微服务相关整理
什么是微服务?
但通常而言,微服务架构是一种架构模式或者说是一种架构风格
它提倡将单一应用程序划分一组小的服务,每个服务运行在其独立的自己的进程中,服务之间互相协调、互相配合,为用户提供最终价值。服务之间采用轻量级的通信机制互相沟通(通常是基于HTTP的RESTful API)。每个服务都围绕着具体业务进行构建,并且能够被独立地部署到生产环境、类生产环境等。另外应尽量避免统一的,集中的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建,可以有一个非常轻量级的集中管理来协调这些服务,可以使用不同的语言来编写服务,也可以使用不同的数所存储。

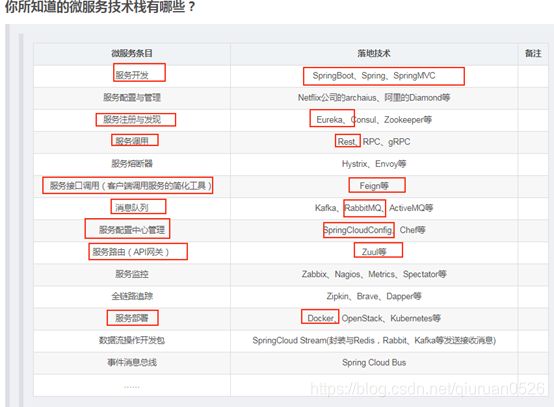
你所知道的微服务技术栈有哪些?

微服务之间是如何独立通讯的?
微服务通信方式:
1.同步:RPC,REST等
2.异步:消息队列。要考虑消息可靠传输、高性能,以及编程模型的变化等。如RabbitMQ
RPC和RESTful
RPC(即Remote Procedure Call,远程过程调用)和HTTP(HyperText Transfer Protocol,超文本传输协议)他们最本质的区别,就是RPC主要工作在TCP协议之上,而HTTP服务主要是工作在HTTP协议之上,我们都知道HTTP协议是在传输层协议TCP之上的,所以效率来看的话,RPC当然是要更胜一筹。
一般来说,RPC服务主要是针对大型企业的,而HTTP服务主要是针对小企业的,因为RPC效率更高,而HTTP服务开发迭代会更快。
流行的RPC框架
目前流行的开源RPC框架还是比较多的。下面重点介绍三种:
Dubbo是阿里集团开源的一个极为出名的RPC框架,
HTTP服务
(1)HTTP接口
相比RPC,HTTP接口开发也就是我们常说的RESTful风格的服务接口。
(2)RESTful是什么
其实RESTful绝大部分内容都是关于API设计时规范推荐的做法,并没有新东西。只要符合REST设计原则的API都可以被称为RESTful。
RESTful的核心就是后端将资源发布为URL,前端通过URL访问资源,并通过HTTP动词表示要对资源进行的操作。这里涉及到一个新概念:资源,后端提供的所有内容都可以被定义为资源。典型的RESTful如下:
GET /student //查找所有学生
GET /student/1 //查找id为1的学生
POST /student //新增一个学生
PUT /student/1 //修改id为1的学生
DELETE /student/1 //删除id为1的学生
为什么用RESTful
前后端分离主要是以API为界限进行解耦的,这就会产生大量的API,采用RESTful来设计API主要有以下好处:
1、表现力更强,更易于理解
2、RESRful是无状态,所以不管前端是何种设备何种状态都可以无差别的请求资源
怎么用RESTful
1、每个资源使用2个URL,网址中只能有名词
2、对于资源的操作类型由HTTP动词来表示
3、统一的返回结果
4、返回正确的状态码
5、允许通过HTTP内容协商,建议格式预定义为JSON
6、对可选发杂的参数,使用查询字符串(?)
7、返回有用的错误信息(message)
8、非资源请求用动词,这看起似乎和1中的说法有矛盾,但这里指的是非资源,而不是资源

