http://blog.csdn.net/pipisorry/article/details/45190851
Crawler Framework爬虫框架scrapy简介
Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy = Scrach+Python。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试、信息处理和历史档案等大量应用范围内抽取结构化数据的应用程序框架,广泛用于工业。Scrapy 使用Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。Scrapy是由Twisted写的一个受欢迎的Python事件驱动网络框架,它使用的是非堵塞的异步处理。[使用Twisted进行异步编程][您好,异步编程]
整体架构如下图
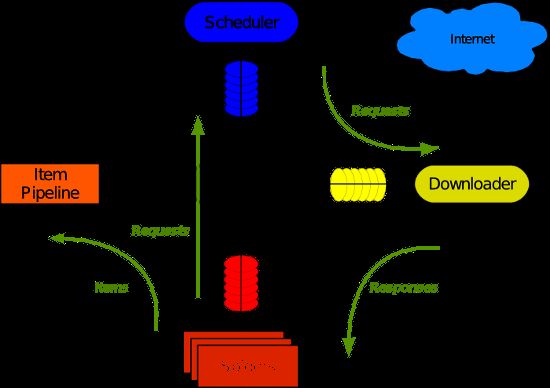
Note: 最简单的单个网页爬取流程是spiders > scheduler > downloader > spiders > item pipeline
Scrapy主要包括了以下组件:
- 引擎,用来处理整个系统的数据流处理,触发事务。
- 调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
- 项目管道,负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
组件详解:
1、Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。更多的详细内容可以看下面的数据处理流程。
2、Scheduler(调度)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。
3、Downloader(下载器)
下载器的主要职责是抓取网页并将网页内容返还给蜘蛛( Spiders)。
4、Spiders(蜘蛛)
蜘蛛是有Scrapy用户自己定义用来解析网页并抓取制定URL返回内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
蜘蛛的整个抓取流程(周期)是这样的:
首先获取第一个URL的初始请求,当请求返回后调取一个回调函数。第一个请求是通过调用start_requests()方法。该方法默认从start_urls中的Url中生成请求,并执行解析来调用回调函数。
在回调函数中,你可以解析网页响应并返回项目对象和请求对象或两者的迭代。这些请求也将包含一个回调,然后被Scrapy下载,然后有指定的回调处理。
在回调函数中,你解析网站的内容,同程使用的是Xpath选择器(但是你也可以使用BeautifuSoup, lxml或其他任何你喜欢的程序),并生成解析的数据项。
最后,从蜘蛛返回的项目通常会进驻到项目管道。
5、Item Pipeline(项目管道)
项目管道的主要责任是负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有:
清洗HTML数据
验证解析到的数据(检查项目是否包含必要的字段)
检查是否是重复数据(如果重复就删除)
将解析到的数据存储到数据库中
6、Downloader middlewares(下载器中间件)
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展Scrapy的功能。下载中间器是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
7、Spider middlewares(蜘蛛中间件)
蜘蛛中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功能。蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
8、Scheduler middlewares(调度中间件)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
scrapy爬虫机制/工作流
1. 绿线是数据流向,首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
2. 发起请求->下载中间件处理请求->下载数据得到response->中间件对response做处理->parse函数解析response,提取你要的信息->生成item(或request)->pipeline处理item。
一般要定制的主要是parse和pipeline,其他的scrapy都帮我们搞定了,所以只用专注于解析数据、生成新请求和存储了。现在scrapy的流程已经清楚了,scrapy还提供了一些额外的服务,比如日志模块,feed exports来帮助转换数据格式等,不过都是锦上添花了。
3. 数据处理流程详解
Scrapy的整个数据处理流程有Scrapy引擎进行控制,其主要的运行方式为:
引擎打开一个域名,时蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
引擎从调度那获取接下来进行爬取的页面。
调度将下一个爬取的URL返回给引擎,引擎将他们通过下载中间件发送到下载器。
当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
引擎将抓取到的项目项目管道,并向调度发送请求。
系统重复第二部后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系。
scrapy的重点 - 自定义部分
items模块:items用来定义你需要提取的数据的格式,方便进行一层一层的分析操作,你可以直接把它在使用上类比成python的字典,在概念上类比为mongodb的schema。
spider:就是我们的爬虫主体了,这里最重要的功能是对下载下来的数据做解析,生成符合规范的item或发起新的请求。我们首先实现的parse函数是解析spider的start_url请求的,对start_url默认的下载操作是直接拉下整个html,所以动态网页就不行了。那对于网页里嵌入了js的下面再讲。对于我们手动发起的请求而非初始请求,我们是可以自己指定解析函数的,而非使用默认。同时我们也是可以通过继承scrapy的请求类构造自己的请求以附带一些信息的。这样就实现了请求和对返回结果解析的松耦合。
pipeline:pipeline是对得到的item做进一步处理的,并非你所得到的所有item都是合乎要求的,也有可能还要做一些计算工作才得到你想要的。scrapy这里的强大在于做处理的时候是传入spider对象做参数的,这样你可以把一个pipeline和多个spider拼接,不需要为一个spider另写一个pipeline,同时pipeline是可以有多个在一起的,只要你在processitem函数里返回这个item,它就会被下面的pipeline继续处理。
[Python抓取框架:Scrapy的架构]
scrapy的python3支持
不过很抱歉的一点是scrapy并不支持python3,目前正在移植中,相信在2016年前应该差不多可以用了吧。[Python 3 Porting]
scrapy的功能
HTML, XML源数据 选择及提取 的内置支持
提供了一系列在spider之间共享的可复用的过滤器(即 Item Loaders),对智能处理爬取数据提供了内置支持。
通过 feed导出 提供了多格式(JSON、CSV、XML),多存储后端(FTP、S3、本地文件系统)的内置支持
提供了media pipeline,可以 自动下载 爬取到的数据中的图片(或者其他资源)。
高扩展性。您可以通过使用 signals ,设计好的API(中间件, extensions, pipelines)来定制实现您的功能。
内置的中间件及扩展为下列功能提供了支持:
cookies and session 处理
HTTP 压缩
HTTP 认证
HTTP 缓存
user-agent模拟
robots.txt
爬取深度限制
针对非英语语系中不标准或者错误的编码声明, 提供了自动检测以及健壮的编码支持。
支持根据模板生成爬虫。在加速爬虫创建的同时,保持在大型项目中的代码更为一致。详细内容请参阅 genspider 命令。
针对多爬虫下性能评估、失败检测,提供了可扩展的 状态收集工具 。
提供 交互式shell终端 , 为您测试XPath表达式,编写和调试爬虫提供了极大的方便
提供 System service, 简化在生产环境的部署及运行
内置 Web service, 使您可以监视及控制您的机器
内置 Telnet终端 ,通过在Scrapy进程中钩入Python终端,使您可以查看并且调试爬虫
Logging 为您在爬取过程中捕捉错误提供了方便
支持 Sitemaps 爬取
具有缓存的DNS解析器[http://doc.scrapy.org/en/latest/]
皮皮Blog
scrapy的安装和环境配置
我们将需要 Scrapy以及 BeautifulSoup用于屏幕抓取,SQLAlchemy用于存储数据。
创建虚拟环境(按需)
virtualenv --no-site-packages --python=2.7 ScrapyEnv
[python虚拟环境配置]
安装scrapy
unix
直接通过 pip 命令安装
pip install Scrapy
Windows
1. 下载包的编译版本完成简易安装
需要手工安装 scrapy 的一些依赖:pywin32、pyOpenSSL、Twisted、lxml 和 zope.interface。
2. 使用pip安装
首先也要安装pywin32的py2.7版本http://sourceforge.net/projects/pywin32/files/,再安装scrapy就ok了pip install Scrapy,它会自动安装依赖的包pyOpenSSL、Twisted、lxml 、six等等。
如果使用的是virtualenv要这样安装pywin32:
c:\> copy D:\python27\Lib\site-packages\pywin32.pth E:\mine\python_workspace\ScrapyEnv\Lib\site-packages\pywin32.pth
将其内容改为:
D:\python27\Lib\site-packages\win32
D:\python27\Lib\site-packages\win32\lib
D:\python27\Lib\site-packages\Pythonwin
[linux和windows下安装python拓展包]
验证安装是否成功
通过在python命令行下输入import scrapy验证你的安装,如果没有返回内容,那么你的安装已就绪。
[Installing Scrapy]
安装爬虫相关拓展包(按需)
安装网络请求包requests
pip install requests
[requests网络请求简洁之道]
安装rsa加密拓展包
pip install rsa
加入到git管理中(按需)
git init
git add .
git commit -m 'first commit'
github上添加repository
git remote add scrapyEnv [email protected]:***.git
git push -u scrapyEnv master #首次运行以后用git push scrapyEnv master
皮皮Blog
Scrapy 爬虫项目实践
了解一些 Scrapy 的基本概念和使用方法,并学习 Scrapy 项目的例子 dirbot 。该项目爬取网站目录python语言下books和Resourses目录。
Dirbot 项目位于 https://github.com/scrapy/dirbot,该项目包含一个 README 文件,它详细描述了项目的内容。如果你熟悉 git,你可以 checkout 它的源代码。或者你可以通过点击 Downloads 下载 tarball 或 zip 格式的文件。
下面以该例子来描述如何使用 Scrapy 创建一个爬虫项目。大概流程如下:
1. 创建一个新的爬虫项目
2. 定义你要爬取的items
3. 写一个spider来爬取网站并抽取items
4. 写一个item pipeline来存储抽取的数据
新建工程
在抓取之前,你需要新建一个 Scrapy 工程。进入一个你想用来保存代码的目录,然后执行:
$scrapy startproject tutorial
这个命令会在当前目录下创建一个新目录 tutorial
目录 tutorial下的结构:
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
...
这些文件主要是:
- scrapy.cfg: 项目配置文件
- tutorial/: 项目python模块, 呆会代码将从这里导入
- tutorial/items.py: 项目items文件
- tutorial/pipelines.py: 项目管道文件
- tutorial/settings.py: 项目配置文件
- tutorial/spiders: 放置spider的目录
Note:
1. 该命令会创建一个tutorial目录,里面有个scrapy-ctl.py 是整个项目的控制脚本,而代码全都放在子目录tutorial里面。
2. 如果你想在pycharm中使用,还要配置一下pycharm中该项目的解释器为py2.7(使用虚拟环境的当前是指定到虚拟环境中的py2.7),这样import scrapy才会成功。
皮皮Blog
定义Item
Items是将要装载抓取的数据的容器,它工作方式像 python 里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误。在items.py 文件里,scrapy 需要我们定义一个容器用于放置爬虫抓取的数据。items.py 与 Django 中的models.py 类似。它通过创建一个scrapy.Item 类来声明,定义它的属性为scrpy.Field 对象,就像是一个对象关系映射(ORM, Object Relational Mapping).
