神经网络
①梯度
梯度法:在学习时找到最优参数,使用梯度寻找函数最小值方法:函数取值从
梯度:表示各点处函数减少最多的方向,不一定指向最小值,但沿着方向可以最大限度减少函数的值。所以在寻找函数最小值的时候,以梯度信息为线索决定前进方向。
学习率:在神经网络学习中,决定在一次学习中应该学习多少,以及在多大程度上更新参数
使用python实现梯度下降法
def gradient_descent(f,init_x,lr=0.01,step_num=100):
x=init_x
for i in range(setp_num):
grad=numrical_gradient(f(x),x)
x -= lr*grad
return x
f是要进行优化的函数,init_x是初始值,lr是学习率learning rate,step_num是梯度法的重复次数
numerical_gradient(f,x)求函数的梯度,使用该计算的梯度乘以学习率得到的值更新操作,由step_num指定重复的次数。该函数还可以求函数最小值
学习率过大,会发散成一个比较大的值;学习率过小,基本上没怎么更新就结束。设置合适的学习率非常重要。
※神经网络的梯度
example:
对于一个2*3权重W的神经网络,损失用L表示
以一个简单的神经网络为例,实现求梯度代码
实现一个名为simpleNet的类
numerical_gradient(f,x)参数是f函数,x为传给f的参数
这里参数x取net.W,定义一个计算损失函数的新函数f,把新定义的函数传给numerical_gradient(f,x)
②学习算法的实现
神经网络的步骤
1、mini-batch
从训练数据中随机选取一部分数据,称之为mini-batch。目标是减少mini-batch的损失函数值。
2、计算梯度
为了减少mini-batch损失函数的值,需要求出各个权重参数的梯度,梯度表示损失函数的值减少最多的方向。
3、更新参数,将权重参数沿着梯度方向进行微小更新。
4、loop step 123
实例
1、实现手写数字识别的神经网络
以2层神经网络为对象,使用mnist数据集进行学习。
权重使用符合高斯分布的随机数进行初始化,偏置使用0进行初始化
2、mini-batch实现
从训练数据中随机选择一部分数据,使用梯度法更新参数
以minst数据集进行学习,TwoLayerNet类作为对象
设定mini-batch大小为100,每次需要从60000个训练数据中随机取出100个数据,然后对这包含100笔数据的mini-batch求梯度,使用随机梯度下降法更新参数。梯度法的更新速度每更新一次,都对训练数据计算损失函数的值,把值添加到数组中。
可以发现,随着学习的进行,损失函数值不断减少。是正常的学习进行信号,表示神经网络的权重参数正在逐渐拟合数据。
3、基于测试数据评价
必须确认是否能苟正确识别训练数据意外的其他数据,确认是否会发生过拟合。
过拟合:训练数据中的数字图像能正确辨别,但是不在训练数据中的数字图像却无法被识别。
每经过一个epoch都会记录下训练数据和测试数据的识别精度。
epoch:指学习中所有训练数据均被使用过一次的更新次数
比如对于10000笔训练数据,用大小为100笔数据的mini-batch进行学习,重复随机梯度下降法100次,所有训练数据都过了一遍,100次为一个epoch。
代码实现:
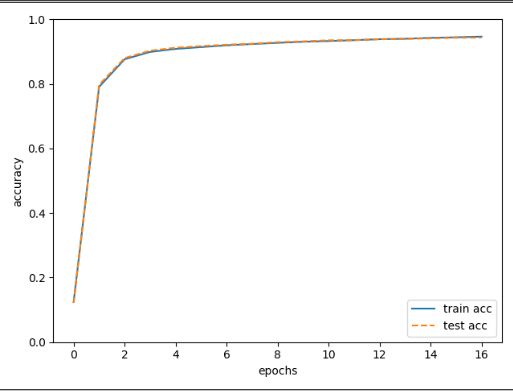
# coding: utf-8 import sys, os sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定 import numpy as np import matplotlib.pyplot as plt from dataset.mnist import load_mnist from two_layer_net import TwoLayerNet # 读入数据 (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True) #载入数据 network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10) #设定神经网络 #超参数设定 iters_num = 10000 # 适当设定循环的次数 train_size = x_train.shape[0] batch_size = 100 learning_rate = 0.1 train_loss_list = [] train_acc_list = [] test_acc_list = [] #平均每个epoch重复的次数 iter_per_epoch = max(train_size / batch_size, 1) for i in range(iters_num): #获取mini-batch batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # 计算梯度 #grad = network.numerical_gradient(x_batch, t_batch) grad = network.gradient(x_batch, t_batch) # 更新参数 for key in ('W1', 'b1', 'W2', 'b2'): network.params[key] -= learning_rate * grad[key] # 记录学过程 loss = network.loss(x_batch, t_batch) train_loss_list.append(loss) #计算每个epoch的识别精度 if i % iter_per_epoch == 0: train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc)) # 绘制图形 markers = {'train': 'o', 'test': 's'} x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list, label='train acc') plt.plot(x, test_acc_list, label='test acc', linestyle='--') plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show()
在例子中,每经过一个epoch就对所有的训练数据和测试数据识别精度,并记录结果。
从图里可以看出,随着epoch前进,使用训练数据和测试数据评价的识别精度都提高了。