![]()
RPC服务和HTTP服务还是存在很多的不同点的,一般来说,RPC服务主要是针对大型企业的,而HTTP服务主要是针对小企业的,因为RPC效率更高,而HTTP服务开发迭代会更快。总之,选用什么样的框架不是按照市场上流行什么而决定的,而是要对整个项目进行完整地评估,从而在仔细比较两种开发框架对于整个项目的影响,最后再决定什么才是最适合这个项目的。一定不要为了使用RPC而每个项目都用RPC,而是要因地制宜,具体情况具体分析。
SpringCloud和Dubbo有哪些区别?
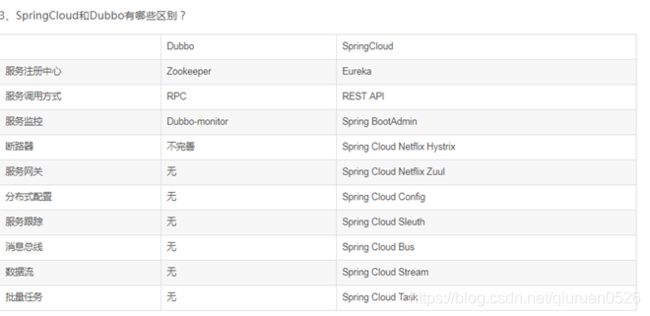
最大区别:SpringCloud抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式。
总体来说,两者各有优势。虽说后者服务调用的功能,但也避免了上面提到的原生RPC带来的问题。而且REST相比RPC更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的依赖,这在强调快速演化的微服务环境下,显得更加合适。
品牌机与组装机的区别:很明显SpringCloud比dubbo的功能更强大,覆盖面更广,而且能够与SpringFramework、SpringBoot、SpringData、SpringBatch等其他Spring项目完美融合,这些对于微服务至关重要。使用Dubbo构建的微服务架构就像组装电脑、各环节我们选择自由度高,但是最总可能会因为内存质量而影响整体,但对于高手这也就不是问题。而SpringCloud就像品牌机,在Spring Source的整合下,做了大量的兼容性测试,保证了机器拥有更高的稳定性。
在面临微服务基础框架选型时Dubbo与SpringCloud只能二选一。
SpringBoot和SpirngCloud,请谈谈对他们的理解
什么是Spring Boot
(想当年大学期间,没几个jar冲突一下都不叫搭框架)
Spring Boot就是整合了框架的框架,它让一切依赖都变得有序简单,你不用操心A.jar是什么版本,又依赖哪些版本的jar,它默认配置了很多框架的使用方式,就像 maven整合了所有的jar包,Spring Boot整合了所有的框架,第三方库的功能你拿着就能用。
Spring Boot的核心思想就是约定大于配置,一切由内定的约束来自动完成。采用 Spring Boot可以大大的简化你的开发模式,节省大部分照搬照抄的成本,通过少量的代码就能创建一个独立的,它都有对应的组件支持。
什么是Spring Cloud
Spring Cloud是一套分布式服务治理的框架,既然它是一套服务治理的框架,那么它本身不会提供具体功能性的操作,更专注于服务之间的通讯、熔断、监控等。因此就需要很多的组件来支持一套功能。
与SpringCloud区别
通俗的说,SpringBoot是构建单个服务的快速架构,比如它是全家桶中的1个汉堡,SpringCloud是关注全局的微服务协调整理治理框架,类似于组成多个服务的全家桶,桶里面不光有汉堡,还有薯条,还有番茄酱,那现在我要给汉堡加点番茄酱,它就更好吃了,意思就是SpringBoot可以配合全家桶中的这些工具组成一个强大的微服务体系,有点类似于Collection和Collections。
1)、SpringBoot专注于快速方便的开发单个个体微服务。
2)、SpringCloud是关注全局的微服务协调、整理、治理的框架,如通讯、熔断、监控等,它将SpringBoot开发的单体整合并管理起来。
3)、SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖关系。
什么是服务熔断?什么是服务降级?
CSDB博客:
https://blog.csdn.net/qq_37312838/article/details/82966209
服务熔断: 一般是某个服务故障或者是异常引起的,类似现实世界中的‘保险丝’,当某个异常条件被触发,直接熔断整个服务,而不是一直等到此服务超时。
服务降级:一般是从整体负荷考虑,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回掉,返回一个缺省值,这样做,虽然服务水平下降,但好歹,比直接挂掉要强。
服务降级处理是在客户端实现完成的,与服务端没有关系。
熔断机制:是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务降级,进而熔断该节点微服务的调用,快速返回“错误”的响应信息。当检测到该节点微服务调用响应正常后恢复调用链路。在SpringCloud框架里熔断机制通过Hystrix实现,Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内调用20次,如果失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand
服务降级:一般是从整体负荷考虑。就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。这样做,虽然水平下降,但好歹可用,比直接挂掉强。
微服务优缺点
优点:
1)、每个服务足够内聚,足够小,代码容易理解这样能聚焦一个指定的业务功能或业务需求。
2)、开发简单,开发效率提高,一个服务可能就是专一的只干一件事。
3)、微服务能够被小团队开发,这个团队可以是2到5个开发人员组成。
4)、微服务是松耦合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的。
5)、微服务能使用不同的语言开发。
6)、易于第三方集成,微服务允许容易且灵活的方式集成自动部署,通过持续集成集成工具,如Jenkins、Hudson等。
7)、微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果。无需通过合作体现价值。
8)、微服务允许你融合最新技术。
9)、微服务知识业务逻辑代码,不会和HTML和CSS其他界面组件混合。
10)、每个微服务都有自己的存储能力,可以有自己的数据库,也可以由统一的数据库。
缺点:
1)、开发人员要处理分布式系统的复杂性。
2)、系统部署依赖。
3)、服务间通讯成本。
4)、数据一致性。
5)、增加测试难度,多节点测试等情况。
6)、多服务运维难度,随着服务的增加,运维的压力也在增加。
Eureka和zookeeper都可以提供服务注册与发现的功能,请说说两个的区别?
(1)当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的信息,但不能容忍直接down掉不可用。也就是说,服务注册功能对高可用性要求比较高,但zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新选leader。问题在于,选取leader时间过长,30 ~ 120s,且选取期间zk集群都不可用,这样就会导致选取期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够恢复,但是漫长的选取时间导致的注册长期不可用是不能容忍的。
(2)Eureka保证了可用性,Eureka各个节点是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点仍然可以提供注册和查询服务。而Eureka的客户端向某个Eureka注册或发现是发生连接失败,则会自动切换到其他节点,只要有一台Eureka还在,就能保证注册服务可用,只是查到的信息可能不是最新的。除此之外,Eureka还有自我保护机制,如果在15分钟内超过85%的节点没有正常的心跳,那么Eureka就认为客户端与注册中心发生了网络故障,此时会出现以下几种情况:
①Eureka不在从注册列表中移除因为长时间没有收到心跳而应该过期的服务。
②Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上(即保证当前节点仍然可用)
③当网络稳定时,当前实例新的注册信息会被同步到其他节点。
Zookeeper保证了CP(C:一致性,P:分区容错性),Eureka保证了AP(A:高可用)
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像Zookeeper那样使整个微服务瘫痪。