我们通过将需要的item模型化,来控制从dmoz.org 获得的站点数据,比如我们要获得站点的名字,url 和网站描述,我们定义这三种属性的域。
class CrawlertestItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
def __str__(self):
return 'BlogCrawlItem(url: %s)' % self.link
皮皮Blog
编写爬虫(Spider)
Spider 是用户编写的类,用于从一个域(或域组)中抓取信息。定义用于下载的URL的初步列表,如何跟踪链接,以及如何来解析这些网页的内容用于提取items。
要建立一个 Spider,你可以为 scrapy.Spider 创建一个子类,并确定三个主要的、强制的属性:
- name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字.
- start_urls:爬虫开始爬的一个 URL 列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些 URLS 开始。其他子 URL 将会从这些起始 URL 中继承性生成。
- parse():爬虫的方法,调用时候传入从每一个 URL 传回的 Response 对象作为参数,response 将会是 parse 方法的唯一的一个参数,这个方法负责解析返回的数据、匹配抓取的数据(解析为 item )并跟踪更多的 URL。
1. 可以在项目根目录下使用命令scrapy genspider -t crawl weibo weibo.com生成模块化spider代码
2. 也可以在 tutorial/spiders 目录下创建 DmozSpider.py
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
Note:
1.DmozSpider继承自 Spider (通常直接继承自功能更丰富的scrapy.contrib.spiders.CrawlSpider 要方便一些,不过为了展示数据是如何 parse 的,这里还是使用Spider 了)。继承自CrawlSpider类的WeiboSpider的name,allowed_domains属性是必须的,但是start_urls属性是可以不要的,改由其他方法生成。
2. 变量是自解释的 :name 定义了爬虫的名字。
allowed_domains 列出了供爬虫爬行的允许域名(allowed domain)的base-URL,scrapy有一个offsite机制,即是否抓其他域名,需要将allowed_domains属性添加上。
start_urls 列出了爬虫从这里开始爬行的 URL。后续的 URL 将从爬虫从start_urls 下载的数据的URL开始。
3. parse 方法是我们需要定义的回调函数,默认的 request 得到 response 之后会调用这个回调函数,我们需要在这里对页面进行解析,返回两种结果(需要进一步 crawl 的链接和需要保存的数据),但它的接口定义里这两种结果竟然是混杂在一个 list 里返回的。总之这里我们先写一个空函数,只返回一个空列表。另外,定义一个“全局”变量SPIDER ,它会在 Scrapy 导入这个 module 的时候实例化,并自动被 Scrapy 的引擎找到。
parse() 方法使用了response 参数,它是抓取器在像 Hacker News 发起一次请求之后所要返回的东西。 我们会用我们的 XPaths 转换那个响应。
4.接着,scrapy 使用 XPath 选择器从网站获取数据--通过一个给定的 XPath 从 HTML 数据的特定部分进行选择。正如它们的文档所说,"XPath 是一种用于从XML选择节点的语言,它也可以被用于HTML"。
在抓取你自己的站点并尝试计算 XPath 时, Chrome 的开发工具提供了检查html元素的能力, 可以让你拷贝出任何你想要的元素的xpath. 它也提供了检测xpath 的能力,只需要在 Javascript 控制台中使用$x, 例如$x("//img")。 而在这个教程就不多深究这个了,Firefox 有一个插件, FirePath 同样也可以编辑,检查和生成XPath。
运行项目(project’s top level目录)
$scrapy crawl dmoz
该命令从 dmoz.org 域启动爬虫,第三个参数为 DmozSpider.py 中的 name 属性值。
这样之后,你就可以在当前目录下看到爬取下来的两个文件:Books.html and Resources.html
Note: 当然,lz已将它写入到一个启动函数里。在项目根目录下创建文件ExcuteScrapyCrawler:
import subprocess
subprocess.call(r'..\Scripts\activate', shell=True)
subprocess.call('scrapy crawl dmoz')
What just happened under the hood?
Scrapy creates scrapy.Request objects for each URL in the start_urls attribute of the Spider, and assigns them the parse method of the spider as their callback function.
These Requests are scheduled, then executed, and scrapy.http.Response objects are returned and then fed back to the spider, through the parse() method.
皮皮Blog
提取items
spider之xpath选择器
Scrapy 使用一种叫做 XPath 或者 CSS 选择器的机制。[selectors]
Note: CSS vs XPath: you can go a long way extracting data from web pages using only CSS selectors. However, XPath offers more power because besides navigating the structure, it can also look at the content: you’re able to select things like: the link that contains the text ‘Next Page’. Because of this, we encourage you to learn about XPath even if you already know how to construct CSS selectors.
XPath表达式的简单例子:
/html/head/title: 选择HTML文档 </code> 标签。</p>
<p><code>/html/head/title/text()</code>: 选择前面提到的<code><title></code> 元素下面的文本内容</p>
<p><code>//td</code>: 选择所有 <code><td></code> 元素</p>
<p><code>//div[@class="mine"]</code>: 选择所有<span>包含 <code>class="mine"</code> 属性的div 标签</span>元素</p>
<p>[XPath 教程][this tutorial to learn XPath through examples][this tutorial to learn “how to think in XPath”]</p>
<p>为了方便使用 XPaths</p>
<p><strong><span>Scrapy 提供 Selector 类, 有4种方法:</span></strong></p>
<p><code><code class="xref py py-meth docutils literal" style="font-family:Consolas, 'Andale Mono WT', 'Andale Mono', 'Lucida Console', 'Lucida Sans Typewriter', 'DejaVu Sans Mono', 'Bitstream Vera Sans Mono', 'Liberation Mono', 'Nimbus Mono L', Monaco, 'Courier New', Courier, monospace;font-size:12px;border:1px solid rgb(225,228,229);color:rgb(64,64,64);font-weight:bold;background:rgb(255,255,255);"><span class="pre">xpath()</span></code></code>:返回selectors列表, 每一个select表示一个xpath参数表达式选择的节点</p>
<p><code><code class="xref py py-meth docutils literal" style="font-family:Consolas, 'Andale Mono WT', 'Andale Mono', 'Lucida Console', 'Lucida Sans Typewriter', 'DejaVu Sans Mono', 'Bitstream Vera Sans Mono', 'Liberation Mono', 'Nimbus Mono L', Monaco, 'Courier New', Courier, monospace;font-size:12px;border:1px solid rgb(225,228,229);color:rgb(64,64,64);font-weight:bold;background:rgb(255,255,255);"><span class="pre">extract()</span></code></code>:返回一个unicode字符串,该字符串为XPath选择器返回的数据</p>
<p><code><code class="xref py py-meth docutils literal" style="font-family:Consolas, 'Andale Mono WT', 'Andale Mono', 'Lucida Console', 'Lucida Sans Typewriter', 'DejaVu Sans Mono', 'Bitstream Vera Sans Mono', 'Liberation Mono', 'Nimbus Mono L', Monaco, 'Courier New', Courier, monospace;font-size:12px;border:1px solid rgb(225,228,229);color:rgb(64,64,64);font-weight:bold;background:rgb(255,255,255);"><span class="pre">re()</span></code></code>: 返回unicode字符串列表,字符串作为参数由正则表达式提取出来</p>
<p><code class="xref py py-meth docutils literal" style="font-family:Consolas, 'Andale Mono WT', 'Andale Mono', 'Lucida Console', 'Lucida Sans Typewriter', 'DejaVu Sans Mono', 'Bitstream Vera Sans Mono', 'Liberation Mono', 'Nimbus Mono L', Monaco, 'Courier New', Courier, monospace;font-size:12px;border:1px solid rgb(225,228,229);color:rgb(64,64,64);font-weight:bold;background:rgb(255,255,255);"><span class="pre">css()</span></code>: returns a list of selectors, each of which represents the nodes selected by the CSS expression given as argument</p>
<p><br></p>
<p><span style="font-size:14px;"><strong>在Shell中使用Selectors<br></strong></span>To illustrate the use of Selectors we’re going to use the built-in Scrapy shell, which also requires IPython (an extended Python console) installed on your system.<br>To start a shell, you must go to the project’s top level directory and run:<br>scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"<br></p>
<p><strong>Note</strong>: 它会启动 crawler ,把命令行指定的这个页面抓取下来,然后进入 shell ,根据提示,我们有许多现成的变量可以用,其中一个就是 <span style="font-family:'Courier New', Courier, monospace;"><span style="font-size:14.4px;line-height:20px;">hxs</span></span> ,它是一个 <span style="font-family:'Courier New', Courier, monospace;"><span style="font-size:14.4px;line-height:20px;">HtmlXPathSelector</span></span> </p>
<p>[Trying Selectors in the Shell]</p>
<p><br></p>
<h2><span><span style="font-size:14px;">spider之提取数据</span></span></h2>
<p><strong>查看要爬取的网页</strong></p>
<p>You could type response.body in the console, and inspect the source code to figure out the XPaths you need to use. However, inspecting the raw HTML code there could become a very tedious task. To make it easier, you can use Firefox Developer Tools or some Firefox extensions like Firebug. For more information see <span style="border:1px solid rgb(225,228,229);">Using Firebug for scraping</span><span style="border:1px solid rgb(225,228,229);"> and </span>Using Firefox for scraping</p>
<p><a href="http://img.e-com-net.com/image/info8/042cf66e850949f88b4c854154af3016.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/042cf66e850949f88b4c854154af3016.jpg" alt="" width="650" height="74"></a></p>
