.metrics.monitor-enabled=true
kylin.web.dashboard-enabled=true
# 建立系统Cube用于监控
# 特别说明:默认生成的hive元数据表 会新建名为kylin的库存储来存储。如果需要指定,使用
# kylin.metrics.prefix=dbname重启kylin
$KYLIN_HOME/bin/kylin.sh stop && $KYLIN_HOME/bin/kylin.sh start脚本自动配置方式(对高版本采用了自动配置形式)
执行脚本./system-cube.sh setup
$KYLIN_HOME/bin/system-cube.sh setup这一步会建立对应的hive表,将对应的cube导入到matestore里面,重启kylin或者在web页面刷新kylin的元数据即在project可看到KYLIN_SYSTEM。
继续执行脚本./system-cube.sh build
$KYLIN_HOME/bin/system-cube.sh build执行build命令即可构建五个system_cube,构建完成后即可在web页面中发现dashboard界面
最后设置定时构建任务:./system-cube.sh cron即可(运行一次就行)
$KYLIN_HOME/bin/system-cube.sh cron