【Kaggle纽约出租车车程用时预测实战(2)】Kmeans Clustering + Matplotlib数据可视化
1、加载经纬度信息
1.1 提取经纬度字段数据
前面已经加载了相关的经纬度信息了,这里直接提取里面的字段,并进行处理即可
longitude = list(train.pickup_longitude) + list(train.dropoff_longitude)
latitude = list(train.pickup_latitude) + list(train.dropoff_latitude)
print(len(train.pickup_longitude), len(train.dropoff_longitude), len(longitude) )
print(len(train.pickup_latitude), len(train.dropoff_latitude), len(latitude) )
–> 输出的结果为:(注意两个列表的相加是进行拓展,不是对应位置上的数据相加)
1458644 1458644 2917288
1458644 1458644 2917288
1.2 创建DataFrame保存经纬度数据
loc_df = pd.DataFrame()
loc_df['longitude'] = longitude
loc_df['latitude'] = latitude
#loc_df = loc_df.assign(longitude =longitude)
#loc_df = loc_df.assign(latitude =latitude)
print(loc_df.head())
–> 输出的结果为:(这里使用了最常见到的方法创建新的字段数据,也可以使用注释掉的代码)
longitude latitude
0 -73.982155 40.767937
1 -73.980415 40.738564
2 -73.979027 40.763939
3 -74.010040 40.719971
4 -73.973053 40.793209
2、纽约地图数据可视化
2.1 将经纬度限制在纽约市内
这里是为了做可视化展现,如果真正的做预测的时候是不可以排除纽约市外的数据的(比如有些人打车就是从纽约去别的城市),如果排除了这里数据,就会倒是模型的预测效果变差
xlim = [-74.03, -73.77]
ylim = [40.63, 40.85]
print(loc_df.shape)
loc_df = loc_df[(loc_df.longitude> xlim[0]) & (loc_df.longitude < xlim[1])]
loc_df = loc_df[(loc_df.latitude> ylim[0]) & (loc_df.latitude < ylim[1])]
print(loc_df.shape)
–> 输出的结果为:(可以发现排除了21540条数据,占比为0.7%)
(2917288, 2)
(2895748, 2)
2.2 Kmeans聚类
这里选择聚类的数量为15,然后将生成的数据,添加到原数据的‘label’字段
kmeans = KMeans(n_clusters=15, random_state=2, n_init = 10).fit(loc_df)
loc_df['label'] = kmeans.labels_
print(loc_df.head())
–> 输出的结果为:(数据量有点大,所以在聚类处理的过程需要花费点时间)
longitude latitude label
0 -73.982155 40.767937 12
1 -73.980415 40.738564 7
2 -73.979027 40.763939 12
3 -74.010040 40.719971 5
4 -73.973053 40.793209 9
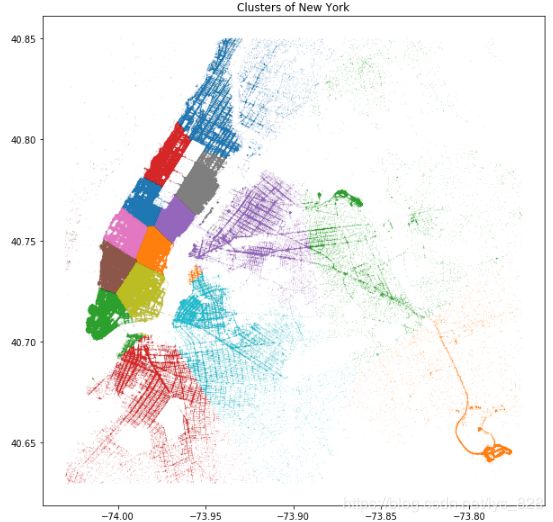
2.3 绘制可视化图形
plt.figure(figsize = (10,10))
for label in loc_df.label.unique():
plt.plot(loc_df.longitude[loc_df.label == label],loc_df.latitude[loc_df.label == label],'.', alpha = 0.3, markersize = 0.3)
plt.title('Clusters of New York')
plt.show()
–> 输出的结果为:(左侧密集的就为纽约的繁华路段,其中绿色有个车辆密集的地方是拉瓜迪亚机场、橙色密集的地方是肯尼迪国际机场(JFK),如果数据量较小的情况下,可以通过调整markersize来进行显示)