<p><strong>这是要爬取部分的html代码</strong></p>
<p></p>
<p><ul class="directory-url" style="margin-left:0;"><br> <li><br> <a href="http://www.pearsonhighered.com/educator/academic/product/0,,0130260363,00%2Ben-USS_01DBC.html" class="listinglink">Core Python Programming</a> <br> - By Wesley J. Chun; Prentice Hall PTR, 2001, ISBN 0130260363. For experienced developers to improve extant skills; professional level examples. Starts by introducing syntax, objects, error handling, functions, classes, built-ins. [Prentice Hall]<br> <div class="flag"><a href="/public/flag?cat=Computers%2FProgramming%2FLanguages%2FPython%2FBooks&url=http%3A%2F%2Fwww.pearsonhighered.com%2Feducator%2Facademic%2Fproduct%2F0%2C%2C0130260363%2C00%252Ben-USS_01DBC.html"><img src="/img/flag.png" alt="[!]" title="report an issue with this listing"></a></div><br> </li><br> <li></p>
<p> ...<br><span></span> </li><br><span></span> ...<br></ul></p>
<p><strong>审查desc部分元素还发现,这部分需要使用正则表达式来提取</strong>(里面包含很多多余字符)</p>
<p><a href="http://img.e-com-net.com/image/info8/dc021ece1379463b8a5b598a40101a00.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/dc021ece1379463b8a5b598a40101a00.jpg" alt="python爬虫 - scrapy的安装和使用_第2张图片" width="598" height="238" style="border:1px solid black;"></a><br></p>
<p><strong>Note</strong>: <ul> 标签与 <span><li></span> 标签一起使用,创建无序列表<br></p>
<p>我们可以通过如下命令选择每个在网站中的 <code><li></code> 元素:</p>
<p><span>sel.xpath(</span><span class="hljs-string">'//ul/li'</span><span>) </span></p>
<p>然后是网站描述:</p>
<p><span>sel.xpath(</span><span class="hljs-string">'//ul/li/text()'</span><span>).extract()</span></p>
<p>网站标题:</p>
<p><span>sel.xpath(</span><span class="hljs-string">'//ul/li/a/text()'</span><span>).extract()</span></p>
<p>网站链接:</p>
<p><span>sel.xpath(</span><span class="hljs-string">'//ul/li/a/@href'</span><span>).extract()</span></p>
<p>如前所述,每个 <code>xpath()</code> 调用返回一个 selectors 列表,所以我们可以结合 <code>xpath()</code> 去挖掘更深的节点。我们将会用到这些特性,所以:</p>
<pre class="hljs perl"><code class="lang-python"></code></pre>
<pre style="color:rgb(248,248,242);font-family:SimSun;font-size:10.5pt;"><span style="color:#66d9ef;"><em>for </em></span>sel <span style="color:#66d9ef;"><em>in </em></span><span style="color:#fd971f;"><em>response</em></span>.xpath(<span style="color:#e6db74;">'//ul[@class="directory-url"]/li'</span>)<span style="color:#f92672;">:</span>
<span style="color:#e6db74;">title</span> <span style="color:#f92672;">= </span>sel.xpath(<span style="color:#e6db74;">'a/text()'</span>).extract()
<span style="color:#e6db74;">link</span> <span style="color:#f92672;">= </span>sel.xpath(<span style="color:#e6db74;">'a/@href'</span>).extract()
<span style="color:#e6db74;">desc</span> <span style="color:#f92672;">= </span>sel.xpath(<span style="color:#e6db74;">'text()'</span>).re(<span style="color:#e6db74;">r'-\s(.*)\r\n'</span>)</pre>
<p><strong>Note</strong>: </p>
<p>1. 正则表达式中提取的内容为- 和回车换行中间的部分,也就是纯的desc部分。</p>
<p>2. xpath表达式中的内容也可以通过chrome浏览器F12右键得到,不过不总是很好,有时需要分析修改<a href="http://img.e-com-net.com/image/info8/33f1156e41234e5da23f9ba97ed5b7a0.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/33f1156e41234e5da23f9ba97ed5b7a0.jpg" alt="python爬虫 - scrapy的安装和使用_第3张图片" width="650" height="256" style="border:1px solid black;"></a><br></p>
<p></p>
<p>这个得到的是//*[@id="bd-cross"]/fieldset[3]/ul/li[1]/text()<br></p>
<p><br></p>
<p><code><span style="font-size:14px;"><strong>使用Item记录数据<br></strong></span></code></p>
<p><code>scrapy.Item</code> 的调用接口类似于 python 的 dict (Item objects are custom Python dicts),Item 包含多个<code>scrapy.Field</code>。这跟 django 的 Model 相似。</p>
<p>Item 通常是在 Spider 的 parse 方法里使用,它用来保存解析到的数据。</p>
<pre><code class="language-python">import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath('//ul/li'):
item = DmozItem()
item['title'] = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item</code></pre>
<p>现在,可以再次运行该项目查看运行结果。</p>
<p><br></p>
<p><span style="font-size:14px;"><strong>Following links跟踪链接</strong></span></p>
<p>爬取 Python directory目录下所有你感兴趣的链接</p>
<p></p>
<pre><code class="language-python">import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/",
]
def parse(self, response):
for href in response.css("ul.directory.dir-col > li > a::attr('href')"):
url = response.urljoin(href.extract())
yield scrapy.Request(url, callback=self.parse_dir_contents)
def parse_dir_contents(self, response):
for sel in response.xpath('//ul/li'):
item = DmozItem()
item['title'] = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item</code></pre>现在的parse()方法只是从python目录网页中抽取感兴趣的链接,通过response.urljoin()方法建立一个完整url,并在之后生成新的requests用于在后面发送,注册为callback函数的方法parse_dir_contents()最终会抓取我们要的数据。
<p></p>
<p>Here is the Scrapy’s mechanism of following links: when you yield a Request in a callback method, Scrapy will schedule that request to be sent and register a callback method to be executed when that request finishes.</p>
<p><strong><span>A common pattern</span></strong> is a callback method that extract some items, looks for a link to follow to the next page and then yields a Request with the same callback for it:</p>
<p>def parse_articles_follow_next_page(self, response):<br> for article in response.xpath("//article"):<br> item = ArticleItem()<br><br> ... extract article data here<br><br> yield item<br><br> next_page = response.css("ul.navigation > li.next-page > a::attr('href')")<br> if next_page:<br> url = response.urljoin(next_page[0].extract())<br> yield Request(url, self.parse_articles_follow_next_page)</p>
<p>This creates a sort of loop, following all the links to the next page until it doesn’t find one – handy for crawling blogs, forums and other sites with pagination.</p>
<p><strong><span>Another common pattern</span> </strong>is to build an item with data from more than one page, using a trick to pass additional data to the callbacks.</p>
<p><strong><span>一种折中的机制是在spiders中使用rules</span></strong></p>
<p>自定义的spider继承CrawlSpider</p>
<p></p>
<pre><code class="language-python">class MySpider(CrawlSpider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com']
rules = (
# Extract links matching 'category.php' (but not matching 'subsection.php')
# and follow links from them (since no callback means follow=True by default).
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
def parse_item(self, response):
self.logger.info('Hi, this is an item page! %s', response.url)
item = scrapy.Item()
item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (\d+)')
item['name'] = response.xpath('//td[@id="item_name"]/text()').extract()
item['description'] = response.xpath('//td[@id="item_description"]/text()').extract()
return item</code></pre>
<p><strong>Note</strong>: 该类并没有实现parse方法,并且规则中定义了回调函数 <code>parse_item</code></p>
<p>[CrawlSpider-Crawling rules and CrawlSpider example]</p>
<p>皮皮Blog<br></p>
<p><br></p>
<p><br></p>
<p><span><span style="font-size:24px;"><strong>保存抓取的数据</strong></span></span></p>
<p></p>
<p>保存信息的最简单的方法是通过 Feed exports,命令如下:</p>
<p>scrapy crawl dmoz -o items.json</p>
<p><span style="color:#c0c0c0;"><span class="hljs-variable">$ </span><span>scrapy crawl dmoz -o items.json -t json</span></span></p>
<p>所有抓取的 items 将以 JSON 格式被保存在新生成的 items.json 文件中。</p>
<p>除了 json 格式之外,还支持 JSON lines、CSV、XML格式,你也可以通过接口扩展一些格式。对于小项目用这种方法也足够了。如果是比较复杂的数据的话可能就需要编写一个 Item Pipeline 进行处理了。</p>
<p><span><strong><span style="font-size:14px;">使用Item Pipeline</span></strong></span></p>
<p><strong><span>激活item pipeline</span></strong></p>
<p>在 settings.py 中设置 <code>ITEM_PIPELINES</code>,其默认为<code>[]</code>,与 django 的 <code>MIDDLEWARE_CLASSES</code> 相似。从 Spider 的 parse 返回的 Item 数据将依次被 <code>ITEM_PIPELINES</code> 列表中的 Pipeline 类处理。</p>
<p><span><strong>ITEM_PIPELINES <span class="pl-k">=</span> {<span class="pl-s"><span class="pl-pds">'</span>dirbot.pipelines.FilterWordsPipeline<span class="pl-pds">'</span></span>:<span class="pl-c1">1</span>}<br></strong></span></p>
<p>Note: 后面的整数是piplines运行的顺序,items从小整数到大经过piplines,整数范围是0-1000。</p>
<p><strong><span>一个 Item Pipeline 类必须实现的方法</span></strong></p>
<p><code>process_item(item, spider)</code> 为每个 item pipeline 组件调用,并且需要返回一个 <code>scrapy.Item</code> 实例对象或者抛出一个 <code>scrapy.exceptions.DropItem</code> 异常。当抛出异常后该 item 将不会被之后的 pipeline 处理。</p>
<p>参数:<code>item (Item object)</code> – 由 parse 方法返回的 Item 对象; <code>spider (BaseSpider object)</code> – 抓取到这个 Item 对象对应的爬虫对象</p>
<p>也可额外的实现以下3个方法:</p>
<p><code>open_spider(spider):</code> 当爬虫打开之后被调用。参数: <code>spider (BaseSpider object)</code> – 已经运行的爬虫</p>
<p><code>close_spider(spider):</code> 当爬虫关闭之后被调用。参数: <code>spider (BaseSpider object)</code> – 已经关闭的爬虫<br></p>
<p>from_crawler(cls, crawler):If present, this classmethod is called to create a pipeline instance from a Crawler. It must return a new instance of the pipeline. Crawler object provides access to all Scrapy core components like settings and signals; it is a way for pipeline to access them and hook its functionality into Scrapy.</p>
<p><strong><span>几个pipline的例子</span></strong></p>
<p><strong>过滤desc中带有敏感词的item</strong></p>
<p></p>
<pre style="color:rgb(248,248,242);font-family:SimSun;font-size:10.5pt;"><span style="color:#66d9ef;"><em>class </em></span><span style="color:#a6e22e;">FilterWordsPipeline</span>(<span style="color:#66d9ef;">object</span>)<span style="color:#f92672;">:
</span><span style="color:#f92672;"> </span><span style="color:#75715e;">"""
</span><span style="color:#75715e;"> A pipeline for filtering out items which contain certain words in their description
</span><span style="color:#75715e;"> """
</span><span style="color:#75715e;">
</span><span style="color:#75715e;"> </span>words_to_filter <span style="color:#f92672;">= </span>[<span style="color:#e6db74;">'politics'</span>, <span style="color:#e6db74;">'religion'</span>]
<span style="color:#66d9ef;"><em>def </em></span><span style="color:#a6e22e;">process_item</span>(<span style="color:#fd971f;"><em>self</em></span>, <span style="color:#fd971f;"><em>item</em></span>, <span style="color:#fd971f;"><em>spider</em></span>)<span style="color:#f92672;">:
</span><span style="color:#f92672;"> </span><span style="color:#66d9ef;"><em>for </em></span>word <span style="color:#66d9ef;"><em>in </em></span><span style="color:#fd971f;"><em>self</em></span>.words_to_filter<span style="color:#f92672;">:
</span><span style="color:#f92672;"> </span><span style="color:#66d9ef;"><em>if </em></span>word <span style="color:#66d9ef;"><em>in </em></span><span style="color:#66d9ef;">unicode</span>(<span style="color:#fd971f;"><em>item</em></span>[<span style="color:#e6db74;">'description'</span>]).lower()<span style="color:#f92672;">:
</span><span style="color:#f92672;"> </span><span style="color:#66d9ef;"><em>raise </em></span>DropItem(<span style="color:#e6db74;">"Contains forbidden word: %s" </span><span style="color:#f92672;">% </span>word)
<span style="color:#66d9ef;"><em>else</em></span><span style="color:#f92672;">:
</span><span style="color:#f92672;"> </span><span style="color:#66d9ef;"><em>return </em></span><span style="color:#fd971f;"><em>item</em></span></pre>
<p></p>
<p>皮皮Blog<br></p>
<p><br></p>
<p><br></p>
<p><span style="font-size:24px;color:#FF0000;"><strong>PS:其它相关知识</strong></span><br></p>
<p><span style="font-size:14px;color:#FF0000;"><strong>Request对象相关函数和方法</strong></span></p>
<p><strong>Note</strong>: Response.body: Keep in mind that Response.body is always a str.If you want the unicode version use TextResponse.body_as_unicode().也就是说response.body已经有编码类型如utf-8了。<br></p>
<p>[request objects]<br></p>
<p><span style="color:#FF0000;"><strong><span style="font-size:14px;">Response对象<span style="font-size:14px;color:#FF0000;"><strong>相关函数和方法</strong></span></span></strong></span></p>
<p>[Response objects]<br></p>
<p><br></p>
<span style="font-size:18px;"><strong><span>定时任务</span></strong></span>
<p>如果我们不得不定期手动去执行这个脚本,那将会是很烦人的. 所有这里需要加入定时任务 .<br>定时任务将会在你指定的任何时间自动运行. 但是! 它只会在你的计算机处在运行状态时 (并不是在休眠或者关机的时候),并且特定于这段脚本需要是在和互联网处于联通状态时,才能运行. 为了不管你的计算机是出在何种状态都能运行这个定时任务, 你应该将<code>hn</code> 代码 和<code>bash</code> 脚本,还有<code>cron</code> 任务放在分开的将一直处在”运行“状态的服务器上伺服.</p>
<p><br></p>
<p><span style="font-size:18px;"><strong><span style="color:#FF0000;">相关错误解决</span></strong></span></p>
<p>scrapy ImportError: No module named settings</p>
<p>原因:爬虫根目录下不能有__init__文件,用startproject命令创建的目录是没有这个的,如果手动创建可能会创建相关文件</p>
<p>解决:将__init__文件移除就OK了<br></p>
<p>皮皮Blog<br></p>
<p><br></p>
<p><strong><span><span style="font-size:18px;">使用 BeautifulSoup进行转换&&数据存入了数据库</span></span></strong></p>
<p>[使用 Scrapy 建立一个网站抓取器]</p>
<p><span><strong>数据存入数据库</strong></span><br></p>
<p>Crawl a website with scrapy & 2 mongoDB<br>Web Scraping with Scrapy and MongoDB<br>Scrapy 轻松定制网络爬虫 - 存入python自带数据库sqlite</p>
<p><span><strong>想用爬虫下文件怎么办</strong></span></p>
<p>最好你是不要直接用scrapy默认的下载操作,对下载链接的拉取和解析应该和下载文件的处理分离开来。那么你可以自己写一个请求类,然后写一个下载中间件,中间件里维护一个进程池。在里面判断请求的类别,如果不带你定义的标记,就按照原来的默认操作,如果符合,是文件下载,就从进程池里拉出一个进程来做这件事,即使某个文件的下载失败了,你可以监控的,并且在response里表露出来的,更不会影响新的下载链接的生成何已有下载任务的执行。</p>
<p>最后中间件的问题,中间件可以包装response,这个我倒觉得对于做爬虫本身意义不是特别大,除非你的爬虫种类非常多,爬的网站也各不相同,就需要先做一点包装和处理了。</p>
<p><span style="font-size:18px;"><strong>对于动态页面怎么办</strong></span></p>
<p>我们可以自己写一个下载中间件,继承最初始的,然后利用ghost.py在里面模拟用户行为,等html改变之后再拉取。</p>
<p><span><strong>scrapy 和 javascript 交互例子</strong></span></p>
<p>用scrapy框架爬取js交互式表格数据</p>
<p>scrapy + selenium 解析javascript 实例</p>
<p><span style="font-size:18px;"><strong><span>gzip/deflate支持+多线程</span></strong><br></span></p>
<p>[使用python爬虫抓站的一些技巧总结:进阶篇]</p>
<p><strong><span><span style="font-size:14px;">更多爬虫实战文章</span></span></strong></p>
<p>Github 上实现了数据爬取的仓库:</p>
<p>https://github.com/KeithYue/Zhihu_Spider 实现先通过用户名和密码登陆再爬取数据,代码见zhihu_spider.py。</p>
<p>https://github.com/immzz/zhihu-scrapy 使用 selenium 下载和执行 javascript 代码。</p>
<p>https://github.com/tangerinewhite32/zhihu-stat-py</p>
<p>https://github.com/Zcc/zhihu 主要是爬指定话题的topanswers,还有用户个人资料,添加了登录代码。</p>
<p>用Python Requests抓取知乎用户信息</p>
<p>https://github.com/pelick/VerticleSearchEngine 基于爬取的学术资源,提供搜索、推荐、可视化、分享四块。使用了 Scrapy、MongoDB、Apache Lucene/Solr、Apache Tika等技术。</p>
<p>https://github.com/geekan/scrapy-examples scrapy的一些例子,包括获取豆瓣数据、linkedin、腾讯招聘数据等例子。</p>
<p>https://github.com/owengbs/deeplearning 实现分页获取话题。</p>
<p>https://github.com/gnemoug/distribute_crawler 使用scrapy、redis、mongodb、graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现</p>
<p>https://github.com/weizetao/spider-roach 一个分布式定向抓取集群的简单实现。</p>
<p>使用scrapy框架爬取自己的博文</p>
<p>在scrapy中怎么让Spider自动去抓取豆瓣小组页面</p>
<p>Scraping images with Python and Scrapy</p>
<p>from:http://blog.csdn.net/pipisorry/article/details/45190851<br></p>
<p>ref:Scrapy Tutorial</p>
<p>Scrap入门教程(Scrapy Tutorial中文文档)</p>
<p>[Scrapy 0.24 文档]*<br></p>
<p>官方主页: http://www.scrapy.org/</p>
<p>GitHub项目主页:https://github.com/scrapy/scrapy</p>
<p>Scrapy小解</p>
<p>使用Scrapy抓取数据</p>
<p>Python写爬虫抓站的一些技巧</p>
<p>在scrapy中怎么让Spider自动去抓取豆瓣小组页面</p>
<p>http://www.52ml.net/tags/Scrapy 收集了很多关于 Scrapy 的文章</p>
<p>Scrapy 深入一点点</p>
<p>使用scrapy写(定制)爬虫的经验,杂</p>
<p>Scrapy实用技巧<br></p>
<p><br></p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1294219321391783936"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(Python网络请求与爬虫)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1948042576535810048.htm"
title="verilator如何实现RTL的仿真(腾讯混元)" target="_blank">verilator如何实现RTL的仿真(腾讯混元)</a>
<span class="text-muted"></span>
<div>Verilator是一个用于将Verilog或SystemVerilogRTL(寄存器传输级)代码转换为C++或SystemC模型的工具,主要用于高性能的功能仿真和验证。它不是像ModelSim或VCS那样的传统事件驱动仿真器,而是通过静态编译的方式将RTL转换为可执行的C++代码,从而实现高效仿真。下面详细介绍Verilator实现RTL仿真的流程与实现细节。一、Verilator的基本工作流程</div>
</li>
<li><a href="/article/1948042574103113728.htm"
title="WebSocket断链排查与重连实战:7种实时检测与自动恢复技巧" target="_blank">WebSocket断链排查与重连实战:7种实时检测与自动恢复技巧</a>
<span class="text-muted">Clownseven</span>
<a class="tag" taget="_blank" href="/search/websocket/1.htm">websocket</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE/1.htm">网络协议</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a>
<div>更多云服务器知识,尽在hsotol.com前一秒用户还在聊着天,后一秒界面突然“连接已断开,请重试”,你赶忙看日志,发现服务并没崩,CPU正常、内存平稳,也没报错。可用户就是断了,而且还不是一个两个。这种时候你才想起来:这货不是HTTP,是WebSocket。它不是请求-响应那种你来我往,它像一根细长的管子,连上之后就一直开着,谁主动断谁才结束。可问题是——它,突然就没了。WebSocket长连接</div>
</li>
<li><a href="/article/1948042575021666304.htm"
title="AI 驱动自动化运维平台架构与实现" target="_blank">AI 驱动自动化运维平台架构与实现</a>
<span class="text-muted">大富大贵7</span>
<a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9F%A5%E8%AF%86%E5%82%A8%E5%A4%871/1.htm">程序员知识储备1</a><a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9F%A5%E8%AF%86%E5%82%A8%E5%A4%872/1.htm">程序员知识储备2</a><a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9F%A5%E8%AF%86%E5%82%A8%E5%A4%873/1.htm">程序员知识储备3</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E5%86%B3%E7%AD%96%E6%A0%91/1.htm">决策树</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a>
<div>摘要:随着云计算、容器化和大规模分布式系统的普及,传统人工运维方法已难以满足现代IT环境中海量指标、日志和拓扑关系的实时分析与故障响应需求。AI驱动的自动化运维(AIOps)平台通过融合机器学习、深度学习、图分析以及强化学习等多学科技术,实现对海量运维数据的智能感知、预测、诊断和自动化修复。本文深入探讨AI驱动自动化运维平台的整体架构设计与核心技术实现,涵盖数据采集与预处理、AI引擎设计、自动化执</div>
</li>
<li><a href="/article/1948042255822548992.htm"
title="花树一路香" target="_blank">花树一路香</a>
<span class="text-muted">王小永_6be2</span>
<div>图片发自App绽放在路旁迎送着人来车往呼吸着尾气成长历经了冬的冷雪寒霜迎来了春的和风暖阳春花烂漫一路芬芳从不羡慕花园中同伴受到的娇生惯养也从不畏惧恶劣的环境对生命的影响从小到大是一路坚强尾气猖狂灰尘飞扬污染了枝叶的模样污染不了树腔内心的洁净与高尚一边吸着尾气的肮脏一边释放着清新的氧沁人心脾一路花香图片发自App</div>
</li>
<li><a href="/article/1948040811329417216.htm"
title="第八次作业" target="_blank">第八次作业</a>
<span class="text-muted"></span>
<div>一、备份与恢复作业:创库,建表:CREATEDATABASEbooksDB;usebooksDB;CREATETABLEbooks(bk_idINTNOTNULLPRIMARYKEY,bk_titleVARCHAR(50)NOTNULL,copyrightYEARNOTNULL);CREATETABLEauthors(auth_idINTNOTNULLPRIMARYKEY,auth_nameVAR</div>
</li>
<li><a href="/article/1948039173936050176.htm"
title="python第一次作业" target="_blank">python第一次作业</a>
<span class="text-muted"></span>
<div>1.技术面试题(1)TCP与UDP的区别是什么?**答:1.TCP是面向连接的协议,而UDP是元连接的协议2.TCP协议传输是可靠的,而UDP协议的传输是“尽力而为3.TCP是可以实现流控,而UDP不行4.TCP可以实现分段,而UDP不行5.TCP的传输速率较慢,占用资源较大,UDP传输速率快,占用资源小。TCP/UDP的应用场景不同TCP适合可靠性高的效率要求低的,UDP可靠性低,效率高。(2)</div>
</li>
<li><a href="/article/1948038933711482880.htm"
title="韩式春季开衫的穿搭,休闲又时尚,是你必有的时尚单品之一" target="_blank">韩式春季开衫的穿搭,休闲又时尚,是你必有的时尚单品之一</a>
<span class="text-muted">in小巴</span>
<div>开衫这个单品不仅可以外搭而且还可以单穿,这里就要为大家介绍韩式春季的开衫穿搭以及款式。单穿起来凉爽又舒适,时尚又休闲,妳怎么可以不拥有呢!拥有无限魅力的开衫两件式,开衫与裙子都是同样的款式与颜色,就像连身裙一样的同时还散发出可爱的感觉。如果不懂要搭配哪一件下衣的话,这一套就可以解决你的苦恼了!家里只少要有一件普通的开衫,作为日常装使用也很好。搭配像是牛仔裤或是长裙,可以搭配一些较清爽的下衣都可以。</div>
</li>
<li><a href="/article/1948038417094864896.htm"
title="python" target="_blank">python</a>
<span class="text-muted">www_hhhhhhh</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a>
<div>1.技术面试题(1)解释Linux中的进程、线程和守护进程的概念,以及如何管理它们?答:进程:是操作系统进行资源分配的基本单位,拥有独立的地址空间、进程控制块,每个进程之间相互隔离。例如,打开一个终端窗口会启动一个bash进程。线程:是操作系统调度的基本单位,隶属于进程,共享进程的资源,但有独立的线程控制块和栈。线程切换开销远小于进程。例如,一个Web服务器的单个进程中,多个线程可同时处理不同客户</div>
</li>
<li><a href="/article/1948038417761759232.htm"
title="Python lambda表达式:匿名函数的适用场景与限制" target="_blank">Python lambda表达式:匿名函数的适用场景与限制</a>
<span class="text-muted">梦幻南瓜</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>目录1.Lambda表达式概述1.1Lambda表达式的基本语法1.2简单示例2.Lambda表达式的核心特点2.1匿名性2.2简洁性2.3即时性2.4函数式编程特性3.Lambda表达式的适用场景3.1作为高阶函数的参数3.2简单的数据转换3.3条件筛选3.4GUI编程中的回调函数3.5Pandas数据处理4.Lambda表达式的限制4.1只能包含单个表达式4.2没有语句4.3缺乏文档字符串4.</div>
</li>
<li><a href="/article/1948038418382516224.htm"
title="Windows 环境下 Nginx 的安装与高级配置指南" target="_blank">Windows 环境下 Nginx 的安装与高级配置指南</a>
<span class="text-muted"></span>
<div>目录第一章:Windows平台Nginx概述1.1Windows版Nginx特点1.2适用场景分析第二章:Nginx安装与配置2.1下载与安装2.2目录结构说明2.3注册为系统服务(可选)第三章:基础配置与优化3.1主配置文件优化(conf/nginx.conf)3.2虚拟主机配置示例第四章:性能优化策略4.1Windows特有优化参数4.2不同配置性能对比4.3系统参数调整第五章:安全配置5.1</div>
</li>
<li><a href="/article/1948038416444747776.htm"
title="【python】" target="_blank">【python】</a>
<span class="text-muted">www_hhhhhhh</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95/1.htm">面试</a><a class="tag" taget="_blank" href="/search/%E8%81%8C%E5%9C%BA%E5%92%8C%E5%8F%91%E5%B1%95/1.htm">职场和发展</a>
<div>1.技术面试题(1)TCP与UDP的区别是什么?答:TCP(传输控制协议)和UDP(用户数据报协议)是两种常见的传输层协议,主要区别在于连接方式和可靠性。TCP是面向连接的协议,传输数据前需建立连接,通过三次握手确保连接可靠,传输过程中有确认、重传和顺序控制机制,保证数据完整、按序到达,适用于网页浏览、文件传输等对可靠性要求高的场景。UDP是无连接的协议,无需建立连接即可发送数据,不保证数据可靠传</div>
</li>
<li><a href="/article/1948038038508597248.htm"
title="Python函数的返回值" target="_blank">Python函数的返回值</a>
<span class="text-muted"></span>
<div>1.返回值定义及案例:2.返回值与print的区别:print仅仅是打印在控制台,而return则是将return后面的部分作为返回值作为函数的输出,可以用变量接走,继续使用该返回值做其它事。3.保存函数的返回值如果一个函数return返回了一个数据,那么想要用这个数据,那么就需要保存.#定义函数defadd2num(a,b): returna+b#调用函数,顺便保存函数的返回值result=</div>
</li>
<li><a href="/article/1948037912222298112.htm"
title="python怎么把函数返回值_python函数怎么返回值" target="_blank">python怎么把函数返回值_python函数怎么返回值</a>
<span class="text-muted"></span>
<div>python函数使用return语句返回“返回值”,可以将其赋给其它变量作其它的用处。所有函数都有返回值,如果没有return语句,会隐式地调用returnNone作为返回值。python函数使用return语句返回"返回值",可以将其赋给其它变量作其它的用处。所有函数都有返回值,如果没有return语句,会隐式地调用returnNone作为返回值。一个函数可以存在多条return语句,但只有一条</div>
</li>
<li><a href="/article/1948037539197677568.htm"
title="input标签和label标签实现单选按钮" target="_blank">input标签和label标签实现单选按钮</a>
<span class="text-muted">大风过岗</span>
<div>input标签和label实现单选按钮关于label标签的使用:label可以配合input标签使用:用法:标签的for属性应当与input元素的id属性相同。例如:Malelabel标签的作用:label元素不会向用户呈现任何特殊效果。不过,它为鼠标用户改进了可用性。如果您在label元素内点击文本,就会触发此控件。就是说,当用户选择该标签时,浏览器就会自动将焦点转到和标签相关的表单控件上。</div>
</li>
<li><a href="/article/1948036526311010304.htm"
title="Python星球日记 - 第8天:函数基础" target="_blank">Python星球日记 - 第8天:函数基础</a>
<span class="text-muted">Code_流苏</span>
<a class="tag" taget="_blank" href="/search/Python%E6%98%9F%E7%90%83%E6%97%A5%E8%AE%B0/1.htm">Python星球日记</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%87%BD%E6%95%B0/1.htm">函数</a><a class="tag" taget="_blank" href="/search/def%E5%85%B3%E9%94%AE%E5%AD%97/1.htm">def关键字</a><a class="tag" taget="_blank" href="/search/%E5%87%BD%E6%95%B0%E5%8F%82%E6%95%B0/1.htm">函数参数</a><a class="tag" taget="_blank" href="/search/%E8%BF%94%E5%9B%9E%E5%80%BC/1.htm">返回值</a>
<div>引言:上一篇:Python星球日记-第7天:字典与集合名人说:路漫漫其修远兮,吾将上下而求索。——屈原《离骚》创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder)目录一、函数的定义与调用1.什么是函数?2.如何定义函数-`def`关键字3.函数调用方式二、参数与返回值1.函数参数类型2.如何传递参数3.返回值和`return`语句三、局部变量与全局变量1.变量作用域概念2.局部变</div>
</li>
<li><a href="/article/1948036400091820032.htm"
title="华为OD机试2025C卷 - 小明的幸运数 (C++ & Python & JAVA & JS & GO)" target="_blank">华为OD机试2025C卷 - 小明的幸运数 (C++ & Python & JAVA & JS & GO)</a>
<span class="text-muted">无限码力</span>
<a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAod/1.htm">华为od</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAOD%E6%9C%BA%E8%AF%952025C%E5%8D%B7/1.htm">华为OD机试2025C卷</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAOD2025C%E5%8D%B7/1.htm">华为OD2025C卷</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAOD%E6%9C%BA%E8%80%832025C%E5%8D%B7/1.htm">华为OD机考2025C卷</a>
<div>小明的幸运数华为OD机试真题目录点击查看:华为OD机试2025C卷真题题库目录|机考题库+算法考点详解华为OD机试2025C卷100分题型题目描述小明在玩一个游戏,游戏规则如下:在游戏开始前,小明站在坐标轴原点处(坐标值为0).给定一组指令和一个幸运数,每个指令都是一个整数,小明按照指令前进指定步数或者后退指定步数。前进代表朝坐标轴的正方向走,后退代表朝坐标轴的负方向走。幸运数为一个整数,如果某个</div>
</li>
<li><a href="/article/1948036136798580736.htm"
title="头条搜索极速版邀请码是多少呀?头条搜索极速版邀请码在哪里填写?" target="_blank">头条搜索极速版邀请码是多少呀?头条搜索极速版邀请码在哪里填写?</a>
<span class="text-muted">资源共享猫</span>
<div>头条搜索极速版是一款由北京微播视界科技有限公司打造的精简版软件。与抖音官方版相比,头条搜索极速版拥有更小的安装包体积,故用户可以向享受更快的软件运行速度,下载更快以及拥有更省流量的体验,全面的抖音官方短视频内容,各种创意视频智能推荐满足您的需求,趣味的社交系统,强大的美颜系统,实用的红包系统,让不少用户越来越爱它!本次小编给大家带来几个好用版本的头条搜索极速版软件,感兴趣的话,快来绿色资源网下载吧</div>
</li>
<li><a href="/article/1948035769889255424.htm"
title="Python 函数返回值" target="_blank">Python 函数返回值</a>
<span class="text-muted">落花雨时</span>
<a class="tag" taget="_blank" href="/search/Python%E5%9F%BA%E7%A1%80/1.htm">Python基础</a>
<div>#返回值,返回值就是函数执行以后返回的结果#可以通过return来指定函数的返回值#可以之间使用函数的返回值,也可以通过一个变量来接收函数的返回值defsum(*nums):#定义一个变量,来保存结果result=0#遍历元组,并将元组中的数进行累加forninnums:result+=nprint(result)#sum(123,456,789)#return后边跟什么值,函数就会返回什么值#r</div>
</li>
<li><a href="/article/1948035643288383488.htm"
title="常用 Flutter 命令大全:从开发到发布全流程总结" target="_blank">常用 Flutter 命令大全:从开发到发布全流程总结</a>
<span class="text-muted">Bryce李小白</span>
<a class="tag" taget="_blank" href="/search/flutter/1.htm">flutter</a>
<div>常用Flutter命令大全:从开发到发布全流程总结Flutter命令行工具是开发者日常工作中不可或缺的利器,涵盖了环境配置、项目管理、调试运行、构建发布等全流程操作。本文整理了开发中最常用的Flutter命令,帮助开发者提高工作效率。一、环境与配置相关命令这类命令主要用于检查和管理Flutter开发环境,确保工具链正常工作。命令功能描述flutter--version查看当前Flutter版本及D</div>
</li>
<li><a href="/article/1948035642797649920.htm"
title="Flutter基础(前端教程①⑨-margin-padding)" target="_blank">Flutter基础(前端教程①⑨-margin-padding)</a>
<span class="text-muted">aaiier</span>
<a class="tag" taget="_blank" href="/search/Flutter/1.htm">Flutter</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>比喻:把框的盒子把Container想象成一个带边框的盒子:margin是盒子外面的空白(盒子与周围其他东西的距离)。padding是盒子里面的空白(盒子边框与内部内容的距离)。代码示例(带边框更直观):Container(//盒子外部的空白(与其他组件的距离)margin:EdgeInsets.all(20),//盒子内部的空白(边框与文本的距离)padding:EdgeInsets.all(1</div>
</li>
<li><a href="/article/1948035516431659008.htm"
title="深度揭秘端口映射:原理场景、故障分析与实操工具使用,小白也能简单操作实现外网访问内网" target="_blank">深度揭秘端口映射:原理场景、故障分析与实操工具使用,小白也能简单操作实现外网访问内网</a>
<span class="text-muted"></span>
<div>端口映射:网络通信的关键技术,在网络通信领域,端口映射是一项至关重要的技术。在内部网络环境中,每一台设备都被分配了唯一的IP地址和端口号,这些标识用于在网络中精准定位和识别各个设备。然而,公共互联网的IP地址资源十分有限,不同设备可能会共享同一个公网IP地址。当需要实现内部设备的远程访问,或者搭建局域网服务器以供外部访问时,端口映射就成为了连接内外网络的关键桥梁。一、端口映射的常见应用场景1、远程</div>
</li>
<li><a href="/article/1948034254235561984.htm"
title="存档python爬虫、Web学习资料" target="_blank">存档python爬虫、Web学习资料</a>
<span class="text-muted"></span>
<div>1python爬虫学习学习Python爬虫是个不错的选择,它能够帮你高效地获取网络数据。下面为你提供系统化的学习路径和建议:1.打好基础首先要掌握Python基础知识,这是学习爬虫的前提。比如:变量、数据类型、条件语句、循环等基础语法。列表、字典等常用数据结构的操作。函数、模块和包的使用方法。文件读写操作。推荐通过阅读《Python编程:从入门到实践》这本书或者在Codecademy、LeetCo</div>
</li>
<li><a href="/article/1948033835979567104.htm"
title="0711易效能践行检视2019" target="_blank">0711易效能践行检视2019</a>
<span class="text-muted">秋天的盛开</span>
<div>石柱扶贫出差第四天,因为新工作项目特性初级阶段,所以有关工作计划都是一周为单位,但是要事都提前安排,效率有保障。白天扶贫现场指导完成产品,今天新产品改良成功,特别高兴。下班就是回归大自然,与儿子一起体验乡村生活,今天他开始结交朋友,特别高兴看到他这样的成长和适应环境的过程。这样的一天,是我喜欢的人生模式,工作生活都是良性的循环,有自己的爱好,价值,意义。与身边的人,达到和谐共生,距离刚刚好,彼此互</div>
</li>
<li><a href="/article/1948033750512234496.htm"
title="Python爬虫入门到实战(3)-对网页进行操作" target="_blank">Python爬虫入门到实战(3)-对网页进行操作</a>
<span class="text-muted">荼蘼</span>
<a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a>
<div>一.获取和操作网页元素1.获取网页中的指定元素tag_name()方法:获取元素名称。text()方法:获取元素文本内容。click()方法():点击此元素。submit()方法():提交表单。send_keys()方法:模拟输入信息。size()方法:获取元素的尺寸可进入selenium库文件夹下的webdriver\remote\webelement.py中查看更多的操作方法,2.在元素中输入</div>
</li>
<li><a href="/article/1948033077087367168.htm"
title="解封后展览(25):独角兽星空艺术馆" target="_blank">解封后展览(25):独角兽星空艺术馆</a>
<span class="text-muted">柳书岫</span>
<div>独角兽星空艺术馆和恋爱博物馆其实是一个地方,正好有空来打浦桥日月光办事,就乘电梯上去瞧了。一看,有点失望啊,感觉非常小,又破旧。进去是个小白屋,被刷得雪白,但仔细瞧,破落又脏,到处有脚印。屋内两个雪白的面对面的独角兽,还有一架雪白的吊椅,其实不能算白,已经很黑了。据说独角兽的梦,是爱与幸福的代名词,沉默而温暖的独角兽,让人深沉纯净,暂时宁静。按照标识,推开另一扇屋门,恍若走进万花筒里,万花筒呈现的</div>
</li>
<li><a href="/article/1948032869037305856.htm"
title="华为OD 机试 2025 B卷 - 周末爬山 (C++ & Python & JAVA & JS & GO)" target="_blank">华为OD 机试 2025 B卷 - 周末爬山 (C++ & Python & JAVA & JS & GO)</a>
<span class="text-muted">无限码力</span>
<a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAOD%E6%9C%BA%E8%AF%95%E7%9C%9F%E9%A2%98%E5%88%B7%E9%A2%98%E7%AC%94%E8%AE%B0/1.htm">华为OD机试真题刷题笔记</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAod/1.htm">华为od</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAOD2025B%E5%8D%B7/1.htm">华为OD2025B卷</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAOD%E6%9C%BA%E8%80%832025B%E5%8D%B7/1.htm">华为OD机考2025B卷</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAOD%E6%9C%BA%E8%AF%952025B%E5%8D%B7/1.htm">华为OD机试2025B卷</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BAOD%E6%9C%BA%E8%AF%95/1.htm">华为OD机试</a>
<div>周末爬山华为OD机试真题目录点击查看:华为OD机试2025B卷真题题库目录|机考题库+算法考点详解华为OD机试2025B卷200分题型题目描述周末小明准备去爬山锻炼,0代表平地,山的高度使用1到9来表示,小明每次爬山或下山高度只能相差k及k以内,每次只能上下左右一个方向上移动一格,小明从左上角(0,0)位置出发输入描述第一行输入mnk(空格分隔)。代表m*n的二维山地图,k为小明每次爬山或下山高度</div>
</li>
<li><a href="/article/1948032365196537856.htm"
title="Python,C++,Go开发芯片电路设计APP" target="_blank">Python,C++,Go开发芯片电路设计APP</a>
<span class="text-muted">Geeker-2025</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/c%2B%2B/1.htm">c++</a><a class="tag" taget="_blank" href="/search/golang/1.htm">golang</a>
<div>#芯片电路设计APP-Python/C++/Go综合开发方案##系统架构设计```mermaidgraphTDA[Web前端]-->B(Python设计界面)B-->C(GoAPI网关)C-->D[C++核心引擎]D-->E[硬件加速]F[数据库]-->CG[EDA工具链]-->DH[云服务]-->C```##技术栈分工|技术|应用领域|优势||------|----------|------||</div>
</li>
<li><a href="/article/1948031679985676288.htm"
title="与友打油接龙" target="_blank">与友打油接龙</a>
<span class="text-muted">清韵漫弹</span>
<div>淡然清韵子墨怡情雅趣楼,跟着博主来打油,品赏无忧阿文话,句句有趣乐悠悠。一句一心志相投,一唱一和在心头,网海茫茫知音遇,诗兴歌韵胜美酒。闲无忧:诗兴歌韵胜美酒,细细品尝是享受,深感其中乐趣多,所见略同想法有。句句有趣乐悠悠,诙谐幽默和邂逅,表达心声和意境,别看都是顺口溜。淡然清韵:别看都是顺口溜,打油接龙会挚友,虽说不曾谋友面,电波传情送问候。七月暴雨不断头,小河满来大河流。乌云滚滚蔽天日,灾难重</div>
</li>
<li><a href="/article/1948030917264076800.htm"
title="网购返佣哪个平台佣金最高?高省APP顶级邀请码佣金更高" target="_blank">网购返佣哪个平台佣金最高?高省APP顶级邀请码佣金更高</a>
<span class="text-muted">优惠券高省</span>
<div>在当今的网络购物时代,越来越多的人开始关注网购返利平台,希望通过这些平台购物的同时还能赚取一定的佣金。那么,哪个平台的佣金最高呢?下面,我将为大家介绍几个返利赚佣金的平台,并结合具体例子进行分析。高省APP高省APP是一个专业的优惠券福利折扣平台,与众多主流联盟达成合作,包括淘宝、天猫、京东、拼多多、唯品会、苏宁易购等。其内部优惠涵盖了线上和线下的吃喝玩乐衣食住行等各个方面。在高省APP中,输入官</div>
</li>
<li><a href="/article/1948030537276911616.htm"
title="给即将进入三年级的孩子们的暑期建议(2.2班)" target="_blank">给即将进入三年级的孩子们的暑期建议(2.2班)</a>
<span class="text-muted">徐老师_b38d</span>
<div>一、假期里,请提前让孩子在家里有钢笔写字第二学段与第一学段不一样,首先是用钢笔写字了。多年的三年级教学经验告诉我们,很多孩子一入学才学着用钢笔,问题相当多。但每届班级学生中,总有几位用钢笔写字,好像没有任何问题。一问便知,他们暑假两个月,爸妈就带着他(她)选择钢笔、墨水,并在家里在爸妈的指导下写了两个月了。原来如此。也许家长又会说,这是你老师的事,又把指导孩子写钢笔字推给家长了。别忙指责。请你仔细</div>
</li>
<li><a href="/article/102.htm"
title="xml解析" target="_blank">xml解析</a>
<span class="text-muted">小猪猪08</span>
<a class="tag" taget="_blank" href="/search/xml/1.htm">xml</a>
<div>1、DOM解析的步奏
准备工作:
1.创建DocumentBuilderFactory的对象
2.创建DocumentBuilder对象
3.通过DocumentBuilder对象的parse(String fileName)方法解析xml文件
4.通过Document的getElem</div>
</li>
<li><a href="/article/229.htm"
title="每个开发人员都需要了解的一个SQL技巧" target="_blank">每个开发人员都需要了解的一个SQL技巧</a>
<span class="text-muted">brotherlamp</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/linux%E8%A7%86%E9%A2%91/1.htm">linux视频</a><a class="tag" taget="_blank" href="/search/linux%E6%95%99%E7%A8%8B/1.htm">linux教程</a><a class="tag" taget="_blank" href="/search/linux%E8%87%AA%E5%AD%A6/1.htm">linux自学</a><a class="tag" taget="_blank" href="/search/linux%E8%B5%84%E6%96%99/1.htm">linux资料</a>
<div>
对于数据过滤而言CHECK约束已经算是相当不错了。然而它仍存在一些缺陷,比如说它们是应用到表上面的,但有的时候你可能希望指定一条约束,而它只在特定条件下才生效。
使用SQL标准的WITH CHECK OPTION子句就能完成这点,至少Oracle和SQL Server都实现了这个功能。下面是实现方式:
CREATE TABLE books (
id &</div>
</li>
<li><a href="/article/356.htm"
title="Quartz——CronTrigger触发器" target="_blank">Quartz——CronTrigger触发器</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/quartz/1.htm">quartz</a><a class="tag" taget="_blank" href="/search/CronTrigger/1.htm">CronTrigger</a>
<div>转载请出自出处:http://eksliang.iteye.com/blog/2208295 一.概述
CronTrigger 能够提供比 SimpleTrigger 更有具体实际意义的调度方案,调度规则基于 Cron 表达式,CronTrigger 支持日历相关的重复时间间隔(比如每月第一个周一执行),而不是简单的周期时间间隔。 二.Cron表达式介绍 1)Cron表达式规则表
Quartz</div>
</li>
<li><a href="/article/483.htm"
title="Informatica基础" target="_blank">Informatica基础</a>
<span class="text-muted">18289753290</span>
<a class="tag" taget="_blank" href="/search/Informatica/1.htm">Informatica</a><a class="tag" taget="_blank" href="/search/Monitor/1.htm">Monitor</a><a class="tag" taget="_blank" href="/search/manager/1.htm">manager</a><a class="tag" taget="_blank" href="/search/workflow/1.htm">workflow</a><a class="tag" taget="_blank" href="/search/Designer/1.htm">Designer</a>
<div>1.
1)PowerCenter Designer:设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL映射。
2)Workflow Manager:合理地实现复杂的ETL工作流,基于时间,事件的作业调度
3)Workflow Monitor:监控Workflow和Session运行情况,生成日志和报告
4)Repository Manager:</div>
</li>
<li><a href="/article/610.htm"
title="linux下为程序创建启动和关闭的的sh文件,scrapyd为例" target="_blank">linux下为程序创建启动和关闭的的sh文件,scrapyd为例</a>
<span class="text-muted">酷的飞上天空</span>
<a class="tag" taget="_blank" href="/search/scrapy/1.htm">scrapy</a>
<div>对于一些未提供service管理的程序 每次启动和关闭都要加上全部路径,想到可以做一个简单的启动和关闭控制的文件
下面以scrapy启动server为例,文件名为run.sh:
#端口号,根据此端口号确定PID
PORT=6800
#启动命令所在目录
HOME='/home/jmscra/scrapy/'
#查询出监听了PORT端口</div>
</li>
<li><a href="/article/737.htm"
title="人--自私与无私" target="_blank">人--自私与无私</a>
<span class="text-muted">永夜-极光</span>
<div> 今天上毛概课,老师提出一个问题--人是自私的还是无私的,根源是什么?
从客观的角度来看,人有自私的行为,也有无私的</div>
</li>
<li><a href="/article/864.htm"
title="Ubuntu安装NS-3 环境脚本" target="_blank">Ubuntu安装NS-3 环境脚本</a>
<span class="text-muted">随便小屋</span>
<a class="tag" taget="_blank" href="/search/ubuntu/1.htm">ubuntu</a>
<div>
将附件下载下来之后解压,将解压后的文件ns3environment.sh复制到下载目录下(其实放在哪里都可以,就是为了和我下面的命令相统一)。输入命令:
sudo ./ns3environment.sh >>result
这样系统就自动安装ns3的环境,运行的结果在result文件中,如果提示
com</div>
</li>
<li><a href="/article/991.htm"
title="创业的简单感受" target="_blank">创业的简单感受</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/%E5%88%9B%E4%B8%9A%E7%9A%84%E7%AE%80%E5%8D%95%E6%84%9F%E5%8F%97/1.htm">创业的简单感受</a>
<div>
2009年11月9日我进入a公司实习,2012年4月26日,我离开a公司,开始自己的创业之旅。
今天是2012年5月30日,我忽然很想谈谈自己创业一个月的感受。
当初离开边锋时,我就对自己说:“自己选择的路,就是跪着也要把他走完”,我也做好了心理准备,准备迎接一次次的困难。我这次走出来,不管成败</div>
</li>
<li><a href="/article/1118.htm"
title="如何经营自己的独立人脉" target="_blank">如何经营自己的独立人脉</a>
<span class="text-muted">aoyouzi</span>
<a class="tag" taget="_blank" href="/search/%E5%A6%82%E4%BD%95%E7%BB%8F%E8%90%A5%E8%87%AA%E5%B7%B1%E7%9A%84%E7%8B%AC%E7%AB%8B%E4%BA%BA%E8%84%89/1.htm">如何经营自己的独立人脉</a>
<div>独立人脉不是父母、亲戚的人脉,而是自己主动投入构造的人脉圈。“放长线,钓大鱼”,先行投入才能产生后续产出。 现在几乎做所有的事情都需要人脉。以银行柜员为例,需要拉储户,而其本质就是社会人脉,就是社交!很多人都说,人脉我不行,因为我爸不行、我妈不行、我姨不行、我舅不行……我谁谁谁都不行,怎么能建立人脉?我这里说的人脉,是你的独立人脉。 以一个普通的银行柜员</div>
</li>
<li><a href="/article/1245.htm"
title="JSP基础" target="_blank">JSP基础</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/jsp/1.htm">jsp</a><a class="tag" taget="_blank" href="/search/%E6%B3%A8%E9%87%8A/1.htm">注释</a><a class="tag" taget="_blank" href="/search/%E9%9A%90%E5%BC%8F%E5%AF%B9%E8%B1%A1/1.htm">隐式对象</a>
<div>
1,JSP语句的声明
<%! 声明 %> 声明:这个就是提供java代码声明变量、方法等的场所。
表达式 <%= 表达式 %> 这个相当于赋值,可以在页面上显示表达式的结果,
程序代码段/小型指令 <% 程序代码片段 %>
2,JSP的注释
<!-- --> </div>
</li>
<li><a href="/article/1372.htm"
title="web.xml之session-config、mime-mapping" target="_blank">web.xml之session-config、mime-mapping</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/web.xml/1.htm">web.xml</a><a class="tag" taget="_blank" href="/search/servlet/1.htm">servlet</a><a class="tag" taget="_blank" href="/search/session-config/1.htm">session-config</a><a class="tag" taget="_blank" href="/search/mime-mapping/1.htm">mime-mapping</a>
<div>session-config
1.定义:
<session-config>
<session-timeout>20</session-timeout>
</session-config>
2.作用:用于定义整个WEB站点session的有效期限,单位是分钟。
mime-mapping
1.定义:
<mime-m</div>
</li>
<li><a href="/article/1499.htm"
title="互联网开放平台(1)" target="_blank">互联网开放平台(1)</a>
<span class="text-muted">Bill_chen</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%92%E8%81%94%E7%BD%91/1.htm">互联网</a><a class="tag" taget="_blank" href="/search/qq/1.htm">qq</a><a class="tag" taget="_blank" href="/search/%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A/1.htm">新浪微博</a><a class="tag" taget="_blank" href="/search/%E7%99%BE%E5%BA%A6/1.htm">百度</a><a class="tag" taget="_blank" href="/search/%E8%85%BE%E8%AE%AF/1.htm">腾讯</a>
<div>现在各互联网公司都推出了自己的开放平台供用户创造自己的应用,互联网的开放技术欣欣向荣,自己总结如下:
1.淘宝开放平台(TOP)
网址:http://open.taobao.com/
依赖淘宝强大的电子商务数据,将淘宝内部业务数据作为API开放出去,同时将外部ISV的应用引入进来。
目前TOP的三条主线:
TOP访问网站:open.taobao.com
ISV后台:my.open.ta</div>
</li>
<li><a href="/article/1626.htm"
title="【MongoDB学习笔记九】MongoDB索引" target="_blank">【MongoDB学习笔记九】MongoDB索引</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a>
<div>索引
可以在任意列上建立索引
索引的构造和使用与传统关系型数据库几乎一样,适用于Oracle的索引优化技巧也适用于Mongodb
使用索引可以加快查询,但同时会降低修改,插入等的性能
内嵌文档照样可以建立使用索引
测试数据
var p1 = {
"name":"Jack",
"age&q</div>
</li>
<li><a href="/article/1753.htm"
title="JDBC常用API之外的总结" target="_blank">JDBC常用API之外的总结</a>
<span class="text-muted">白糖_</span>
<a class="tag" taget="_blank" href="/search/jdbc/1.htm">jdbc</a>
<div> 做JAVA的人玩JDBC肯定已经很熟练了,像DriverManager、Connection、ResultSet、Statement这些基本类大家肯定很常用啦,我不赘述那些诸如注册JDBC驱动、创建连接、获取数据集的API了,在这我介绍一些写框架时常用的API,大家共同学习吧。
ResultSetMetaData获取ResultSet对象的元数据信息
</div>
</li>
<li><a href="/article/1880.htm"
title="apache VelocityEngine使用记录" target="_blank">apache VelocityEngine使用记录</a>
<span class="text-muted">bozch</span>
<a class="tag" taget="_blank" href="/search/VelocityEngine/1.htm">VelocityEngine</a>
<div>VelocityEngine是一个模板引擎,能够基于模板生成指定的文件代码。
使用方法如下:
VelocityEngine engine = new VelocityEngine();// 定义模板引擎
Properties properties = new Properties();// 模板引擎属</div>
</li>
<li><a href="/article/2007.htm"
title="编程之美-快速找出故障机器" target="_blank">编程之美-快速找出故障机器</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B%E4%B9%8B%E7%BE%8E/1.htm">编程之美</a>
<div>
package beautyOfCoding;
import java.util.Arrays;
public class TheLostID {
/*编程之美
假设一个机器仅存储一个标号为ID的记录,假设机器总量在10亿以下且ID是小于10亿的整数,假设每份数据保存两个备份,这样就有两个机器存储了同样的数据。
1.假设在某个时间得到一个数据文件ID的列表,是</div>
</li>
<li><a href="/article/2134.htm"
title="关于Java中redirect与forward的区别" target="_blank">关于Java中redirect与forward的区别</a>
<span class="text-muted">chenbowen00</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/servlet/1.htm">servlet</a>
<div>在Servlet中两种实现:
forward方式:request.getRequestDispatcher(“/somePage.jsp”).forward(request, response);
redirect方式:response.sendRedirect(“/somePage.jsp”);
forward是服务器内部重定向,程序收到请求后重新定向到另一个程序,客户机并不知</div>
</li>
<li><a href="/article/2261.htm"
title="[信号与系统]人体最关键的两个信号节点" target="_blank">[信号与系统]人体最关键的两个信号节点</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E7%B3%BB%E7%BB%9F/1.htm">系统</a>
<div>
如果把人体看做是一个带生物磁场的导体,那么这个导体有两个很重要的节点,第一个在头部,中医的名称叫做 百汇穴, 另外一个节点在腰部,中医的名称叫做 命门
如果要保护自己的脑部磁场不受到外界有害信号的攻击,最简单的</div>
</li>
<li><a href="/article/2388.htm"
title="oracle 存储过程执行权限" target="_blank">oracle 存储过程执行权限</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E5%AD%98%E5%82%A8%E8%BF%87%E7%A8%8B/1.htm">存储过程</a><a class="tag" taget="_blank" href="/search/%E6%9D%83%E9%99%90/1.htm">权限</a><a class="tag" taget="_blank" href="/search/%E6%89%A7%E8%A1%8C%E8%80%85/1.htm">执行者</a><a class="tag" taget="_blank" href="/search/%E8%B0%83%E7%94%A8%E8%80%85/1.htm">调用者</a>
<div>在数据库系统中存储过程是必不可少的利器,存储过程是预先编译好的为实现一个复杂功能的一段Sql语句集合。它的优点我就不多说了,说一下我碰到的问题吧。我在项目开发的过程中需要用存储过程来实现一个功能,其中涉及到判断一张表是否已经建立,没有建立就由存储过程来建立这张表。
CREATE OR REPLACE PROCEDURE TestProc
IS
fla</div>
</li>
<li><a href="/article/2515.htm"
title="为mysql数据库建立索引" target="_blank">为mysql数据库建立索引</a>
<span class="text-muted">dengkane</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/%E6%80%A7%E8%83%BD/1.htm">性能</a><a class="tag" taget="_blank" href="/search/%E7%B4%A2%E5%BC%95/1.htm">索引</a>
<div>前些时候,一位颇高级的程序员居然问我什么叫做索引,令我感到十分的惊奇,我想这绝不会是沧海一粟,因为有成千上万的开发者(可能大部分是使用MySQL的)都没有受过有关数据库的正规培训,尽管他们都为客户做过一些开发,但却对如何为数据库建立适当的索引所知较少,因此我起了写一篇相关文章的念头。 最普通的情况,是为出现在where子句的字段建一个索引。为方便讲述,我们先建立一个如下的表。</div>
</li>
<li><a href="/article/2642.htm"
title="学习C语言常见误区 如何看懂一个程序 如何掌握一个程序以及几个小题目示例" target="_blank">学习C语言常见误区 如何看懂一个程序 如何掌握一个程序以及几个小题目示例</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/c/1.htm">c</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a>
<div>如果看懂一个程序,分三步
1、流程
2、每个语句的功能
3、试数
如何学习一些小算法的程序
尝试自己去编程解决它,大部分人都自己无法解决
如果解决不了就看答案
关键是把答案看懂,这个是要花很大的精力,也是我们学习的重点
看懂之后尝试自己去修改程序,并且知道修改之后程序的不同输出结果的含义
照着答案去敲
调试错误
</div>
</li>
<li><a href="/article/2769.htm"
title="centos6.3安装php5.4报错" target="_blank">centos6.3安装php5.4报错</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/centos6/1.htm">centos6</a>
<div>报错内容如下:
Resolving Dependencies
--> Running transaction check
---> Package php54w.x86_64 0:5.4.38-1.w6 will be installed
--> Processing Dependency: php54w-common(x86-64) = 5.4.38-1.w6 for </div>
</li>
<li><a href="/article/2896.htm"
title="JSONP请求" target="_blank">JSONP请求</a>
<span class="text-muted">flyer0126</span>
<a class="tag" taget="_blank" href="/search/jsonp/1.htm">jsonp</a>
<div>
使用jsonp不能发起POST请求。
It is not possible to make a JSONP POST request.
JSONP works by creating a <script> tag that executes Javascript from a different domain; it is not pos</div>
</li>
<li><a href="/article/3023.htm"
title="Spring Security(03)——核心类简介" target="_blank">Spring Security(03)——核心类简介</a>
<span class="text-muted">234390216</span>
<a class="tag" taget="_blank" href="/search/Authentication/1.htm">Authentication</a>
<div>核心类简介
目录
1.1 Authentication
1.2 SecurityContextHolder
1.3 AuthenticationManager和AuthenticationProvider
1.3.1 &nb</div>
</li>
<li><a href="/article/3150.htm"
title="在CentOS上部署JAVA服务" target="_blank">在CentOS上部署JAVA服务</a>
<span class="text-muted">java--hhf</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/jdk/1.htm">jdk</a><a class="tag" taget="_blank" href="/search/centos/1.htm">centos</a><a class="tag" taget="_blank" href="/search/Java%E6%9C%8D%E5%8A%A1/1.htm">Java服务</a>
<div> 本文将介绍如何在CentOS上运行Java Web服务,其中将包括如何搭建JAVA运行环境、如何开启端口号、如何使得服务在命令执行窗口关闭后依旧运行
第一步:卸载旧Linux自带的JDK
①查看本机JDK版本
java -version
结果如下
java version "1.6.0"</div>
</li>
<li><a href="/article/3277.htm"
title="oracle、sqlserver、mysql常用函数对比[to_char、to_number、to_date]" target="_blank">oracle、sqlserver、mysql常用函数对比[to_char、to_number、to_date]</a>
<span class="text-muted">ldzyz007</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/SQL+Server/1.htm">SQL Server</a>
<div>oracle &n</div>
</li>
<li><a href="/article/3404.htm"
title="记Protocol Oriented Programming in Swift of WWDC 2015" target="_blank">记Protocol Oriented Programming in Swift of WWDC 2015</a>
<span class="text-muted">ningandjin</span>
<a class="tag" taget="_blank" href="/search/protocol/1.htm">protocol</a><a class="tag" taget="_blank" href="/search/WWDC+2015/1.htm">WWDC 2015</a><a class="tag" taget="_blank" href="/search/Swift2.0/1.htm">Swift2.0</a>
<div>其实最先朋友让我就这个题目写篇文章的时候,我是拒绝的,因为觉得苹果就是在炒冷饭, 把已经流行了数十年的OOP中的“面向接口编程”还拿来讲,看完整个Session之后呢,虽然还是觉得在炒冷饭,但是毕竟还是加了蛋的,有些东西还是值得说说的。
通常谈到面向接口编程,其主要作用是把系统��设计和具体实现分离开,让系统的每个部分都可以在不影响别的部分的情况下,改变自身的具体实现。接口的设计就反映了系统</div>
</li>
<li><a href="/article/3531.htm"
title="搭建 CentOS 6 服务器(15) - Keepalived、HAProxy、LVS" target="_blank">搭建 CentOS 6 服务器(15) - Keepalived、HAProxy、LVS</a>
<span class="text-muted">rensanning</span>
<a class="tag" taget="_blank" href="/search/keepalived/1.htm">keepalived</a>
<div>(一)Keepalived
(1)安装
# cd /usr/local/src
# wget http://www.keepalived.org/software/keepalived-1.2.15.tar.gz
# tar zxvf keepalived-1.2.15.tar.gz
# cd keepalived-1.2.15
# ./configure
# make &a</div>
</li>
<li><a href="/article/3658.htm"
title="ORACLE数据库SCN和时间的互相转换" target="_blank">ORACLE数据库SCN和时间的互相转换</a>
<span class="text-muted">tomcat_oracle</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a>
<div>SCN(System Change Number 简称 SCN)是当Oracle数据库更新后,由DBMS自动维护去累积递增的一个数字,可以理解成ORACLE数据库的时间戳,从ORACLE 10G开始,提供了函数可以实现SCN和时间进行相互转换;
用途:在进行数据库的还原和利用数据库的闪回功能时,进行SCN和时间的转换就变的非常必要了;
操作方法: 1、通过dbms_f</div>
</li>
<li><a href="/article/3785.htm"
title="Spring MVC 方法注解拦截器" target="_blank">Spring MVC 方法注解拦截器</a>
<span class="text-muted">xp9802</span>
<a class="tag" taget="_blank" href="/search/spring+mvc/1.htm">spring mvc</a>
<div>应用场景,在方法级别对本次调用进行鉴权,如api接口中有个用户唯一标示accessToken,对于有accessToken的每次请求可以在方法加一个拦截器,获得本次请求的用户,存放到request或者session域。
python中,之前在python flask中可以使用装饰器来对方法进行预处理,进行权限处理
先看一个实例,使用@access_required拦截:
? </div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html><script data-cfasync="false" src="/cdn-cgi/scripts/5c5dd728/cloudflare-static/email-decode.min.js"></script>
